
When you run Terraform locally, state is stored in a file on your machine. That works fine in isolation, but the moment a second person joins the project, it becomes a liability. State files can get out of sync, overwritten, or accidentally committed to version control alongside sensitive credentials.
A remote backend solves this by storing state in a shared, centralized location with built-in locking to prevent concurrent writes. AWS S3 is one of the most widely used options for this: it’s reliable, cost-effective, integrates naturally with IAM for access control, and pairs with DynamoDB for state locking.
In this guide, we’ll walk through configuring S3 as your Terraform backend, migrating your existing state, and following best practices to keep your setup secure and production-ready.
Why do we need a remote backend?
When working with Terraform locally, the state files are created in the project’s root directory. This is known as the local backend and is the default.
These files cannot be part of the Git repository, as each member may run their own Terraform configuration and modify the state files. Thus, there is a high chance of corrupting the state file or at least creating inconsistencies in the state files, which is equally dangerous. Managing state files in a remote Git repository is also discouraged, as they may contain sensitive information such as credentials.
Check out our Terraform at Scale Best Practices article to learn how to scale your Terraform projects.
Terraform backend core features
Although every Terraform backend may offer platform-specific features, here are the two main features we look for:
Secure storage
State files need to be stored in a secured and remote location. Multiple developers working on the same set of Terraform configuration files can use validation access in their workflow with a remote location, avoiding the need to maintain multiple copies of state files simultaneously and handle them manually.
These state files can contain sensitive information and will be accessed multiple times, so we need to ensure the storage solution is secure against attacks and that the files’ integrity is maintained. Corrupted state files can incur high infrastructure costs.
File storage solutions like AWS S3 offer a secure and reliable way to store and access files within and outside the internal network.
Locking
Continuing with the integrity aspect, when multiple developers access the same state file multiple times to validate their changes to Terraform config, the race condition may cause the file to be corrupted. This raises the need for a locking mechanism.
When Terraform operations (plan, apply, or destroy) are performed, the state files are locked for the duration of the operation. If another developer tries to execute their operations during this time, the request is queued. The operation resumes when the current operation completes and the lock on the state file is released.
When using AWS S3 buckets as a remote state backend, DynamoDB is used to support this locking mechanism. It holds a single boolean attribute named “LockID” that indicates whether the operation on the state file can be performed or not.
How to create a Terraform S3 backend
It is fairly easy to configure remote backends using AWS S3 for any Terraform configuration. The steps are summarized below:
1. Create an S3 bucket
If you need help, see our creating S3 bucket with Terraform tutorial.
-
- Set bucket permissions
- Enable bucket versioning
- Enable encryption
The screenshot below shows the S3 bucket created for Terraform state file storage. Please note that you can choose any available name for the bucket.
2. Create a DynamoDB table
See AWS Docs.
-
- Set the column name as “LockID”
The screenshot below shows the DynamoDB table created to hold the LockID for the Terraform operations.
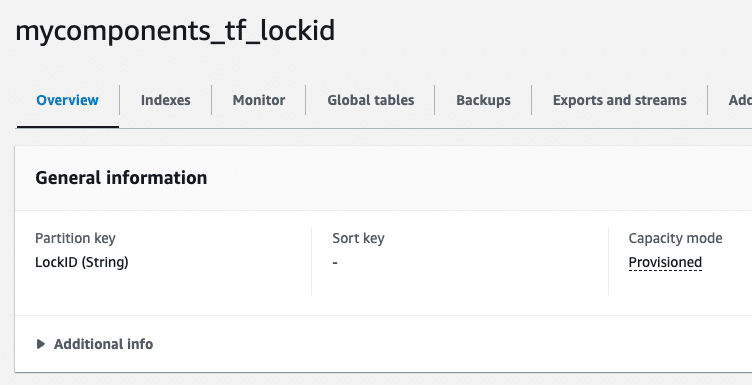
AWS Provider v5+ — DynamoDB table no longer required for state locking
If you are using hashicorp/aws provider version 5.x or later, Terraform supports native S3 state locking using conditional writes, without needing a DynamoDB table. To enable it, set use_lockfile = true in your backend block:
backend "s3" {
bucket = "mycomponents-tfstate"
key = "state/terraform.tfstate"
region = "eu-central-1"
encrypt = true
use_lockfile = true # Native S3 locking — no DynamoDB required (AWS provider v5+)
}DynamoDB-based locking still works in v5+ and remains the right choice if you need cross-tool compatibility or are on an older provider version. For new projects on AWS provider v5+, native S3 locking is the simpler option.
3. Include the backend block in the Terraform configuration.
-
- Specify the bucket name created in Step 1.
- Specify the key attribute, which helps us create the state file with the same name as the provided value.
- Specify the DynamoDB table created in Step 2.
We have updated our Terraform provider configuration with the backend block, as shown below.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
backend "s3" {
bucket = "mycomponents-tfstate" # S3 bucket storing the state file
key = "state/terraform.tfstate" # Path to the state file within the bucket
region = "eu-central-1" # Region where the bucket lives
encrypt = true # Enable server-side encryption at rest
dynamodb_table = "mycomponents_tf_lockid" # DynamoDB table for state locking
}
}As far as configuring the S3 backend is concerned, we have followed the manual steps by logging into the AWS console. It is possible to manage the S3 bucket and DynamoDB using a separate Terraform configuration as well, as described in the documentation.
However, as a best practice, these configurations should not be part of the project’s Terraform configs.
Once these configurations are done, few changes needed while we develop the config for other components. The backend is supposed to remain reliable and constant to serve the project’s purpose.
4. Initialize the S3 backend
Our current Terraform configuration does not have much code. It only consists of the provider configuration with the backend. Before we can plan and apply any configuration, it is necessary to initialize the Terraform repository.
When we run terraform init, the backend is automatically configured with the S3 bucket details we provided before. The output below confirms that the S3 backend has been successfully configured.
tfstate-mycomponents % terraform init
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- Finding hashicorp/aws versions matching "~> 4.18.0"...
- Installing hashicorp/aws v4.18.0...
- Installed hashicorp/aws v4.18.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.If we now check the contents of the S3 bucket, it will still be empty. At this point, it is important to note that the backend is configured successfully, and we are ready to add more IaC components to our repository and create them using Terraform.
Let’s go ahead and create a simple EC2 instance and observe the command line output.
Add a variables.tf file alongside main.tf:
# variables.tf
variable "ami" {
description = "AMI ID for the EC2 instance"
type = string
default = "ami-0c55b159cbfafe1f0" # Amazon Linux 2 (eu-central-1) — update as needed
}
variable "instance_type" {
description = "EC2 instance type"
type = string
default = "t3.micro"
}And update main.tf to use the corrected variable name:
# main.tf
resource "aws_instance" "demo" {
ami = var.ami
instance_type = var.instance_type
tags = {
Name = "My VM"
}
}Assuming everything went well, the EC2 instance should appear in the AWS console, as shown below.
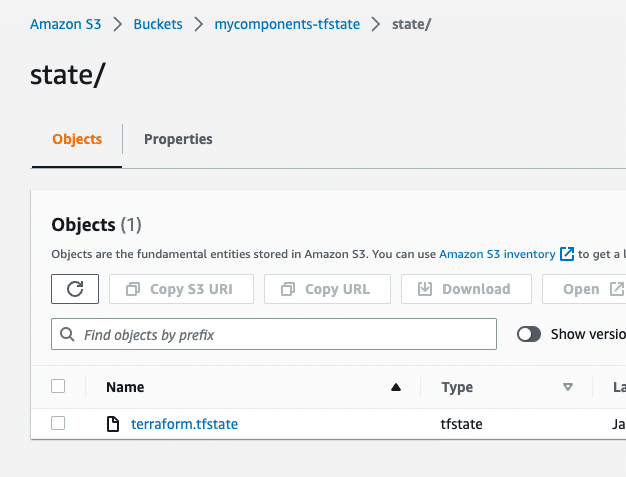
Going back to the S3 bucket used for the remote backend configuration, we can also confirm that the state file was created and is being managed here.
How to migrate to an AWS S3 remote backend
In some cases, configuration development may already have begun, especially if a single developer is working on the Terraform repository. They may choose to develop Terraform config with local state file backends and worry about remote state later. When new members are added to the team, the first step is to adopt a remote backend such as AWS S3.
Similarly, if there is a need to migrate from another remote backend to AWS S3 for any unforeseen reason, Terraform is equipped to handle the migration gracefully. So, irrespective of whether we want to migrate from a local backend to S3 or another remote backend to S3, the steps will be the same.
The Terraform backend configuration block is always part of the “terraform” provider configuration. Replace this backend block of code with the one that we defined for the S3 backend in the previous section. Once done, we need to reinitialize the Terraform repository using the terraform init command again.
Without reinitialization, none of the Terraform operations would work, as Terraform detects this change in the backend configuration.
The output below confirms this:
terraform plan
╷
│ Error: Backend initialization required, please run "terraform init"
│
│ Reason: Unsetting the previously set backend "s3"
│
│ The "backend" is the interface that Terraform uses to store state,
│ perform operations, etc. If this message is showing up, it means that the
│ Terraform configuration you're using is using a custom configuration for
│ the Terraform backend.
│
│ Changes to backend configurations require reinitialization. This allows
│ Terraform to set up the new configuration, copy existing state, etc. Please run
│ "terraform init" with either the "-reconfigure" or "-migrate-state" flags to
│ use the current configuration.
│
│ If the change reason above is incorrect, please verify your configuration
│ hasn't changed and try again. At this point, no changes to your existing
│ configuration or state have been made.During reinitialization, all the information from the current state file is migrated to the newly configured S3 backend. Once this is successfully completed, the development process can continue.
Reading remote state from an S3 backend
Once your state is stored in S3, other Terraform configurations can reference its outputs using the terraform_remote_state data source. This is useful when you split infrastructure across multiple root modules — for example, a networking stack that creates a VPC, and an application stack that needs to deploy into it.
First, expose the value you want to share as a root output in the source configuration:
# networking/outputs.tf
output "private_subnet_id" {
value = aws_subnet.private.id
}Then, in your application configuration, read it back from S3:
# app/main.tf
data "terraform_remote_state" "networking" {
backend = "s3"
config = {
bucket = "mycomponents-tfstate"
key = "networking/terraform.tfstate"
region = "eu-central-1"
}
}
resource "aws_instance" "app" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.micro"
subnet_id = data.terraform_remote_state.networking.outputs.private_subnet_id
}Note that only root-level outputs are accessible this way. Values inside child modules aren’t exposed unless you thread them up through an output block. Also, make sure the IAM role running the consumer configuration has s3:GetObject access to the referenced state file.
Terraform S3 backend best practices
In this section, we will look at best practices for using AWS S3 buckets as the remote backend for Terraform operations.
Some of the Terraform S3 backend best practices include:
- Encryption
- Access control
- Versioning
- Locking
- Backend First
Most of these practices are easy to implement as they are readily supported by the AWS S3 service.
1. Enable file encryption
Given the sensitive nature of Terraform state files, it makes sense to encrypt them in storage. AWS S3 buckets offer this functionality by default which makes it easy to implement encryption at the click of a button.
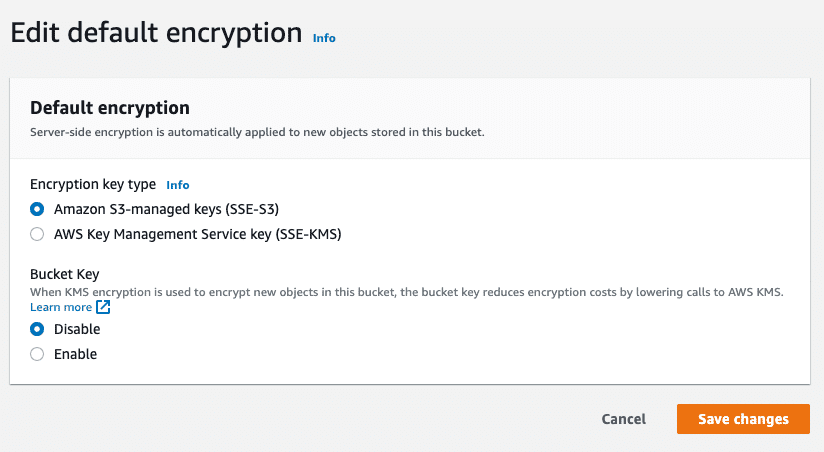
Organizations can choose to let AWS S3 manage these keys for their projects. It is also possible to take a more sophisticated approach where organizations take control of their keys using AWS KMS service.
2. Implement access control
Needless to say, public access should be strictly blocked for S3 buckets used for Terraform remote state management.
Most security threats arise from human errors, so it is important to control manual access to state files stored in these S3 buckets. This helps reduce accidental modifications and unauthorized actions.
Bucket policies provide a powerful, flexible way to manage access to your S3 buckets. To leverage them, you need to first identify the IAM resources that should have access to your bucket. After that, you’ll need to determine the necessary permissions you want to grant.
Generally, the required permissions would be actions like listing the bucket contents (s3:ListBucket), reading objects (s3:GetObject), and writing or deleting objects (s3:PutObject, s3:DeleteObject).
You will need to write a JSON policy similar to this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::YOUR_ACCOUNT_ID:role/YOUR_ROLE_NAME"
},
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME",
"arn:aws:s3:::YOUR_BUCKET_NAME/*"
]
}
]
}Replace YOUR_ACCOUNT_ID, YOUR_ROLE_NAME, and YOUR_BUCKET_NAME with values from your AWS account. When you have done this, you can easily go to the permissions tab on your S3 bucket, select bucket policy, and add the above policy there.
It is not the current best practice, but you can use ACLs in AWS S3 to implement strict access controls. As shown below, it is possible to grant various levels of access to the users/entities who are supposed to access the state files for taking designated actions.
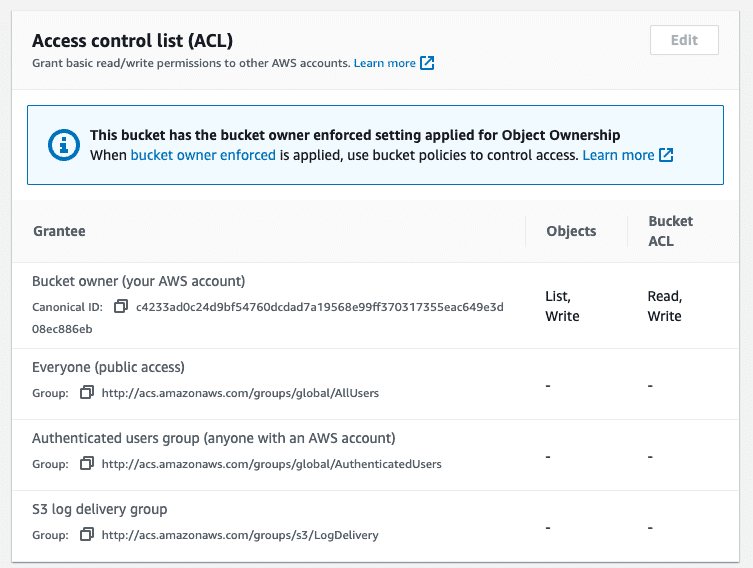
Ideally, the only entity with write access to the S3 buckets used as Terraform’s remote backend should be the user account assigned for Terraform operations. Organizations typically implement the concept of “tech users” or “service accounts” which are different from normal human user accounts.
Define ACLs that allow read and write access to the tech account responsible for locking and modifying the state information and allow read access to selected users for verification purposes.
The principle of least privilege should be used in both cases.
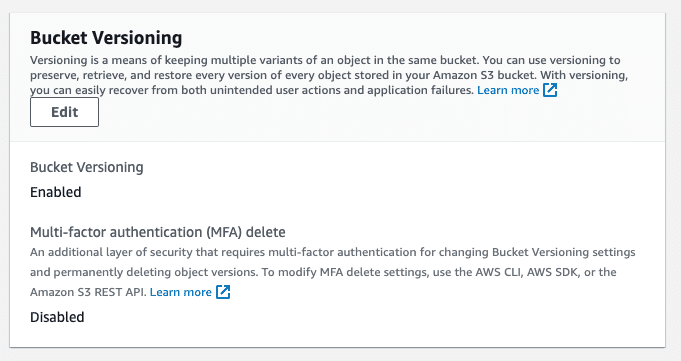
3. Enable bucket versioning
AWS S3 bucket versioning allows us to keep a historical record of all modifications to any file in the bucket. In the case of a disaster or file corruption, it is easier to recover the state file if previous versions are available.
Given the nature of state files, it is better to recover from a previous version than to rebuild the state files by importing existing infrastructure manually and individually. With versioning, only the delta needs to be imported, saving a lot of time and cost.
AWS S3 supports bucket versioning. It’s disabled by default, but you should enable it for any bucket storing Terraform state so you can roll back from mistakes. As a next step, MFA should also be enabled, so that delete actions are either avoided or happen carefully.
4. Use file-locking
As discussed earlier, to avoid file corruption caused by multiple simultaneous writes, it is important to implement file locking.
When you use AWS S3 as a remote backend, always create a corresponding DynamoDB table as described in the Implementation section. When a developer wants to perform operations that affect state files (plan, apply, destroy), Terraform first locks the file by updating the LockID column in the specified DynamoDB table.
This avoids race conditions. Thus DynamoDB is a very integral part of Terraform’s S3 backends.
5. Follow the backend-first rule
When initiating any Terraform project – especially when multiple developers are working on the same repo – a remote backend should be configured first. This is a general best practice and not specific to AWS S3 remote backend.
Configuring a remote backend is a one-time activity, and once it’s done, we don’t need to worry about maintaining the state file during development.
6. Split state by blast radius and ownership
Avoid one monolithic state file for everything. Use separate backends (or at least separate S3 keys) per environment, account, and domain (e.g., network, data, app) to reduce lock contention, speed up plans, and limit the impact of mistakes or state corruption.
7. Harden and monitor your state bucket
Treat the S3 bucket as a crown-jewel asset: block public access, enforce default encryption, restrict access via IAM roles rather than long-lived keys, and enable logging/CloudTrail, plus alerts for unusual access patterns (e.g., access-denied spikes or policy changes).
Previously, the Affinity team used Terraform both as their runner and for state management. Now, they use Amazon S3 for state management, but because this is connected to the Spacelift provider, state management is something they don’t have to worry about.
Terraform S3 backend common errors
When using the S3 backend in Terraform for state storage, several common issues may arise.
Here are some frequent errors and their likely causes:
- Initialization errors:
- Bucket doesn’t exist – Ensure the S3 bucket exists before running
terraform init. - Access denied errors – Your session may have expired, or the credentials you’re using may not have enough privileges to access the S3 bucket.
- Bucket doesn’t exist – Ensure the S3 bucket exists before running
- State locking errors
- LockID mismatch – If a process or user holds a lock, Terraform operations will fail until the lock is released. This prevents simultaneous changes to the infrastructure.
- DynamoDB table configuration – There may be issues with the DynamoDB table configuration or with the credentials used to access it.
- Backend configuration errors:
- Invalid configuration data: There may be problems with one of the backend configuration parameters (e.g. key, region, bucket, etc.)
- Encryption errors: If you are using KMS with a custom KMS key, ensure your AWS credentials have sufficient permissions to use that key.
- Networking errors: Ensure the machine from which you run Terraform has network access to the S3 bucket and DynamoDB table.
- S3 bucket policy issues: Bucket policies may restrict specific IPs or principals from accessing the bucket. Ensure your identity and source IP have permission to access the S3 bucket.
Let Spacelift handle Terraform state and workflows
Terraform is really powerful, but to achieve an end-to-end secure GitOps approach, you need a platform built for infrastructure orchestration. Spacelift goes beyond running Terraform workflows, giving you a governed, two-path deployment model and unlocking features such as:
- Policy as code (based on Open Policy Agent) — Control how many approvals you need for runs, what kind of resources you can create, and what parameters those resources can have. You can also govern behavior when a pull request is open or merged.
- Multi-IaC orchestration — Combine Terraform with Kubernetes, Ansible, and other infrastructure as code tools such as OpenTofu, Pulumi, and CloudFormation. Create dependencies between them and share outputs across stacks.
- Governed developer self-service — Use Blueprints and Templates to build Golden Paths for your teams. Complete a simple form to provision infrastructure based on Terraform and other supported tools — with guardrails enforced throughout.
- Spacelift Intelligence — Get AI-powered insights across your stacks, runs, and resources to help you identify issues faster and make better infrastructure decisions.
- Integrations with third-party tools — Connect your existing tools and build policies around them. For example, see how to integrate security tools into your workflows using Custom Inputs.
Spacelift also supports private workers, so you can execute infrastructure workflows inside your own security perimeter. See the documentation for details on configuring worker pools.
You can try it for free by creating a trial account or booking a demo with one of our engineers.
Key points
AWS S3 is one of the most reliable and cost-effective choices for managing Terraform remote state, but the backend configuration is only as good as the practices around it. Encrypting your state files, enabling versioning, locking with DynamoDB (or natively in AWS provider v5+), scoping IAM access tightly, and splitting state by environment are what turn a basic setup into something production-ready.
Get these right from the start — they are easy to overlook early and expensive to fix later. If you’d rather skip managing the backend infrastructure altogether, Spacelift handles state, locking, and workflow orchestration out of the box, so your team can stay focused on the infrastructure that actually matters.
Note: New versions of Terraform are released under the BUSL license, but everything created before version 1.5.x remains open source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Terraform Management Made Easy
Spacelift effectively manages Terraform state, more complex workflows, supports policy as code, programmatic configuration, context sharing, drift detection, resource visualization and includes many more features.
Frequently asked questions
Why should I use S3 as a Terraform backend instead of local state?
Local state is only safe when a single person is working on a project. As soon as there’s a team, it becomes a source of conflicts, accidental overwrites, and leaked credentials if committed to version control. S3 gives you a centralized, encrypted, and versioned location for state that every team member and CI/CD pipeline can safely access.
Do I need DynamoDB for Terraform S3 state locking?
If you’re using AWS provider v4 or earlier, DynamoDB is required to handle state locking and prevent concurrent runs from corrupting the state file. From AWS provider v5 onwards, you can use native S3 locking instead by setting use_lockfile = true in your backend block, making DynamoDB optional.
What happens if the DynamoDB lock isn't released?
If a Terraform run is interrupted, the lock may remain in place and block all subsequent runs with a “state locked” error. You can resolve this by running terraform force-unlock <LOCK_ID>, but do so with caution and only when you’re certain no other operation is in progress.
How do I migrate from local to S3 Terraform backend?
Add the S3 backend block to your Terraform configuration, then run terraform init -migrate-state — Terraform will detect the backend change and automatically copy your existing local state into the S3 bucket without any manual file handling required.
Can I use S3 backend without DynamoDB?
Yes, from AWS provider v5+ you can enable native S3 state locking with use_lockfile = true, removing the need to provision and manage a DynamoDB table. For older provider versions, skipping DynamoDB means running without any locking mechanism, which is risky on any project with more than one contributor or automated pipeline.
