
AWS makes it easy to build and scale in the cloud without managing physical infrastructure. Terraform takes that a step further by letting you define AWS infrastructure as code, so you can provision, change, and version resources safely and repeatably.
In this guide, you’ll learn how to configure the AWS provider, provision resources using Terraform’s init, plan, and apply workflow, and then level up with modules, remote state and state locking, and best practices for reliable, team-friendly deployments.
What we will cover:
What is Terraform?
Terraform is an infrastructure as code (IaC) tool that allows you to manage your infrastructure with configuration files rather than through a graphical user interface. The configuration files are plain text having the .tf extension or JSON based having the extension .tf.json. Terraform uses the HCL language to provision resources from different infrastructure providers.
Everything in Terraform happens with three simple steps:
- Initialize (terraform init) – Install the plugins Terraform needs to manage the infrastructure.
- Plan (terraform plan) – Preview the changes Terraform will make to match your configuration.
- Apply (terraform apply) – Make the planned changes.
The diagram below shows a typical Terraform workflow:

What is Terraform used for in AWS?
Terraform can be used in AWS to automate the provisioning and management of a wide range of cloud infrastructure resources. This includes:
- defining and deploying compute instances (such as EC2 instances)
- networking components (like VPCs, subnets, and security groups)
- storage solutions (such as S3 buckets and EBS volumes)
- database instances (including RDS and DynamoDB)
- serverless functions (using AWS Lambda)
- and more.
The Terraform AWS provider supports 1,600+ resource types and 640+ data sources, covering the most common AWS infrastructure use cases.
Why you should use Terraform on AWS?
There are many benefits to using Terraform with AWS, some of which are:
- Multi-cloud support — Terraform supports various cloud providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform, allowing users to manage resources across multi-cloud environments effortlessly.
- Human-readable configuration —Terraform lets you define resources and infrastructure in human-readable, declarative configuration files to manage your infrastructure’s lifecycle.
- Declarative configuration — With Terraform, you declare the desired state of your infrastructure using simple configuration .tf files. Terraform then automatically determines the actions needed to reach that state, reducing the complexity of managing infrastructure changes manually.
- State management — Terraform maintains a state file that records the current state of deployed infrastructure. This state file serves as a source of truth and helps Terraform understand what changes need to be applied to achieve the desired state, facilitating idempotent deployments and preventing drift.
- Plan and preview — Terraform’s plan and preview functionality allows you to preview the changes that will be applied to your infrastructure before actually executing them. This helps in identifying potential issues, verifying configurations, and ensuring desired outcomes.
- Automating workflows —Terraform supports the automation of infrastructure provisioning and management workflows through integration with CI/CD pipelines, helping to achieve continuous integration and delivery.
- Modularity and reusability — Terraform supports the modularization of infrastructure configurations through reusable modules. You can create custom modules or leverage existing modules from the Terraform Registry, enabling code reuse, standardization, and best practices.
- Infrastructure orchestration —Terraform facilitates the orchestration of complex infrastructure deployments by defining dependencies between resources and ensuring proper order of creation and destruction. This helps in building and managing interconnected systems easily.
- Resource graph —Terraform builds a dependency graph of your infrastructure resources, enabling efficient execution of infrastructure changes. Based on dependencies, it determines the optimal order of resource creation, updates, or deletion, ensuring safe and predictable deployments.
If you need any help managing your Terraform infrastructure, building more complex workflows based on Terraform, and managing AWS credentials per run, instead of using a static pair on your local machine, Spacelift is a fantastic tool for this. It supports Git workflows, policy as code, programmatic configuration, context sharing, drift detection, and many more great features right out of the box.
Terraform AWS example: Deploying resources using Terraform with AWS
Deploying AWS resources with Terraform showcases the power of Infrastructure as Code (IaC) to simplify and automate cloud infrastructure management. In this example, we’ll demonstrate how to use Terraform to provision, configure, and manage AWS services.
Using Terraform with AWS involves the following steps:
- Install Terraform and AWS CLI
- Create Terraform configuration files
- Configure the AWS provider block
- Create an EC2 instance resource in AWS
- Provision AWS resources
- Modify the infrastructure deployed by Terraform
- Set up AWS S3 as a remote backend
- Attach the security group
- Create a module for the EC2 instance
- Clean up
1. Install Terraform and AWS CLI
Before we begin working on AWS, ensure that the Terraform CLI is installed and your AWS credentials are configured. If you haven’t done this yet, follow these steps:
2. Create Terraform configuration files
To get started with Terraform, the first step is to tell Terraform that you will be deploying your infrastructure on AWS. We can do this by configuring the AWS cloud provider plugin.
Add the block with its name as aws in the main.tf file. Once you initialize the plugin, Terraform will use this information to take care of the rest and set up everything it needs to deploy your resources on AWS.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
Initialize your configuration
Let’s run the terraform init command to start initializing provider plugins and set up the configuration.
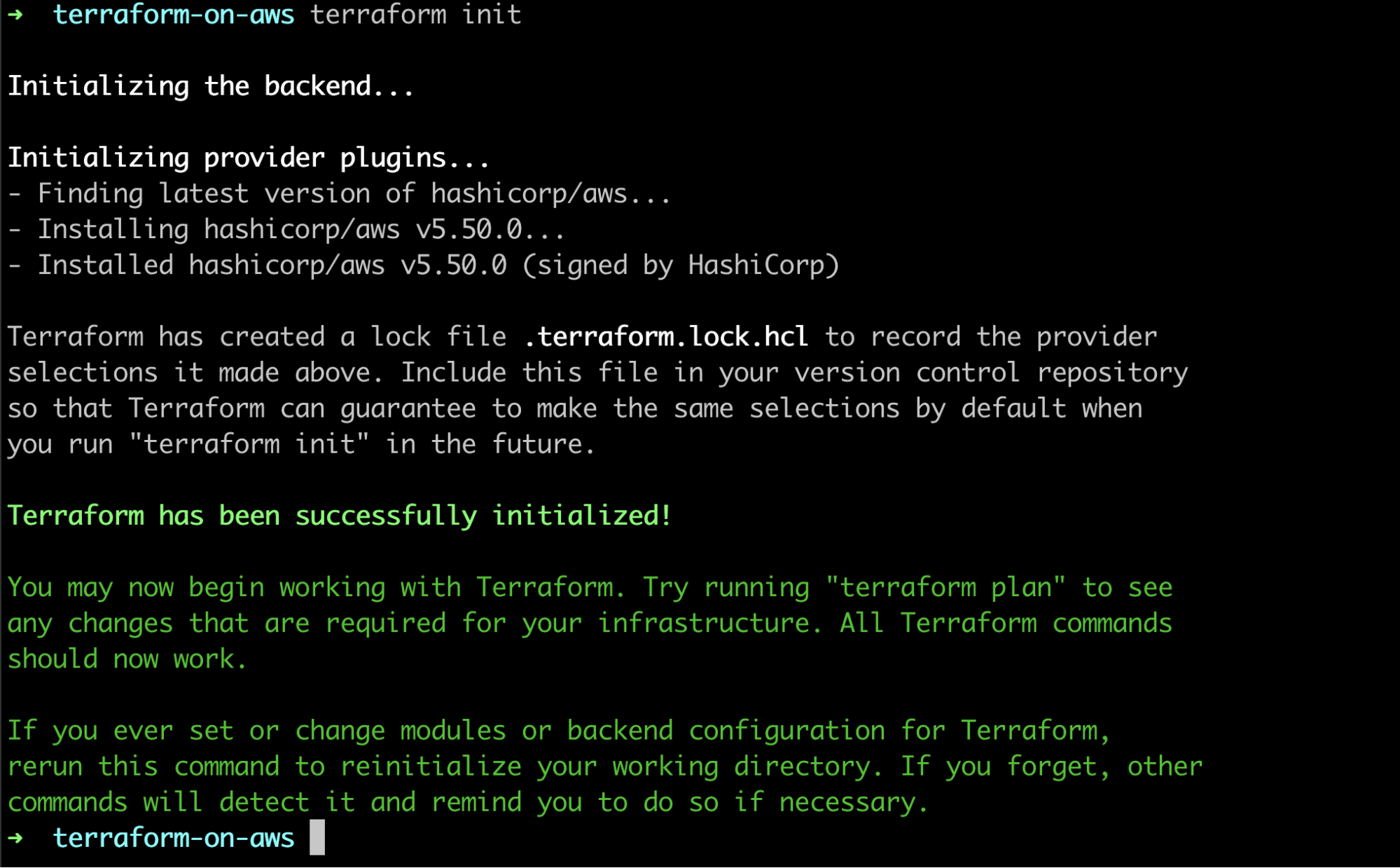
We successfully initialized our configuration. Terraform finds and installs the right plugin to successfully initialize itself.
Examine what happens when you run terraform init (Optional)
If you don’t like leaving anything to the imagination, you can explore the current directory to see what changes Terraform made.

Looks like Terraform created a new file .terraform.lock.hcl and a hidden folder .terraform.
If you open the .terraform.lock.hcl file, we will see that as the name suggests, it’s a lock file locking the version of the providers it used for deterministic initialization(same version installation) every time.
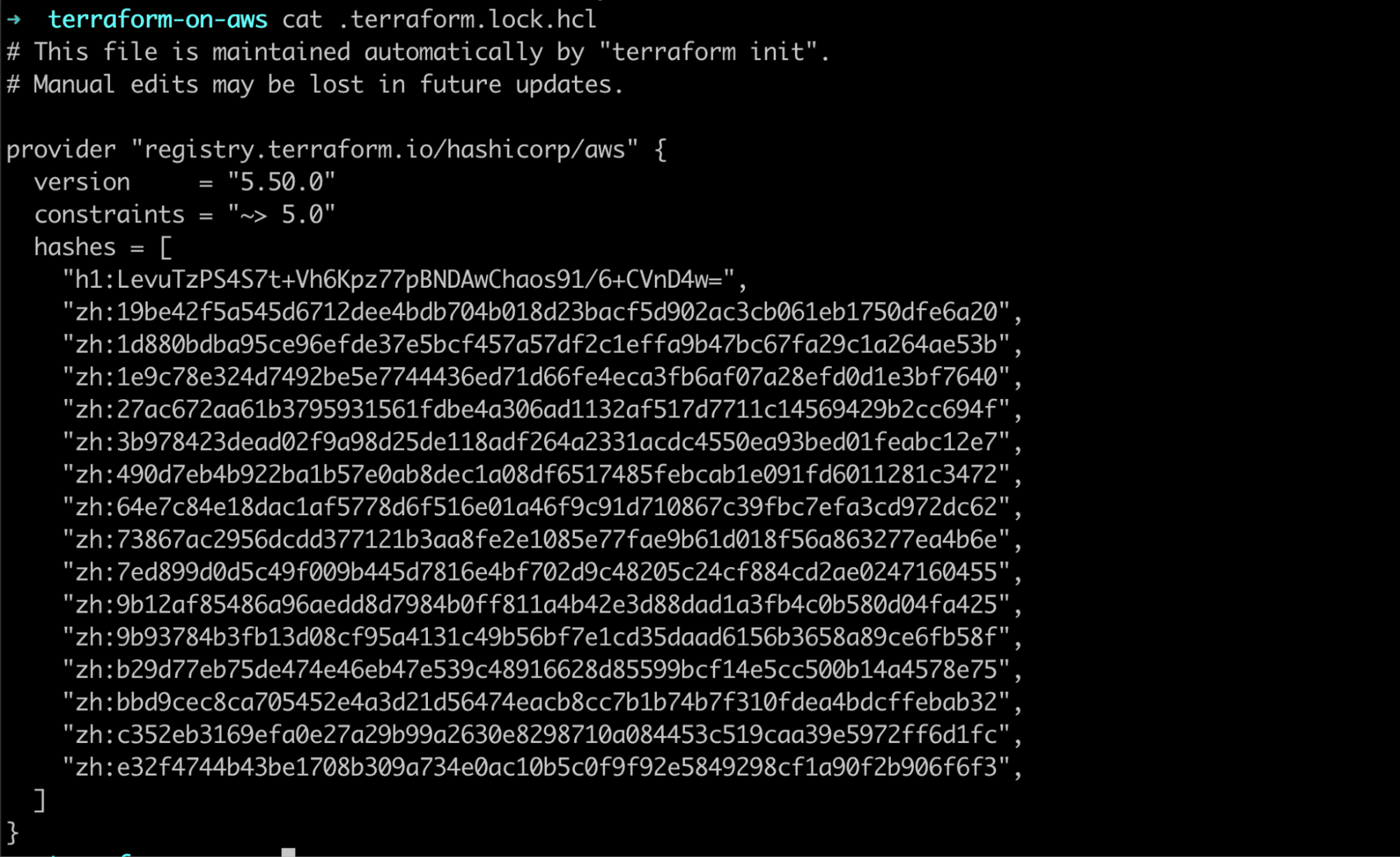
Exploring the .terraform folder, we will find that it stores the binaries of the initialized providers.
That’s it. We just demystified the mystery behind terraform init 😎
3. Configure the Terraform AWS provider block
The next step is to configure the AWS provider block, which accepts various config parameters. We will start by specifying the region to deploy the infrastructure in, us-east-1.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
# Configure the AWS Provider
provider "aws" {
region = "us-east-1"
}That’s it. We are ready to create our very first resource via Terraform.
4. Create an EC2 instance resource in AWS
The docs are your best friend when working with Terraform. The first step is to refer to the AWS provider docs page and look for the resources for the EC2 service.
It can be overwhelming to see a bunch of resources at once. But the key is to look for exactly what satisfies our use case. In our case, it is the aws_instance resource.
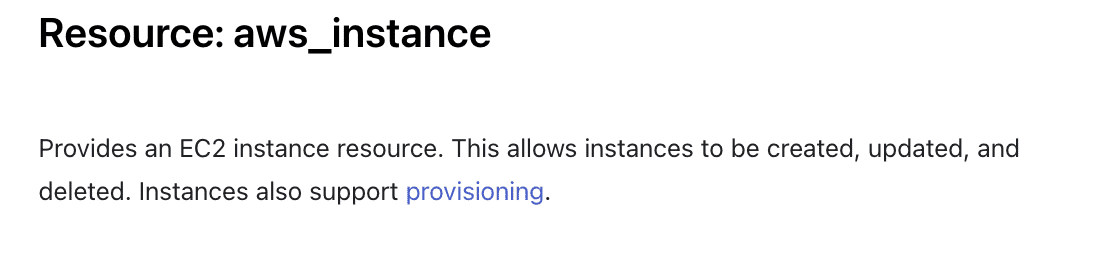
Looking at the description, it looks like we are heading in the right direction.
Again, from the docs, we know that there are two mandatory attributes to the aws_instance resource:
- ami
- Instance_type
Let’s use the Amazon Linux AMI(ami-0bb84b8ffd87024d8) and t2.micro instance type. Both are free tier eligible.
#main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
# Configure the AWS Provider
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "first_ec2_instance" {
ami = "ami-0bb84b8ffd87024d8"
instance_type = "t2.micro"
}Remember, ami and instance_type are mandatory arguments, but we can provide a lot more arguments to be more specific about how we want to deploy our EC2 instance. For example, we can specify attributes like security_groups, ipv6_addresses, and more. We will come back to this later.
5. Provision AWS resources
The next step is to review if the planned changes match our expectations.
Run Terraform commands: Plan
The terraform plan command shows a preview of the planned changes. Let’s run it and examine the changes.
➜ terraform plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_instance.web will be created
+ resource "aws_instance" "first_ec2_instance" {
+ ami = "ami-0bb84b8ffd87024d8"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_stop = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ host_resource_group_arn = (known after apply)
+ iam_instance_profile = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_lifecycle = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "t2.micro"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = (known after apply)
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ spot_instance_request_id = (known after apply)
+ subnet_id = (known after apply)
+ tags_all = (known after apply)
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.Notice that because we didn’t explicitly specify many attributes, they will be known after apply. As we discussed earlier, we can configure many of these if we want.
Run Terraform commands: Apply
Once we verify the planned changes. We will deploy the changes to AWS via the terraform apply command.
➜ terraform apply
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_instance.first_ec2_instance will be created
+ resource "aws_instance" "first_ec2_instance" {
+ ami = "ami-0bb84b8ffd87024d8"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_stop = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ host_resource_group_arn = (known after apply)
+ iam_instance_profile = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_lifecycle = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "t2.micro"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = (known after apply)
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ spot_instance_request_id = (known after apply)
+ subnet_id = (known after apply)
+ tags_all = (known after apply)
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value:Confirm the changes by typing “yes”.
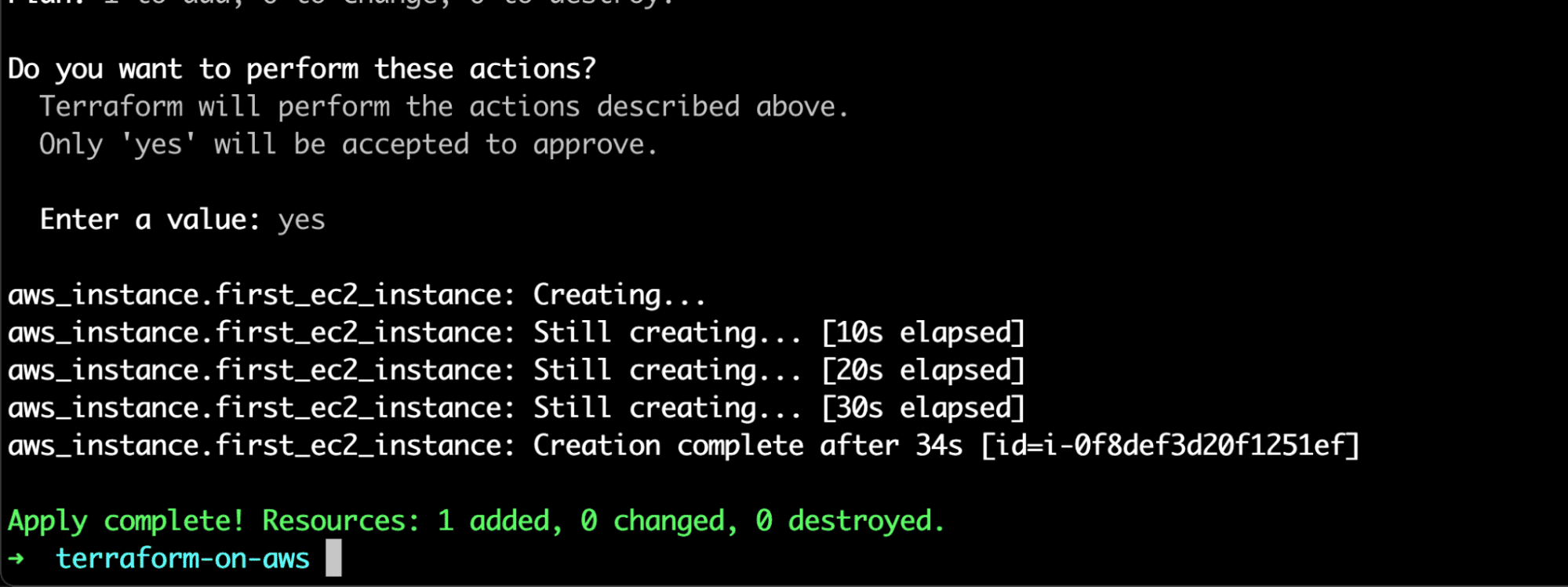
Awesome! You just created your first EC2 instance via Terraform.
6. Modify the infrastructure deployed by Terraform
Remember, we mentioned state management as one of the benefits of using Terraform. What does it really mean, though?
Let’s try running the terraform plan command again.

Interesting! Terraform seems to remember that it has already deployed this infrastructure. Let’s examine the current directory structure.
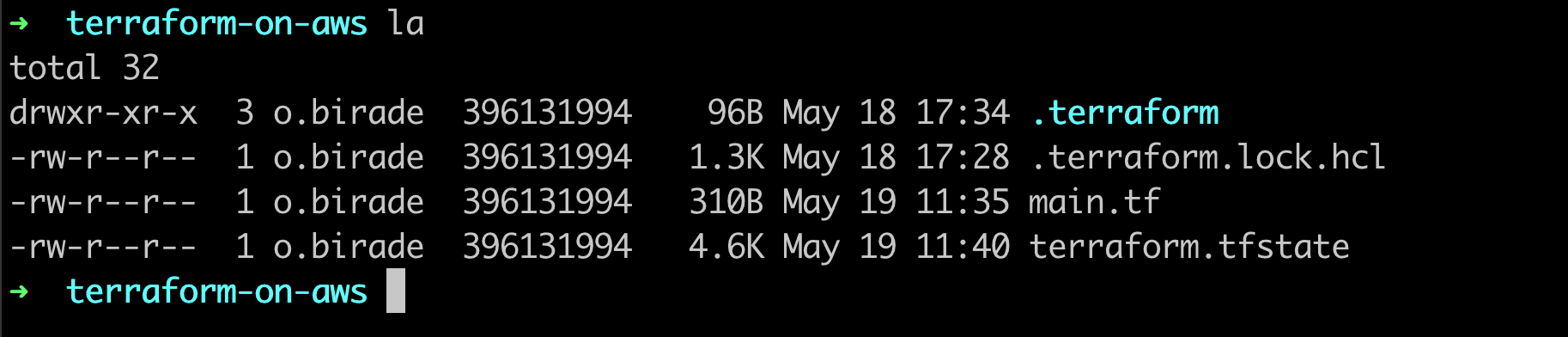
Seems like Terraform sneakily created another tf file called terraform.tfstate after we deployed our infrastructure. Let’s examine its contents.
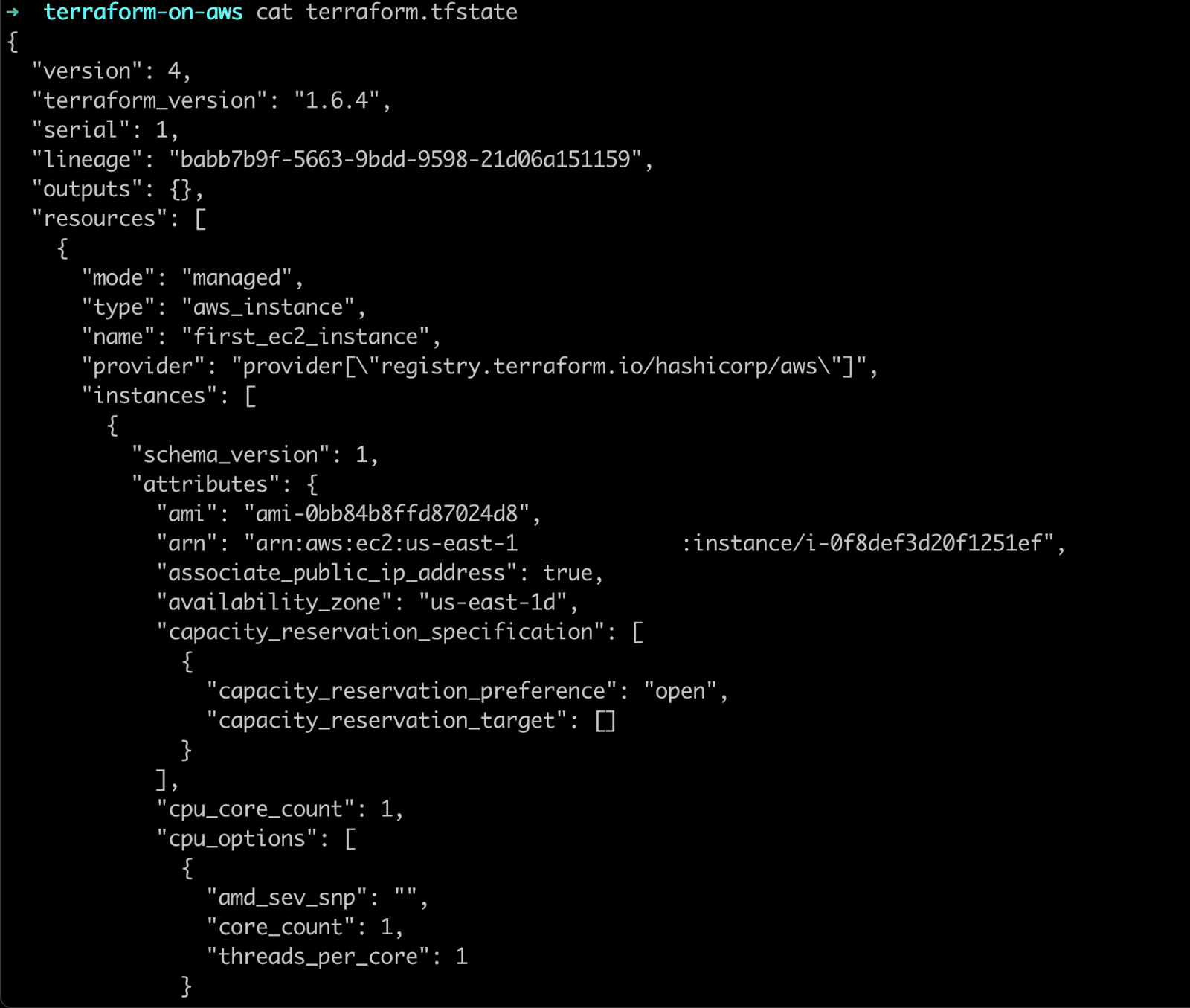
It looks like Terraform is keeping track of all resources it deployed along with their attributes.
Let’s make a small change to the EC2 machine we deployed earlier. We will add the Name tag to the AWS instance.
resource "aws_instance" "first_ec2_instance" {
ami = "ami-0bb84b8ffd87024d8"
instance_type = "t2.micro"
tags = {
Name = "My first EC2 instance"
}
}Let’s run the terraform plan command again and see what Terraform does.
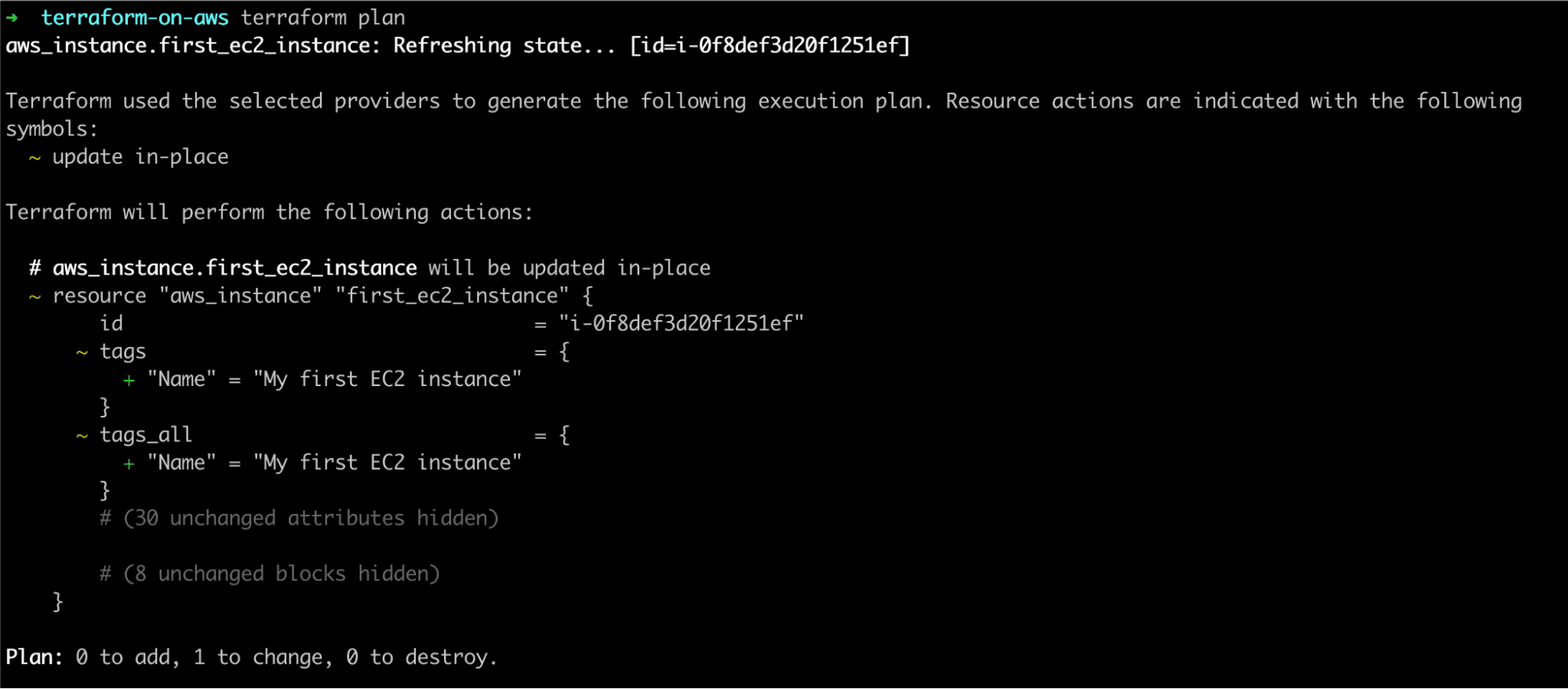
As expected, Terraform can not only detect that there is a change but also knows exactly what the change is and how to deploy it. Interestingly, it can even tell that it’s a non-destructive change (not requiring instance replacement).
Let’s apply the changes via the terraform apply command.
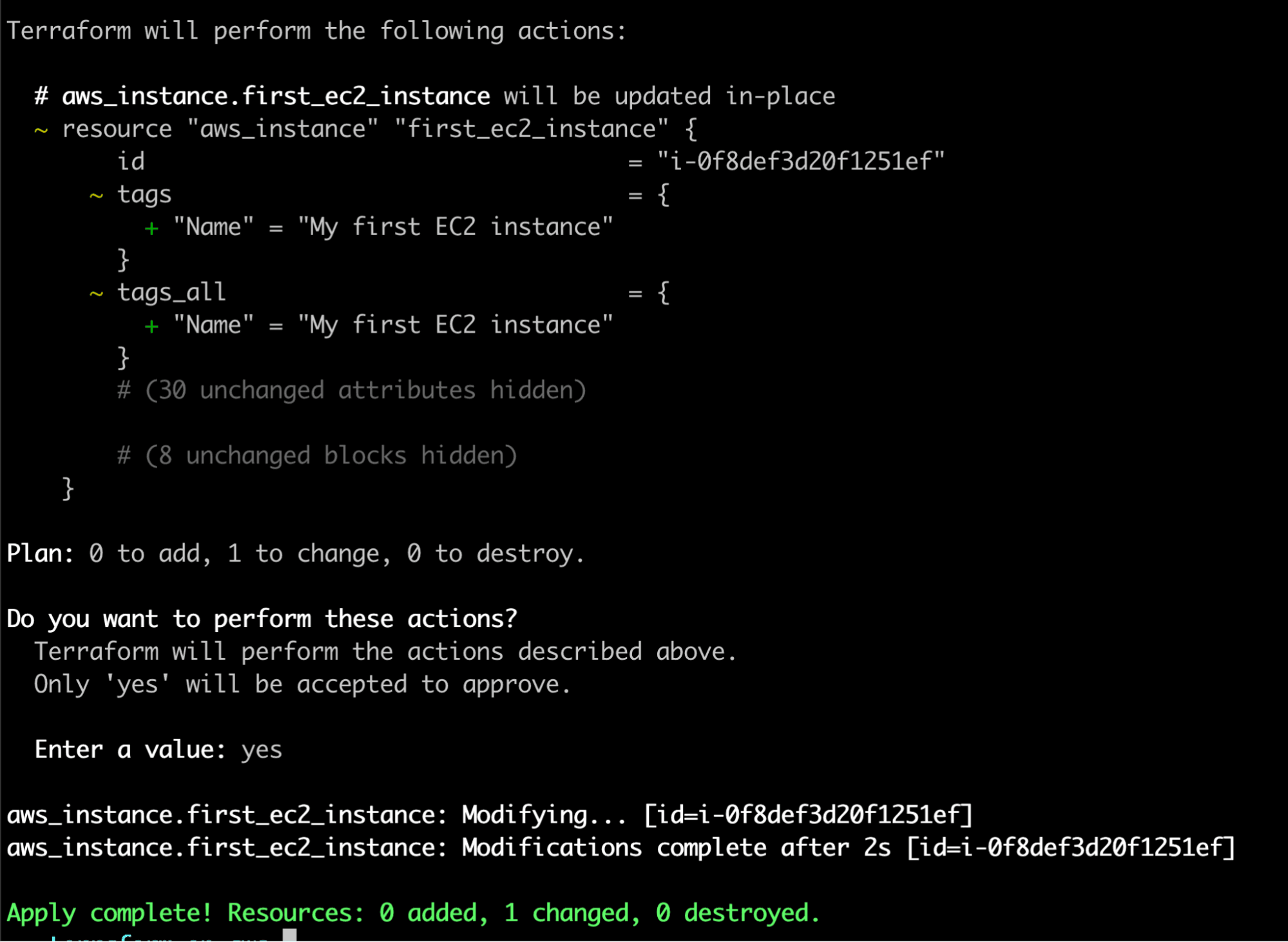

The changes are being reflected on the EC2 instance 🎉
7. Set up AWS S3 as a remote backend
Earlier, we learned that Terraform maintains a state for all changes locally. But what happens when more than one person is maintaining and changing the infrastructure or when your CI/CD pipeline is applying these changes? It’s easy to face conflicts in the state, leading to unexpected changes.
Terraform solves this problem with a feature called remote backend. A backend defines where Terraform stores its state files. We can configure the backend to host the state files remotely, centrally accessible to everyone. It is also possible to enable state locking to make sure that only a single person is allowed to make changes at a time.
Spacelift can optionally manage the Terraform state for you, offering a backend synchronized with the rest of the platform to maximize convenience and security. You also get the ability to import your state during stack creation, which is very useful for engineers who are migrating their old configurations and states to Spacelift.
There are numerous options for remote backend configuration. Since we are working with AWS, we will go with S3.
The S3 backend stores the state file in the specified Amazon S3 bucket. Optionally, we can also enable state locking and consistency checking by setting the dynamodb_table field to an existing DynamoDB table name.
To configure the remote backend, we will create a file named backend.tf. You can choose a different name for the file if you want. We will specify the bucket name to store the state file in and the key name as the name of the state file.
#backend.tf
terraform {
backend "s3" {
bucket = "spacelift-terraform-aws-state"
key = "terraform.tfstate"
region = "us-east-1"
}
}Next, we will manually create a bucket with the name spacelift-terraform-aws-state via the AWS console in the us-east-1 region.
Best practice: It is highly recommended to enable Bucket Versioning on the S3 bucket to allow for state recovery in the case of accidental deletions and human error.
Permissions: Terraform needs the following AWS IAM permissions on the target backend bucket to work properly:
s3:ListBucketonarn:aws:s3:::mybucket. At a minimum, this must be able to list the path where the state is stored.s3:GetObjectonarn:aws:s3:::mybucket/path/to/my/keys3:PutObjectonarn:aws:s3:::mybucket/path/to/my/key
The next step is to run the terraform plan again and see what happens.
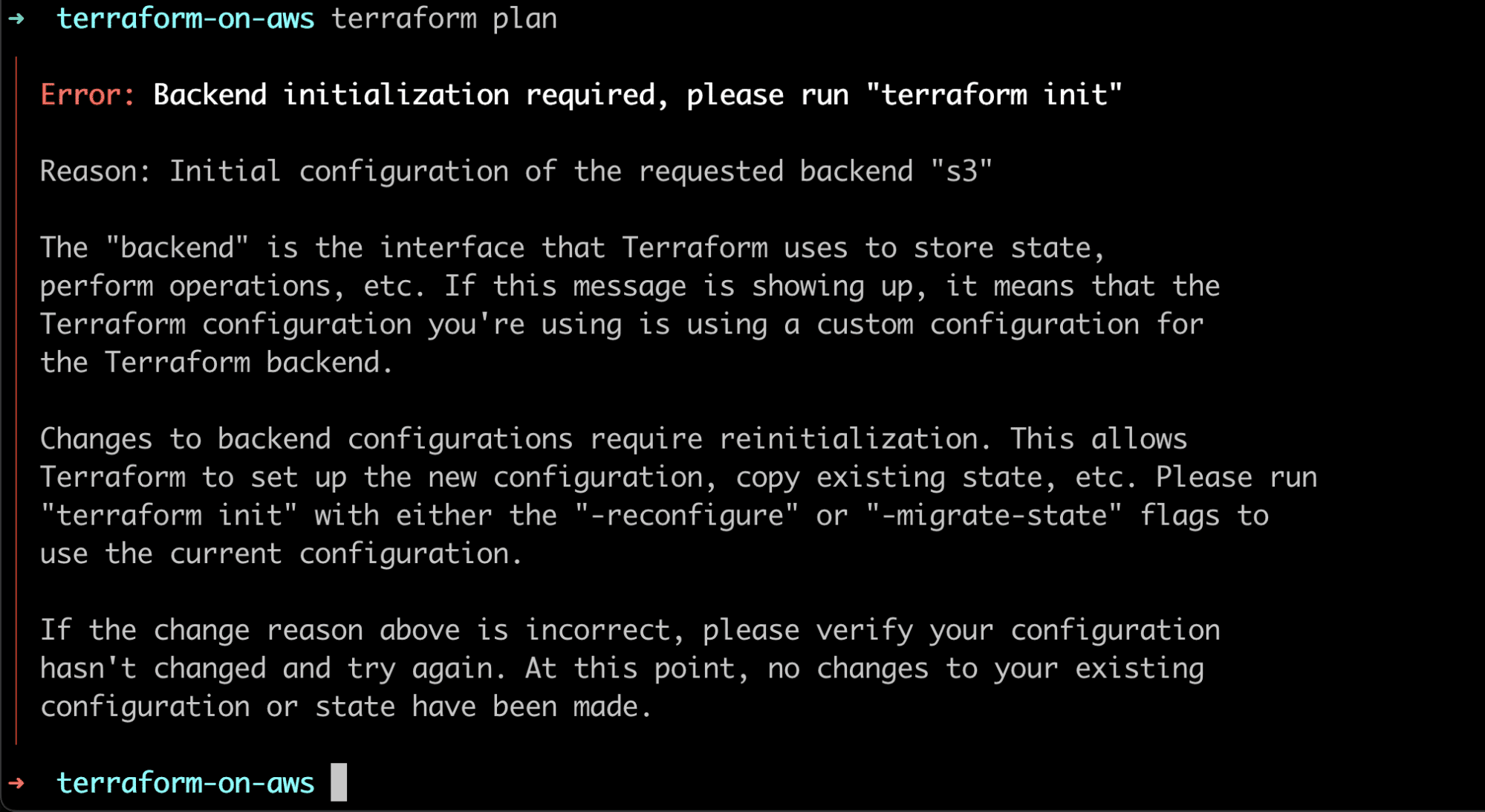
Interesting! Terraform rightly detects that there’s a change in the backend from local to s3 and informs us to re-initialize the backend.
Let’s re-initialize with the terraform init command and see what happens.

Terraform is smart enough to suggest copying the local state to our remote backend instead of re-creating the state with new resources.
Type “yes” to copy the state to the remote backend.
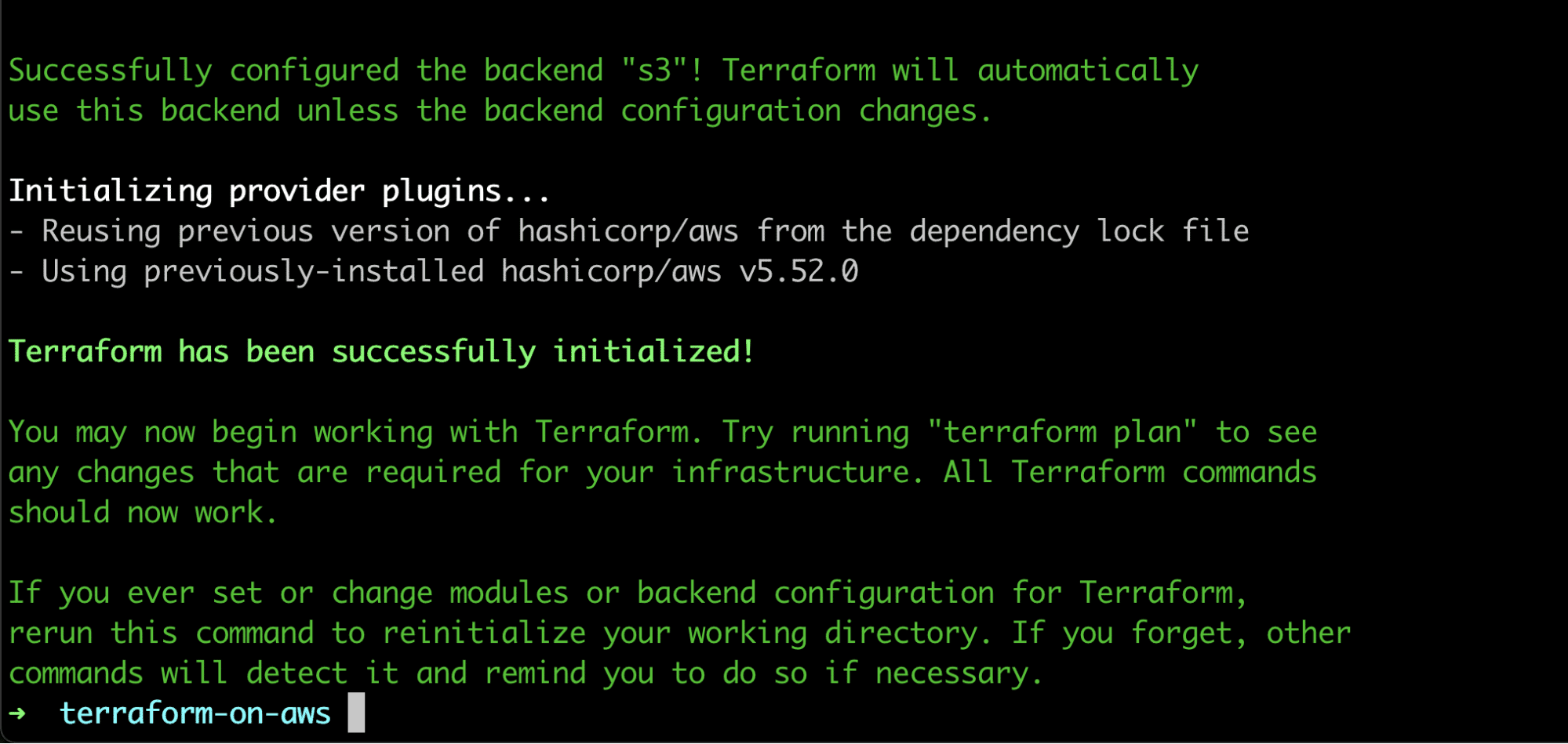
Now that our remote backend has been configured, let’s run the terraform plan command again.

The plan shows no infrastructure changes, which means things worked as expected 🙂
We successfully used Terraform to create and manage our infrastructure. In the next section, we will try to create a new security group for our EC2 instance, which refers to an existing subnet (manually created resource outside of Terraform).
8. Attach the security group
Terraform allows us to read and refer to existing resources in our configuration via data resources. We use them the same way we use any other Terraform resources, except they are data blocks instead of resource blocks.
To be able to read a subnet, we need to specify its ID.
data "aws_subnet" "private_subnet" {
id = "subnet-068ec871d50e0b521"
}Let’s run terraform plan command to see if there are any changes.

Notice that even though there are no infrastructure changes, Terraform reads the aws_subnet data resource.
We will now refer to this data resource in the new security group.
data "aws_subnet" "private_subnet" {
id = "subnet-068ec871d50e0b521"
}
resource "aws_security_group" "ec2_sg" {
vpc_id = data.aws_subnet.private_subnet.vpc_id
ingress {
cidr_blocks = [data.aws_subnet.private_subnet.cidr_block]
from_port = 80
to_port = 80
protocol = "tcp"
}
}Let’s run the terraform plan command again to review the changes.
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# aws_security_group.ec2_sg will be created
+ resource "aws_security_group" "ec2_sg" {
+ arn = (known after apply)
+ description = "Managed by Terraform"
+ egress = (known after apply)
+ id = (known after apply)
+ ingress = [
+ {
+ cidr_blocks = [
+ "172.31.16.0/20",
]
+ description = ""
+ from_port = 80
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 80
},
]
+ name = (known after apply)
+ name_prefix = (known after apply)
+ owner_id = (known after apply)
+ revoke_rules_on_delete = false
+ tags_all = (known after apply)
+ vpc_id = "vpc-00af729734190f131"
}
Plan: 1 to add, 0 to change, 0 to destroy.Notice that you can actually see the CIDR block and VPC ID, as they already exist and were read by the data block. Finally, let’s apply the changes via the terraform apply command.

The last thing remaining is to attach this security group to our EC2 machine. We can do this by referring to the security group in our EC2 resource the same way we did for the data resource.
resource "aws_instance" "first_ec2_instance" {
ami = "ami-0bb84b8ffd87024d8"
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.ec2_sg.id]
tags = {
Name = "My first EC2 instance"
}
}Let’s run the terraform plan command to review the changes.
Interesting! Terraform, again is smart enough to understand that we are only changing the security group.
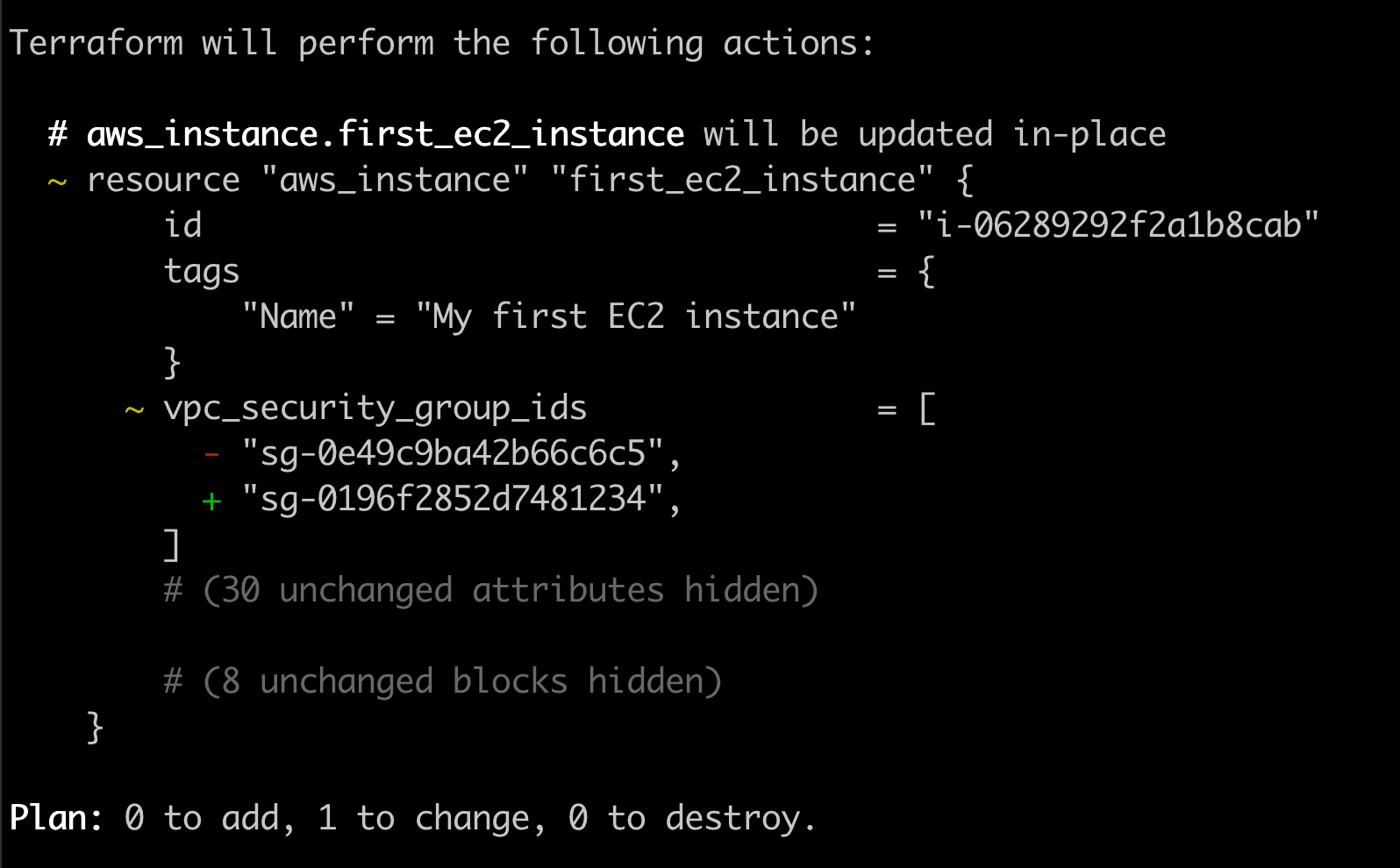
Let’s apply the changes via the terraform apply command.

Now that we are happy with the configuration we provided to our EC2 machine, how can we use this identical configuration every time to create EC2 instances? Should we copy and paste it every time?
This is where Terraform modules come into the picture.
9. Create a module for the EC2 instance
Modules are containers for multiple resources that are used together. A module consists of a collection of .tf and/or .tf.json files kept together in a directory. They are the main way to package and reuse resource configurations with Terraform.
We will start by creating a new directory named modules at the root of the folder where we will keep all our modules. Next, we will create another directory named custom-ec2 inside the module directory to store our new module.
Finally, we will create a new file named main.tf in this directory and copy and paste all resources related to the EC2 instance.
# modules/custom-ec2/main.tf
data "aws_subnet" "private_subnet" {
id = "subnet-068ec871d50e0b521"
}
resource "aws_security_group" "ec2_sg" {
vpc_id = data.aws_subnet.private_subnet.vpc_id
ingress {
cidr_blocks = [data.aws_subnet.private_subnet.cidr_block]
from_port = 80
to_port = 80
protocol = "tcp"
}
}
resource "aws_instance" "first_ec2_instance" {
ami = "ami-0bb84b8ffd87024d8"
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.ec2_sg.id]
tags = {
Name = "My first EC2 instance"
}
}That’s it. Now, we can start reusing all the code within this module simply by referring to it.
We will refer to our newly created module inside the main.tf file at the project root using the module block.
#modules/custom-ec2/main.tf
module "custom_ec2" {
source = "./modules/custom-ec2"
}Let’s run the terraform plan command to review the changes.

Terraform points out that the new module is not installed and asks us to run the terraform init command to install the new module. Let’s do that.
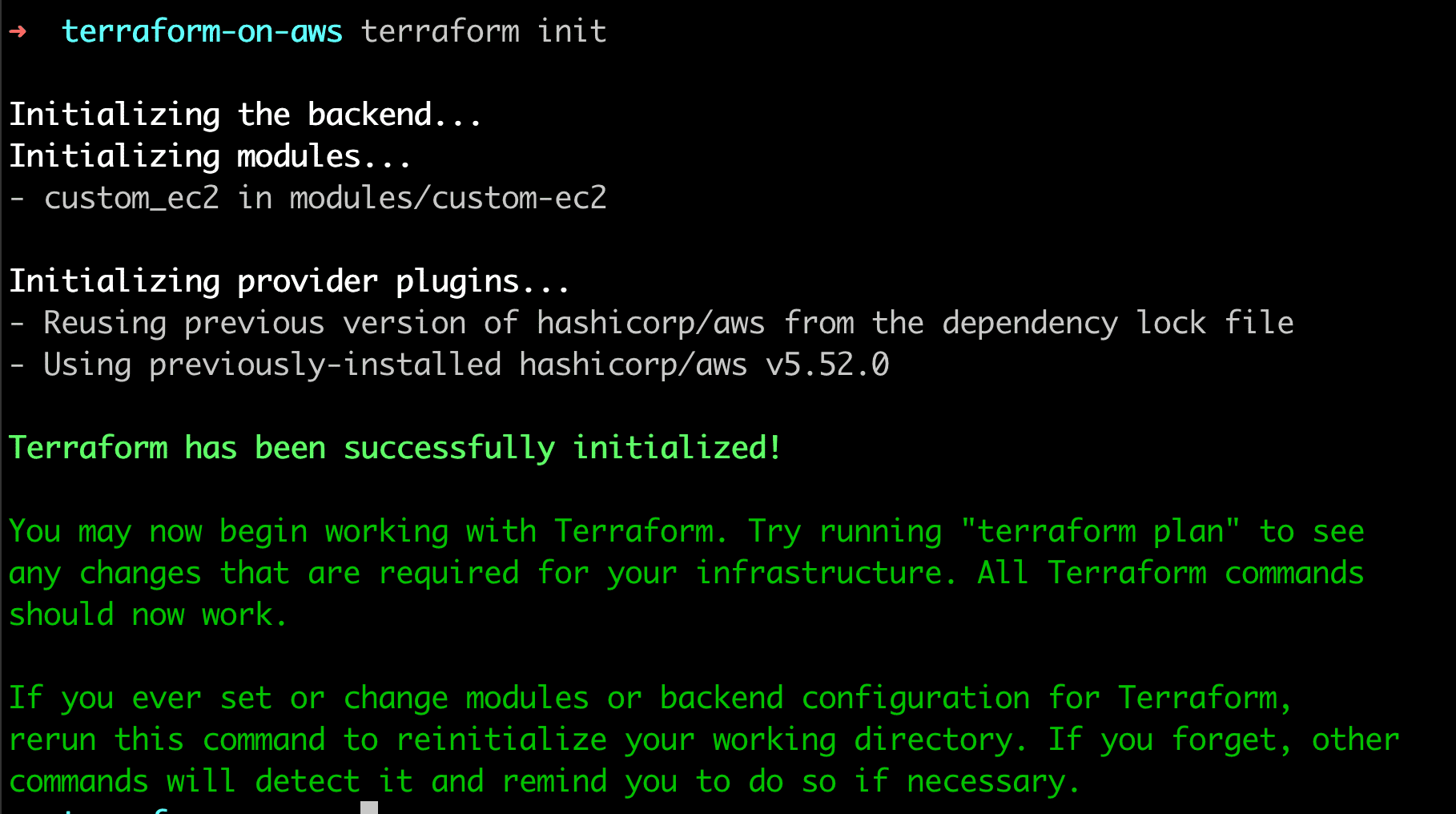
Terraform now additionally installs the referred modules in the .terraform directory. Let’s examine its contents.

Terraform created a new directory named modules containing the modules.json file. This file tracks the source and some other metadata about the modules used.
Let’s continue and run the terraform plan command to review the changes.
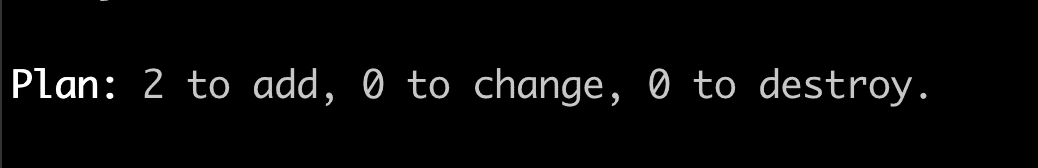
As expected, Terraform plans to create two new resources, which are a part of the custom-ec2 module we created earlier.
Modules help package all related resources together. We can use modules by simply referring to them. There are a lot of modules that we can use created by the official providers or by the Terraform community. In the next section, we will look at one of the most popular modules: terraform-aws-modules.
Terraform AWS modules
As of June 2024, terraform-aws-modules has 56 modules. We will explore one of the most popular modules: terraform-aws-modules/iam. It has numerous sub-modules, in our example, we will try using the terraform-aws-modules/iam/aws//modules/iam-user sub-module.
Let’s add it to the main.tf file.
module "iam_user" {
source = "terraform-aws-modules/iam/aws//modules/iam-user"
name = "spacelift.user"
force_destroy = true
pgp_key = "keybase:test"
password_reset_required = false
}We will re-initialize via the terraform init command so that Terraform downloads this module for use.

Next, let’s run the terraform plan command to review the changes.
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# module.iam_user.aws_iam_access_key.this[0] will be created
+ resource "aws_iam_access_key" "this" {
+ create_date = (known after apply)
+ encrypted_secret = (known after apply)
+ encrypted_ses_smtp_password_v4 = (known after apply)
+ id = (known after apply)
+ key_fingerprint = (known after apply)
+ pgp_key = "keybase:test"
+ secret = (sensitive value)
+ ses_smtp_password_v4 = (sensitive value)
+ status = "Active"
+ user = "spacelift.user"
}
# module.iam_user.aws_iam_user.this[0] will be created
+ resource "aws_iam_user" "this" {
+ arn = (known after apply)
+ force_destroy = true
+ id = (known after apply)
+ name = "spacelift.user"
+ path = "/"
+ tags_all = (known after apply)
+ unique_id = (known after apply)
}
# module.iam_user.aws_iam_user_login_profile.this[0] will be created
+ resource "aws_iam_user_login_profile" "this" {
+ encrypted_password = (known after apply)
+ id = (known after apply)
+ key_fingerprint = (known after apply)
+ password = (known after apply)
+ password_length = 20
+ password_reset_required = false
+ pgp_key = "keybase:test"
+ user = "spacelift.user"
}
Plan: 3 to add, 0 to change, 0 to destroy.We see that this module plans to create three new resources:
aws_iam_access_keyaws_iam_useraws_iam_user_login_profile
This way, we can use existing modules to create related resources easily.
10. Clean up
The final step is to clean up all the resources we just created. Just like the other things, Terraform conveniently gives us the terraform destroy command, which cleans up all resources that Terraform manages. Let’s run this command to clean up all the resources we created.

Terraform prompts us that it is managing two resources and plans to destroy them. We will confirm that we want to destroy the resources by typing “yes”.
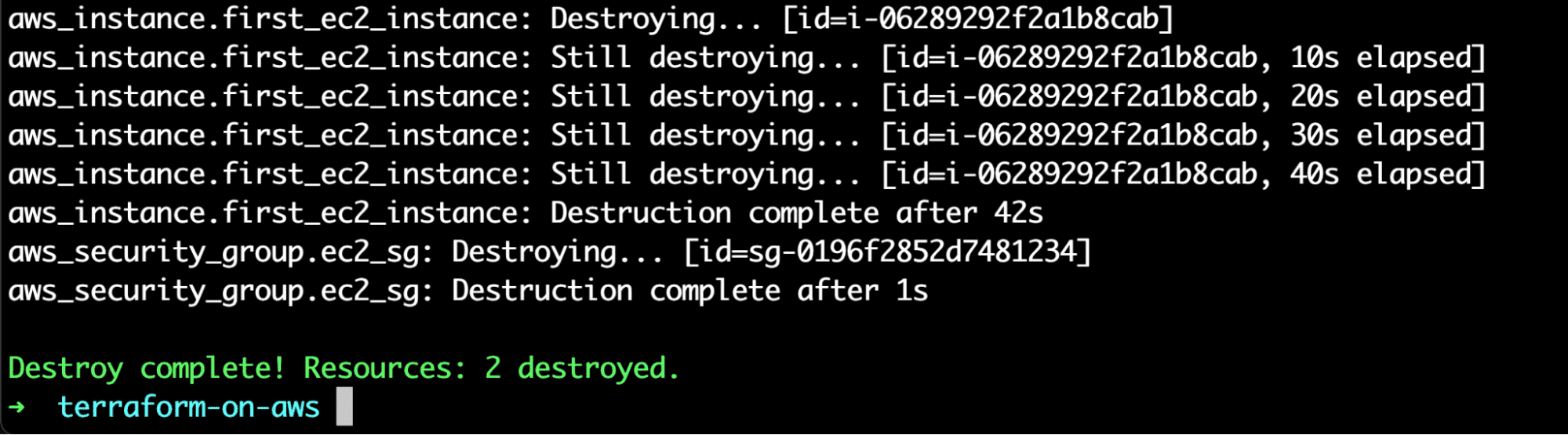
Great! We successfully cleaned up all the resources we created 🎉
Note: Remember to delete the S3 bucket we created for state management manually. Terraform won’t destroy it as it was not managed by Terraform but created manually.
Now that we have already learned how to deploy and manage our infrastructure via Terraform, let’s look at some best practices.
Best practices for AWS and Terraform
Following foundational AWS and Terraform best practices ensures security, maintainability, and efficiency. Here are the most important ones:
| Terraform AWS best practices | |
| State management |
|
| Version control |
|
| Module usage |
|
| Environment management |
|
| Security best practices |
|
| Code quality |
|
| Plan and apply practices |
|
Read more: 20 Terraform best practices to improve your workflow
Managing Terraform with Spacelift
Terraform is really powerful, but to achieve an end-to-end secure GitOps approach, you need a platform that can orchestrate your Terraform workflows.
Spacelift is the infrastructure orchestration platform built for the AI-accelerated software era. It manages the full lifecycle for both traditional infrastructure as code (IaC) and AI-provisioned infrastructure, giving you access to a powerful CI/CD workflow and unlocking features such as:
- Policies (based on Open Policy Agent) – You can control how many approvals you need for runs, what kind of resources you can create, and what kind of parameters these resources can have, and you can also control the behavior when a pull request is open or merged.
- Multi-IaC workflows – Combine Terraform with Kubernetes, Ansible, and other IaC tools such as OpenTofu, Pulumi, and CloudFormation, create dependencies among them, and share outputs.
- Build self-service infrastructure – You can use Templates and Blueprints to build self-service infrastructure; simply complete a form to provision infrastructure based on Terraform and other supported tools.
- AI-powered provisioning and diagnostics – Spacelift Intelligence adds an AI-powered layer for natural language provisioning, diagnostics, and operational insight across your infrastructure workflows.
- Integrations with any third-party tools – You can integrate with your favorite third-party tools and even build policies for them. For example, see how to integrate security tools in your workflows using Custom Inputs.
Spacelift enables you to create private workers inside your infrastructure, which helps you execute Spacelift-related workflows on your end. Read the documentation for more information on configuring private workers.
You can check it for free by creating a trial account or requesting a demo with one of our engineers.
Add a name for the stack, and optionally, you can add labels and a description.
In the Integrate VCS tab, choose your VCS provider, select the repository that you gave access to Spacelift in the first step and select a branch that you want to be attached with your Stack. You also have the optional choice of selecting a project root.
Click Continue to configure the backend.
In the configure backend tab, you can select the backend (in our case, Terraform), the Terraform version, whether Spacelift manages your state, and whether you want smart sanitization enabled.
Select Create & continue, and let’s leave everything else as a default.
Click on Trigger to kick start a Spacelift run that will check out the source code, run terraform commands on it, and then present you with an option to apply (confirm) these changes.
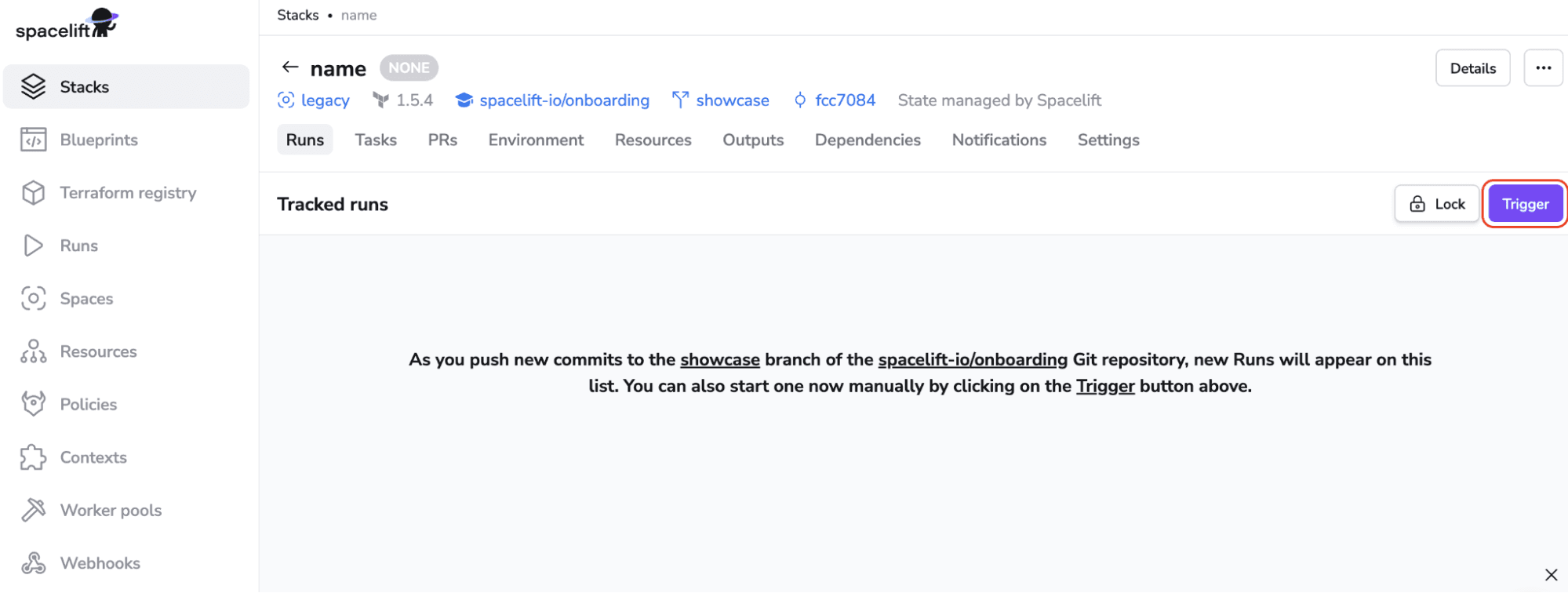
After clicking Trigger, you will be taken directly into the run. Click on Confirm, and your changes will be applied. Your output will look different based on your code repository and the resources it creates.
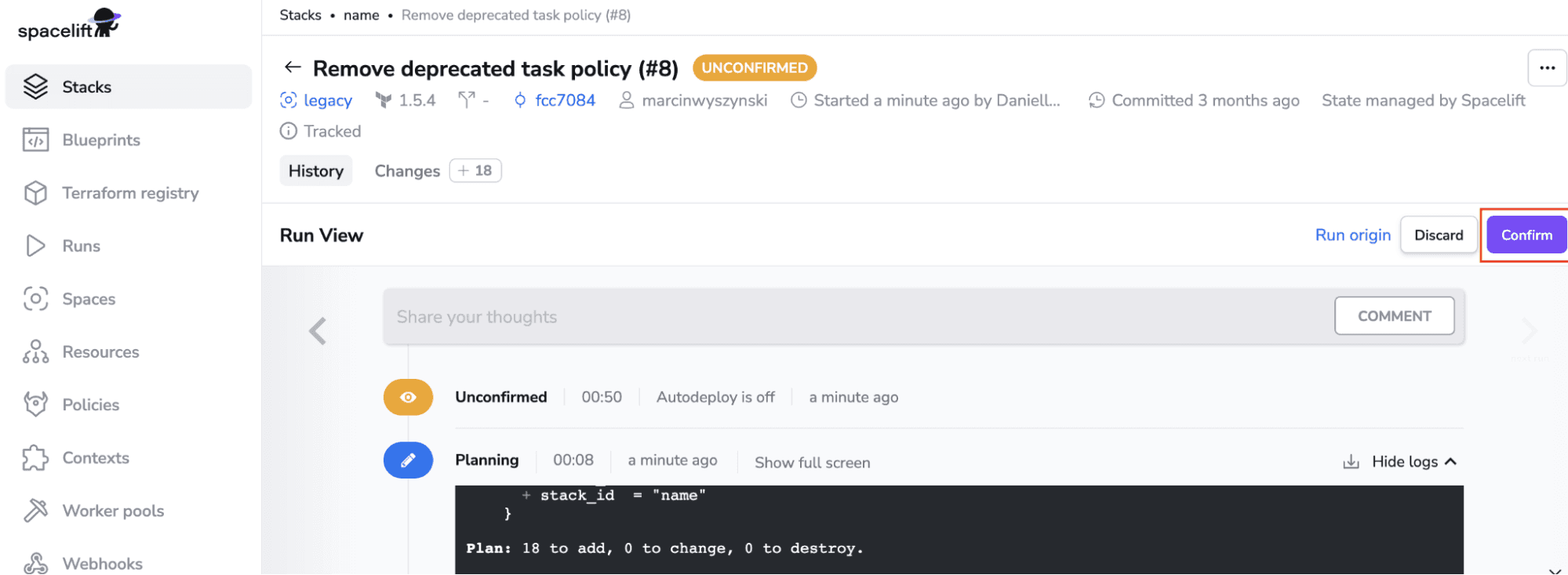
The workflow can be easily extended each step of the way by either adding commands before and after phases, changing the runner image, integrating security tools, adding policies, and others.
If you want to learn more about Spacelift, create a free account today, or book a demo with one of our engineers.
Key points
In this article, we explored the powerful duo of Terraform and AWS used to deploy and manage cloud infrastructure. We introduced Terraform, highlighted its key functions on AWS, and discussed the advantages of using Terraform’s Infrastructure as Code (IaC) approach for consistent and scalable deployments. We also covered the Terraform AWS modules available in the Registry and provided a practical example of resource configuration, deploying an EC2 instance, setting up S3 as a remote backend, and best practices for effective use.
By leveraging Terraform on AWS, you can streamline your cloud infrastructure management and automate, scale, and manage your cloud resources efficiently, achieving greater agility, cost savings, and operational excellence.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Manage Terraform better with Spacelift
Orchestrate Terraform workflows with policy as code, programmatic configuration, context sharing, drift detection, resource visualization, and more.
Frequently asked questions
Is Terraform free to use with AWS?
Terraform CLI is source-available under the Business Source License 1.1 for recent versions. There is no extra fee for using the AWS provider, but you pay AWS for provisioned resources. Terraform Cloud or Enterprise can add costs.
How does Terraform compare to other AWS infrastructure management tools?
Terraform offers cloud-agnostic infrastructure as code, making it well-suited for managing multi-cloud or hybrid environments. Compared to AWS-native tools like CloudFormation, Terraform provides a more flexible syntax (HCL), a larger provider ecosystem, and a consistent workflow across platforms. CloudFormation integrates more deeply with AWS features, including drift detection and stack policies, but is limited to AWS and has a steeper learning curve for complex stacks.
Do I need the AWS CLI to use Terraform with AWS?
No. Terraform can authenticate without the AWS CLI. But the AWS CLI is a convenient way to set up profiles, SSO, and validate credentials quickly.
How do I authenticate Terraform to AWS?
Terraform authenticates to AWS via the AWS provider, which uses the same credential resolution chain as the AWS SDK. In practice, you typically use one of three patterns: AWS SSO/Identity Center, short lived role assumption, or standard access keys, and you should prefer ephemeral credentials over long lived keys.
What’s the recommended way to manage Terraform state on AWS?
Use a remote backend (commonly S3) so teams/CI share one source of truth. Enable bucket versioning and encryption, and avoid keeping state only on a developer laptop.
