
DynamoDB is one of the most common AWS services managed with Terraform, both as a standalone NoSQL database and as a state-locking backend for the S3 remote backend.
In this article, you will learn how to create and manage DynamoDB tables with Terraform, configure Global Secondary Indexes and streams, set up state locking with an S3 backend, and apply production best practices. We will discuss why you might want to use Terraform to manage DynamoDB in the first place.
What we will cover:
What is DynamoDB?
DynamoDB is a fully managed, serverless NoSQL database service from Amazon Web Services (AWS) that provides high-performance, scalable, and flexible data storage. It offers features such as automatic scaling, built-in security, and global tables for multi-region, multi-active database capabilities, while eliminating the need for manual server provisioning and management.
DynamoDB is a fully managed service, meaning Amazon handles administrative tasks such as hardware provisioning, setup, configuration, and maintenance. Amazon describes DynamoDB as:
Serverless, NoSQL, fully managed database with single-digit millisecond performance at any scale.
For those more familiar with Azure, the equivalent database service would be Cosmos.
Check out more information about DynamoDB on the docs pages.
What are DynamoDB tables?
AWS DynamoDB tables are the fundamental containers for storing data in Amazon DynamoDB that offer scalable, low-latency data storage and retrieval with support for key-value and document data structures. Each table consists of items, and each item is a set of attributes, with a primary key being the only required attribute for uniquely identifying each item.
How is DynamoDB different from traditional databases?
DynamoDB is a NoSQL database, meaning it doesn’t follow the traditional relational model of tables with rows and columns. Instead, it uses a key-value and document data model, allowing each item to have a different structure, which is ideal for handling unstructured or semi-structured data like JSON documents.
Unlike traditional relational databases such as MySQL or PostgreSQL, which require predefined schemas, DynamoDB supports flexible, schema-less designs. Traditional databases use SQL for querying, whereas DynamoDB uses its own API, which, although functional, is not as powerful for complex queries involving table joins.
Lastly, traditional databases guarantee strong consistency in reads, reflecting the latest data, whereas DynamoDB offers eventual consistency for faster performance and scalability, making it suitable for high-performance, low-latency applications with real-time data access.
Why use DynamoDB with Terraform?
You can use Terraform to manage all your AWS infrastructure, not just DynamoDB. Terraform lets you define your DynamoDB tables and configurations alongside other resources like Lambda functions and API gateways, creating a complete configuration harnessing all the benefits of infrastructure as code for your application.
DynamoDB is often used with Terraform for several other reasons:
- State locking — DynamoDB provides an effective mechanism for state locking in Terraform, which is crucial for preventing concurrent access to the same Terraform state file by multiple users or processes.
- Scalability and performance — DynamoDB offers high availability, scalability, and low-latency performance, making it an excellent choice for managing Terraform state.
- Integration with AWS services — DynamoDB is an AWS service, so it integrates seamlessly with other AWS resources that may be part of your infrastructure
- Managed service — DynamoDB is a fully managed service, which means you don’t have to worry about provisioning, patching, or managing the underlying infrastructure.
- Flexibility — DynamoDB supports document and key-value data models, providing flexibility in how you store and retrieve data related to your Terraform state.
- Automatic scaling — DynamoDB can automatically scale to meet the demands of your Terraform operations without manual intervention.
How to create a DynamoDB table with Terraform?
Follow these steps to create a DynamoDB table using Terraform:
- Set up AWS credentials.
- Create a Terraform configuration file.
- Configure AWS provider in Terraform.
- Include DynamoDB table resource.
- Add items to your DynamoDB table.
- Reference items with DynamoDB data source.
- Destroy your DynamoDB table.
1. Configure AWS credentials
Terraform needs access to your AWS account to create resources. You can configure your AWS credentials using environment variables, shared credentials files, or IAM roles. One common way is to set environment variables:
export AWS_ACCESS_KEY_ID="your_access_key_id"export AWS_SECRET_ACCESS_KEY="your_secret_access_key"
Alternatively, you can use the AWS CLI to configure your credentials:
aws configure
2. Create a Terraform configuration file
Create a new directory for your Terraform configuration files and create a .tf file, for example, main.tf.
3. Configure AWS provider in Terraform
In your Terraform configuration file, specify the AWS provider and the region you want to work with:
provider "aws" {
region = "us-west-2" # Specify your desired region
}4. Include DynamoDB table resource
Next, add the new DynamoDB table resource to the configuration file.
In this example, we will create one called ‘UsersTable’, using the resource aws_dynamodb_table.
resource "aws_dynamodb_table" "users" {
name = "UsersTable"
billing_mode = "PROVISIONED"
read_capacity = 10
write_capacity = 5
hash_key = "userId"
attribute {
name = "userId"
type = "S" # String data type
}
tags = {
Name = "UsersTable"
}
}Let’s take a look at this basic DynamoDB table in more detail:
billing_modeis set toPROVISIONED, with read and write capacity units (RCUs and WCUs) defined.read_capacityandwrite_capacityspecify the initial read and write throughput for the table.hash_keydefines the primary key for the table. Here, it’suserIdwhich will be a string type (S).- The
attributeblock defines the schema for the table. Here, we have only theuserIdattribute. - The
tagsblock assigns a tag namedNameto the table for easier identification.
We’ve created our first DynamoDB table in Terraform!
How to manage tables and items using Terraform?
To add items to your existing DynamoDB table, you can use the aws_dynamodb_table_item resource. You can then apply these configurations with Terraform commands (terraform init, terraform plan, terraform apply) to create, update, and manage the DynamoDB tables and their items.
The example is shown below:
resource "aws_dynamodb_table_item" "user_item" {
table_name = aws_dynamodb_table.users.name
hash_key = "userId"
item = jsonencode({
"userId" = { "S" = "user123" }
"UserName" = { "S" = "Luke Skywalker" }
"Email" = { "S" = "usetheforceluke@example.com" }
})
}You can then reference items in your Terraform table using the DynamoDB data source:
data "aws_dynamodb_table" "users" {
name = "UsersTable"
}
data "aws_dynamodb_table_item" "user_item" {
table_name = data.aws_dynamodb_table.users.name
key = jsonencode({
"userId" = { "S" = "user123" }
})
}To remove tables and items from DynamoDB, you can simply remove them from your configuration files and run terraform apply. As they no longer exist in the configuration, they will be destroyed.
How do you prevent destroy in Terraform DynamoDB table?
To prevent the destruction of resources managed by Terraform, particularly DynamoDB tables, you can use the prevent_destroy lifecycle rule within your Terraform code. This rule helps safeguard critical resources from accidental deletion.
Here’s an example:
resource "aws_dynamodb_table" "users" {
name = "UsersTable"
billing_mode = "PROVISIONED"
read_capacity = 10
write_capacity = 5
hash_key = "userId"
attribute {
name = "userId"
type = "S" # String data type
}
lifecycle {
prevent_destroy = true
}
tags = {
Name = "UsersTable"
}
}How to add indexes and enable streams for DynamoDB?
To enhance querying performance on attributes other than the primary key in your Amazon DynamoDB table, you can add a Global Secondary Indexes (GSI) using Terraform. This is accomplished by including a global_secondary_index block in your Terraform configuration.
Here’s how you can do it:
resource "aws_dynamodb_table" "users" {
name = "UsersTable"
billing_mode = "PROVISIONED"
read_capacity = 10
write_capacity = 5
hash_key = "userId"
attribute {
name = "userId"
type = "S"
}
global_secondary_index {
name = "user_email_index" # Name for your GSI
hash_key = "email" # Attribute for GSI hash key
range_key = "userName" # Optional range key for GSI (can be omitted)
projection_type = "ALL"
read_capacity = 5
write_capacity = 5
}
tags = {
Name = "UsersTable"
}
stream_enabled = true
stream_view_type = "NEW_AND_OLD_IMAGES" # Change to "NEW_IMAGE" or "OLD_IMAGE" for different stream view types
}Setting stream_enabled to true allows you to enable streams for the table, so you can capture changes to items in the table.
When an item in the table is modified, StreamViewType determines what information is written to the table’s stream. Valid values are KEYS_ONLY, NEW_IMAGE, OLD_IMAGE, NEW_AND_OLD_IMAGES.
State locking in Terraform with DynamoDB
Terraform uses a state file to track the resources it manages. Storing this state in an S3 bucket provides durability and enables team collaboration. However, in a team environment or with automated pipelines, multiple Terraform processes might attempt to modify the state simultaneously, potentially causing inconsistencies.
When using S3 as a backend for Terraform state storage, you can optionally integrate DynamoDB for state locking. This integration ensures that only one Terraform process can modify the state at a time, preventing potential data corruption and conflicts.
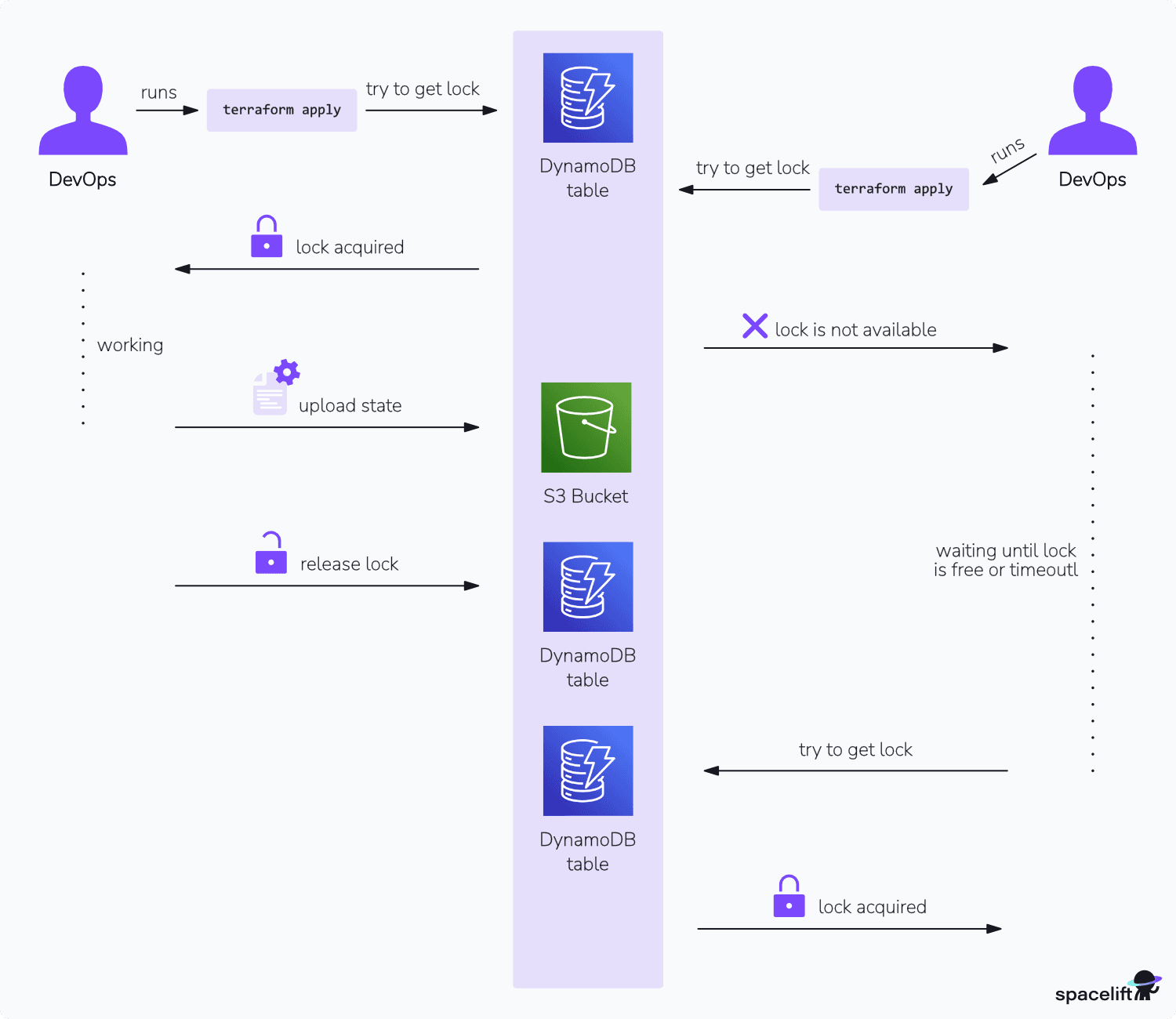
State locking in Terraform works by acquiring a lock on the state file in DynamoDB before performing any operation that could modify the state, such as terraform apply, terraform plan, or terraform destroy.
DynamoDB acts as a distributed locking mechanism. Before making any changes, Terraform attempts to acquire a lock by writing to a specific DynamoDB table. If the lock is available, Terraform acquires it and proceeds with the operation. If another process already holds the lock, Terraform will wait for a configurable period before retrying. Once the operation is complete, Terraform releases the lock, allowing other processes to acquire it.
This locking mechanism prevents race conditions where two processes might read the same state, make different changes, and then try to write back, potentially overwriting each other’s changes.
The graph below shows the state-locking process:
Example: Configuring state locking in Terraform with DynamoDB table
To configure state locking, you’ll first need a DynamoDB table:
resource "aws_dynamodb_table" "terraform_state_lock" {
name = "terraform-state-lock"
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}And then reference in your backend using the dynamodb_table attribute:
terraform {
backend "s3" {
bucket = "your-terraform-state-bucket"
key = "your-state-file-key"
dynamodb_table = "terraform_state_lock" # Enable state locking
}
}Make sure that the IAM role Terraform uses has appropriate permissions to access the DynamoDB tables for locking operations.
DynamoDB best practices with Terraform
Managing DynamoDB with Terraform goes beyond a basic aws_dynamodb_table block. Follow these practices to keep your configurations production-ready and free of common pitfalls.
- Only declare key attributes in the
attributeblock. DynamoDB only expects static definitions for hash, range, and index keys. Adding non-key attributes causes Terraform to detect phantom drift and loop indefinitely during planning. - Use
PAY_PER_REQUESTfor unpredictable workloads. Unless you can reliably forecast traffic,PAY_PER_REQUESTeliminates the risk of throttling or over-provisioning — and is the recommended billing mode for state lock tables specifically. - Enable PITR and encryption on production tables. Point-in-time recovery gives you a 35-day restore window and takes up to 10 minutes to activate, so include it from day one. For compliance-sensitive data, set
server_side_encryption { enabled = true }to use a KMS-managed key instead of the default AWS-owned key. - Configure TTL to control data growth. The
ttlblock lets DynamoDB automatically expire and delete items past a timestamp you define — at no extra cost — keeping table size and read costs in check over time. - Use
ignore_changeswhen pairing Terraform with autoscaling. Autoscaling adjustsread_capacityandwrite_capacityoutside Terraform’s control, causing constant drift in plans. Addignore_changes = [read_capacity, write_capacity]to yourlifecycleblock to avoid this. - Prefer deletion_protection_enabled over prevent_destroy for critical tables.
deletion_protection_enabled = trueblocks deletion at the AWS API level, stopping even direct CLI calls. Theprevent_destroylifecycle rule only prevents Terraform-initiated deletions, which is a weaker guarantee.
Managing Terraform state with Spacelift
Terraform is powerful, but to achieve an end-to-end secure GitOps approach, you need a platform that can orchestrate your Terraform workflows. Spacelift takes managing Terraform to the next level by giving you access to a robust CI/CD workflow and unlocking features such as:
- Policies (based on Open Policy Agent) – You can control how many approvals you need for runs, what kind of resources you can create, and what kind of parameters these resources can have. You can also control the behavior when a pull request is open or merged.
- Multi-IaC workflows – Combine Terraform with Kubernetes, Ansible, and other IaC tools such as OpenTofu, Pulumi, and CloudFormation, create dependencies among them, and share outputs
- Build self-service infrastructure – You can use Blueprints and Templates to build self-service infrastructure; simply complete a form to provision infrastructure based on Terraform and other supported tools.
- AI-powered provisioning and diagnostics – Spacelift Intelligence adds natural language provisioning, diagnostics, and operational insight across your infrastructure workflows.
- Integrations with any third-party tools – You can integrate with your favorite third-party tools and even build policies for them. For example, see how to integrate security tools in your workflows using Custom Inputs.
Spacelift enables you to create private workers inside your infrastructure, which helps you execute Spacelift-related workflows on your end. For more information on configuring private workers, refer to the documentation.
Spacelift can also optionally manage the Terraform state for you, offering a backend synchronized with the rest of the platform to maximize convenience and security. You can also import your state during stack creation, which is very useful for engineers who are migrating their old configurations and states to Spacelift.
Behind the scenes, Spacelift uses Amazon S3 and stores all the data in Ireland. Having Spacelift manage the state for you is simple, as this behavior is achieved by default without you needing to do anything. You can read more about how it actually works here.
At the same time, it’s protected against accidental or malicious access as Spacelift can map state access and changes to legitimate Spacelift runs, automatically blocking all unauthorized traffic.
For more information, refer to this blog post, which shows in detail Spacelift’s remote state capabilities.
Key points
DynamoDB integrates naturally into a Terraform-managed AWS stack, covering everything from basic table creation to production-grade configurations. Here is a summary of what we covered:
- Use
aws_dynamodb_tableto define tables with billing mode, hash/range keys, GSIs, streams, and tags as code. - Manage table items with
aws_dynamodb_table_itemand reference existing tables using theaws_dynamodb_tabledata source. - Protect critical tables with
deletion_protection_enabledand theprevent_destroylifecycle rule. - Configure a DynamoDB table as a state-locking backend alongside S3 to prevent concurrent state modifications across your team.
- Follow production best practices: enable PITR and encryption at rest, set up TTL for data expiry, and use
ignore_changeswhen autoscaling is attached.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Manage Terraform better with Spacelift
Orchestrate Terraform workflows with policy as code, programmatic configuration, context sharing, drift detection, resource visualization, and more.
Frequently asked questions
Does DynamoDB store the Terraform state file?
No, DynamoDB only handles state locking to prevent concurrent modifications. The state file itself is stored in S3, and both resources are required together for a complete remote state setup.
What IAM permissions does Terraform need to use DynamoDB state locking?
The IAM role or user running Terraform needs dynamodb:GetItem, dynamodb:PutItem, and dynamodb:DeleteItem permissions on the lock table.
What happens if a Terraform lock is never released?
If a process fails mid-run, the lock can get stuck. You can manually remove it with terraform force-unlock <LOCK_ID>, which deletes the lock entry from the DynamoDB table.
Should I use PROVISIONED or PAY_PER_REQUEST for a state lock table?
PAY_PER_REQUEST is the better choice for state locking since lock operations are infrequent and unpredictable, making it unnecessary to pre-provision capacity.
Can I bring an existing DynamoDB table under Terraform management without recreating it?
Yes, using an import block (Terraform v1.5 and later) you can import an existing table by its name without any downtime or data loss.
Terraform Docs. State: Locking | Terraform | HashiCorp Developer. Accessed: 17 October 2025
Terraform Docs. Manage resource lifecycle. Accessed: 17 October 2025
Terraform Registry. Resource: aws_dynamodb_table. Accessed: 17 October 2025
AWS. Build Fast NoSQL Applications – Amazon DynamoDB – AWS. Accessed: 17 October 2025
