
As exciting as starting a new Terraform project may sound, the first question is where and how we begin. What should be the first file that needs to be created? When the project grows, we realize a few things and learn our lessons about structuring a project in a certain way, but it is too late to put in refactoring efforts.
Various aspects influence the way we manage our Terraform config in a repository. In this post, we will learn about them and discuss a few important strategies and best practices around structuring Terraform project files in an efficient and standardized way.
What we will cover:
- What are Terraform configuration files?
- Project structure and file types explained
- Additional file types in Terraform projects
- .gitignore file
- How to organize Terraform files for bigger projects?
- How to automate the management of Terraform files and directories?
- How to organize modules in a Terraform project?
- Best practices for structuring Terraform projects
- Managing complex IaC setups
TL;DR
Terraform configuration lives in version-controlled *.tf files (HCL). A clean Terraform project structure makes your IaC easier to scale, review, and maintain.
A solid starter Terraform layout uses a small root module with main.tf, variables.tf, outputs.tf, and providers.tf, keeps environment settings in separate env/ folders with *.tfvars, and puts reusable infrastructure patterns in dedicated modules/ directories for clean growth and maintenance.
As projects grow, standardize reusable modules and organize by environments/services/regions to keep complexity manageable (optionally layering CI/CD automation for consistent workflows and state management).
What are Terraform configuration files?
Terraform configuration files are used for writing your Terraform code. They have a .tf extension and use a declarative language called HashiCorp Configuration Language (HCL) to describe the different components that are used to automate your infrastructure.
Terraform should always be used with a version control system, so all of your Terraform files should be stored inside it. This allows you to easily track the changes made to the code over time and roll back to a previous version of the configuration.
This is what an example Terraform file looks like:
# main.tf
resource "aws_vpc" "this" {
cidr_block = var.vpc_cidr
}Project structure and file types explained
Any Terraform project is created to manage infrastructure in the form of code, i.e., IaC. Managing the Terraform IaC involves the following, at least.
- The cloud platform of choice, which translates to the appropriate provider configurations
- Various resources, i.e., cloud components
- State file management
- Input and output variables
- Reuse of modules and associated internal wiring
- Infrastructure security standards.
- Developer collaboration and CI/CD workflow
To begin writing a Terraform configuration while adhering to the best practices, we create the files below in the project’s root directory.
Terraform file types include:
- main.tf – containing the resource blocks that define the resources to be created in the target cloud platform.
- variables.tf – containing the variable declarations used in the resource blocks.
- provider.tf – containing the terraform block, S3 backend definition, provider configurations, and aliases.
- output.tf – containing the output that needs to be generated on successful completion of “apply” operation.
- *.tfvars – containing the environment-specific default values of variables.
In the beginning, the directory structure of a Terraform project would look like below:

While all Terraform configuration files have the same extension (.tf), and their name don’t matter, there is a convention on how to name these files and how to split the logic of your configuration. There are also input files with a .tfvars extension that will help with adding values to your variables.
Other configuration file formats:
- .tf.json – JSON representation of Terraform configuration. Useful when configs are machine-generated.
- *.tfquery.hcl (Terraform 1.14+) – used by the
terraform querycommand to define “list resources” operations against existing infrastructure; they don’t replace .tf but sit alongside them for discovery/import workflows.
Let’s look at each Terraform file type in more detail.
main.tf
The main.tf file is the starting point where you will implement the logic of infrastructure as code. This file will include Terraform resources, but it can also contain datasources and locals.
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
owners = ["099720109477"] #canonical
}
locals {
instances = {
instance1 = {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
}
instance2 = {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
}
}
}
resource "aws_key_pair" "ssh_key" {
key_name = "ec2"
public_key = file(var.public_key)
}
resource "aws_instance" "this" {
for_each = local.instances
ami = each.value.ami
instance_type = each.value.instance_type
key_name = aws_key_pair.ssh_key.key_name
associate_public_ip_address = true
tags = {
Name = each.key
}
}In this main.tf example, we are using a datasource to get an AMI ID for an Ubuntu image, locals to define how many instances we will create, and two resources — one that defines an aws_key_pair and one that defines aws_instances.
variables.tf
The variables.tf file includes the definitions of input variables for your configuration, mentioning their types, descriptions, and default values.
In the above example, we’ve defined a single input variable (these are prefixed with var.), and we will describe it in the variables.tf file.
variable "public_key" {
type = string
description = "Path to the public ssh key"
default = "/mnt/workspace/id_rsa.pub"
}Modern Terraform versions (1.9+) significantly improve input variable validation, including cross-object validation. Keeping variables in a dedicated variables.tf makes those rules easier to manage and review.
outputs.tf
The outputs.tf file is used to define output values that expose information about the resources created by a Terraform configuration.
In our example, we’ve defined a single output for the above configuration that exposes the public IPs of the instances that we are creating:
output "aws_instances" {
value = [for instance in aws_instance.this : instance.public_ip]
description = "Public ips of the instances"
}provider.tf
In the provider.tf file, you declare the providers required by a Terraform configuration, specifying details like authentication credentials, API endpoints, and other provider-specific settings needed to interact with external systems or cloud platforms.
In our provider.tf file, we’ve defined the provider configuration that takes care of the authentication to AWS:
provider "aws" {
region = "eu-west-1"
}Note: Pin the Terraform version in required_version and provider versions in required_providers, so teams don’t accidentally mix incompatible CLIs.
.tfvars
The .tfvars files are used to assign values to the input variables declared in other Terraform configuration files.
By default, Terraform will load variable values from files called terraform.tfvars or any_name.auto.tfvars. If you have both files, any_name.auto.tfvars will take precedence over terraform.tfvars.
For the above configuration, we have a single variable called public_key, so we will add a value for it in tfvars to overwrite the default variable added in the variables.tf file.
public_key = "/home/user/.ssh/public_key.pub"Additional file types in Terraform projects
Throughout the project, we may need to add more files to serve various purposes besides the Terraform configurations. You can find some examples of these files in the list below:
- README.md — As a general best practice, every repository should contain a README.md file that includes an overview of the source code, usage instructions, and any other relevant and important information
- Automation scripts — When there is a need to include automation scripts (bash, shell, python, golang, etc.) in CI/CD workflow, when certain scripts are required to be executed on the target resource being created, or to build a source code, etc. Bash/shell scripts are very powerful in general; there are many reasons to use them.
- YAMLs — The most common usage of YAML files in Terraform in this context is when implementing CI/CD automation.

.gitignore file
Since we are discussing the Terraform project structure, the .gitignore file plays a special role. As observed in previous sections, a Terraform project consists of multiple kinds of files and binaries.
For several reasons, not all files and directories should be part of the git repository. The following are some of the files included in the .gitignore file in a generic Terraform project.
- .terraform.tfstate — Terraform state files should never be pushed to the git repositories. Note that when using the remote backend for Terraform, the state files will not be available on the local system. A couple of reasons are:
- Security — State files may store sensitive details like keys, tokens, passwords, etc.
- Collaboration — When working within teams, managing the state file locally by each developer poses a high risk of state files needing to be more consistently overwritten.
- Binaries — The provider plugins downloaded locally or on a Terraform host (in .terraform directory) should not be part of the Git repository. The binaries thus downloaded are large in memory. Pushing and pulling the binaries from a remote git repo is inefficient for using network bandwidth.
- Crash.log — Crash log files are not always required, especially when a crash occurs due to the local environment.
- *.tfplan — We use the
terraform plancommand to save and use the output during the apply phase. This information is not required to be stored on a remote git repository. - When using a remote backend or an orchestration platform like Spacelift, state lives centrally (S3, GCS, or Spacelift-managed), and local state files may not exist at all. You should still keep any accidental .tfstate files out of Git for security reasons.
In the screenshot below, we have created a .gitignore file in our project repository. The template is used from GitHub’s gitignore repository, which also defines the guidelines for writing good .gitignore files.

To learn more, see How to Create & Use Gitignore File With Terraform.
How to organize Terraform files for bigger projects?
If the Terraform project manages many resources, then the main.tf file would include many lines of code, making it difficult to navigate.
There are multiple ways to supply the values for variables using .tfvars, apart from supplying them as CLI arguments and environment variables. Terraform loads the values from the terraform.tfvars file by default.
Similar behavior is achieved by using custom file names with the *.auto.tfvars extension. However, any other file name must be passed explicitly using the -var-file argument in the CLI.
The order of precedence between these files is as shown below.
Terraform.tfvars > *.auto.tfvars > custom_file_name
When we start writing the configurations for the first time, it may make sense to consolidate various components depending on a certain pattern. A couple of examples of slicing the main.tf files are:
- By services – you can include all the components required to support a particular business service in one file. This file contains all the databases, compute resources, network configs, etc., in a single file. The file is named according to the service being supported. Thus, while doing the root cause analysis (RCA), we already know which Terraform file needs to be investigated.
- By components – you may decide to segregate the resource blocks based on the nature of the components used. A Terraform project may have a single file to manage all the databases. Similarly, all network configurations, compute resources, etc., are managed in their individual files.
Note that Terraform does not interpret the .tf files included in the sub-directories. This takes us to the discussion of modules, which we will discuss later in this post. Irrespective of how the Terraform source code is segregated, the intention behind this should be to enable easy analysis and navigation.
Terraform files for multi-environment projects
One advantage of using Terraform to manage infrastructure is consistency. Owing to this, multiple Terraform environments are spun using the same project source code. This makes it easy to create sub-production and ephemeral environments, identical copies of the production. The sub-production environments are usually scaled-down versions of the production.
This variation is achieved using variables in the variables.tf file. .tfvars files are used to specify the scale of any environment. Thus, it is also common to have multiple .tfvars files alongside the rest of the Terraform configs.
For example, if we have to create three environments – prod, qa, and dev, then the following three .tfvars files are created with clear names.
- variables-dev.tfvars
- variables-qa.tfvars
- variables-prod.tfvars
Multiple environments are usually managed using workspaces in Terraform. Depending on the workspace being used the appropriate .tfvars file needs to be used – a manual error here can be risky.
Spacelift provides a way to manage workspaces in the form of Stacks, which can run either Terraform or OpenTofu. Stacks combine your repo, workspace, and backend, and use Contexts for shared environment variables and secrets. This greatly reduces the risk of pointing the wrong .tfvars at the wrong environment and makes multi-env setups repeatable.
How to automate the management of Terraform files and directories?
The previous section focused mainly on the files we deal with when we begin to work on a Terraform project. In this section, we will see the files created automatically by Terraform when the configurations are tested, applied, and destroyed. The concepts discussed in these sections will help us have a firm understanding that will enable us to structure the Terraform code better.
The first step to testing our configuration is initializing the repository. When we run terraform init, Terraform identifies the “required_providers” and downloads the appropriate plugin binary from the Registry. These binaries are stored in the “.terraform” directory located at the root of the project.
The init action also creates a .terraform.lock.hcl file.
Terraform lock files
The .terraform.lock.hcl is a file generated by Terraform. It maintains the hashes of the downloaded binaries for consistency and tracks the provider versions used in your configuration. We do not interact with these files directly or manually; they are maintained automatically by Terraform. However, you should commit the .terraform.lock.hcl file to your version control system.
The screenshot below shows the directory structure after running the init command.
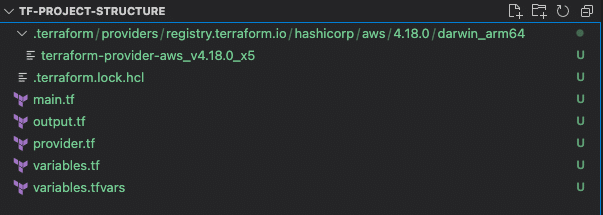
Once the project is initialized, we apply these configurations to create the cloud resources. A apply or destroy operation creates an additional file – terraform.tfstate. This is the Terraform state file, which is critical and automatically managed by Terraform. This file is either managed locally (default backend) or remotely. When working in teams, the remote backend should be used.
Find more details about Terraform’s state in the blog post – Managing Terraform State – Best Practices & Examples.
Given the importance, Terraform also creates the backup file (.terraform.tfstate.backup) for the state, as shown in the screenshots below.

Terraform implements a locking mechanism that helps avoid race conditions, and prevent state file corruption. The locking mechanism depends on the type of backend used.
For example, when using S3 as a remote backend service, Terraform uses the AWS DynamoDB table to manage the file lock.
In the case of the local backend, this lock is managed using an additional file that exists for the period of operation (plan, apply, destroy) being performed. Once the operation is completed, the file is removed.
In the screenshot below, we can see the file named “.terraform.tfstate.lock.info” being generated.

How to organize modules in a Terraform project?
The sections till now have covered the basic information related to a generic and simple Terraform project. Terraform projects created to manage a smaller set of infrastructure would follow the above structure, and it is enough. However, this simple structure may not be enough for larger projects.
Modules are a great way to follow the DRY principle when working with Terraform Infrastructure as Code. Modules encapsulate a set of Terraform config files created to serve a specific purpose. As discussed earlier, we may slice and group the infrastructure based on the type of components or the service they support.
In the diagram below, the Terraform project uses two modules to help create VPCs and Databases. These modules are reusable and based on the types of components.
Thus, it becomes easy to plug them into other Terraform projects.

The project root directory contains its set of Terraform config files. These config files also declare module blocks in addition to the general resource blocks. The module blocks refer to the source of these modules — it could be a remote git repository, Terraform Registry, or a locally developed module.
For example, the module block below uses a module stored locally in a given path.
module "project_vpc" {
source = "path/to/vpc/module/directory"
# inputs (required input variable in VPC module)
cidr_range = 10.0.0.0/24
}To know more about how modules work, check out our Terraform Modules tutorial.
Terraform Registry is a great resource for finding the modules to be reused. As an example, let us use this VPC module in our project. Add the code below to our main.tf file.
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "3.19.0"
}This is all we need to do to use an already existing module in our project.
Spacelift’s module registry also helps manage modules in a more easy and maintainable way. In addition to all the features offered by Terraform registry, Spacelift’s module registry is integrated with Stacks, environments, contexts, policies, and worker pools.
When we add a module, the project is reinitialized. By reinitializing the module source code, the module’s Terraform files are downloaded locally in the “.terraform” directory, which is the same directory where provider binaries also exist.
The project directory structure after initialization is shown below:

Do not get confused about the additional files included in the .terraform directory. They belong to the VPC module we used in our main.tf file.
This is to show how modules are managed internally. If customization is needed, it is possible to do the same here. Technically, we can now apply these changes, and a VPC will be created and managed in the state file of our project, i.e., in the project root directory.
It is possible for modules to have nested modules. Also, note that all the additional files related to VPC modules downloaded in the “.terraform” directory are “gitignored” by default, so they will never be pushed to the repository.
Best practices for structuring Terraform projects
When creating your Terraform configuration, you can either structure your projects using monorepos, or polyrepos. You may even find examples in which engineers are using monorepos for their modules and polyrepos for their environments or the other way around.
Suppose we have an AWS setup with a network module, an EC2 module, and two environments (dev and prod). Let’s see some potential setups according to best practices.
1. Monorepo for environments and modules
Here, in the same repository, we have the environments and modules folder with their corresponding configurations. In this example, you can easily use the module source as the path to the module.
monorepo tree .
.
├── environments
│ ├── dev
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ ├── provider.tf
│ │ ├── terraform.tf
│ │ ├── terraform.tfvars
│ │ └── variables.tf
│ └── prod
│ ├── main.tf
│ ├── outputs.tf
│ ├── provider.tf
│ ├── terraform.tf
│ ├── terraform.tfvars
│ └── variables.tf
└── modules
├── ec2
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── network
├── main.tf
├── outputs.tf
└── variables.tf2. Monorepo for modules and polyrepo for environments
In this example, we will have a total number of three repositories and use the module sources with the git source of the modules specifying the folder and the tag/branch.
Modules repository:
modules
├── ec2
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── network
├── main.tf
├── outputs.tf
└── variables.tfDev repository:
dev tree .
.
├── main.tf
├── outputs.tf
├── provider.tf
├── terraform.tf
├── terraform.tfvars
└── variables.tfProd repository:
prod tree .
.
├── main.tf
├── outputs.tf
├── provider.tf
├── terraform.tf
├── terraform.tfvars
└── variables.tf3. Monorepo for environments and polyrepo for modules
In this example, we will again have a total number of three repositories and use the module sources with the git source of the modules specifying the module tag or branch.
Environments repository:
environments tree .
.
├── dev
│ ├── main.tf
│ ├── outputs.tf
│ ├── provider.tf
│ ├── terraform.tf
│ ├── terraform.tfvars
│ └── variables.tf
└── prod
├── main.tf
├── outputs.tf
├── provider.tf
├── terraform.tf
├── terraform.tfvars
└── variables.tfEC2 module:
ec2 tree .
.
├── main.tf
├── outputs.tf
└── variables.tfNetwork module:
network tree .
.
├── main.tf
├── outputs.tf
└── variables.tf4. Polyrepos
In this scenario, we will have a total of four repositories, and for each environment repo, we will specify the module using the git URL and tag/branch.
Dev repository:
dev tree .
.
├── main.tf
├── outputs.tf
├── provider.tf
├── terraform.tf
├── terraform.tfvars
└── variables.tfProd repository:
prod tree .
.
├── main.tf
├── outputs.tf
├── provider.tf
├── terraform.tf
├── terraform.tfvars
└── variables.tfEC2 module:
ec2 tree .
.
├── main.tf
├── outputs.tf
└── variables.tfNetwork module:
network tree .
.
├── main.tf
├── outputs.tf
└── variables.tfManaging complex IaC setups
Organizations that have advanced on their infrastructure as code (IaC) adoption journey typically have a complex set of infrastructures to be managed. Some of the key aspects that contribute to this complexity and their remedies are:
Complex infrastructure requirement
The infrastructure design may consist of many advanced components interlinked with each other, redundant backup systems, complex network and firewall requirements, etc. The use of modules is suggested for such projects or when the projects eventually become complex.
With modules, breaking the Terraform or OpenTofu IaC monolith into manageable and relatable sets is possible.
Strict security controls
When a project grows, the security requirements also grow exponentially as the attack surface grows, and various combinations must be addressed to mitigate the risks.
To take complex security guardrails one step further, it also makes sense to integrate a policy-as-code solution with your IaC workflows.
Standardization
To avoid reinventing the wheel, especially on larger projects, it makes sense to follow a modular approach and standardize the implementation of components for reuse.
A central repository to develop and host IaC modules that fundamentally address the organization’s policies is of great value. Projects using these modules can readily get going without worrying about adhering to company practices.
Such modules should be developed by center of excellence (COE) teams responsible for addressing standardization initiatives and enabling customer-facing teams to accelerate delivery.
Multiple environments
Managing identical and scaled-down copies of the production environment to facilitate development and quality analysis. The ability to create temporary, partially usable infrastructure is also desired.
Regional deployments
The need to manage multiple deployments and the ability to serve users with custom features and services. This could grow into more complex requirements.
Spacelift helps simplify these challenges by providing infrastructure orchestration with CI/CD automation for infrastructure management. Stacks are created from Git repositories, letting developers focus on infrastructure as code development while Spacelift handles provisioning automatically after PR merges.
For non-critical workloads like test environments or POCs, Spacelift Intent offers a faster path where developers can provision infrastructure in natural language without writing IaC, while the same policies, visibility, and audit trails apply.
Along with state file management, Spacelift uses Contexts, reusable sets of environment variables that you can associate with multiple stacks easily. Spacelift also manages the module registry, which integrates with stacks, policies, worker pools, and more. For common patterns, Spacelift Templates let you define reusable stack configurations so teams can provision consistently without starting from scratch.
And with Spacelift Intelligence, teams get AI-powered diagnostics and operational insight across both traditional and AI-driven workflows, helping surface issues and accelerate troubleshooting.
Supply chain management platform Logixboard was a Terraform Cloud customer seeking a more reliable Terraform experience. By migrating from Terraform Cloud to Spacelift, they have slashed the time they spend troubleshooting deployments, freeing them for more productive work.
If you are interested in learning more about Spacelift, create a free account today or book a demo with one of our engineers.
Key points
Structuring a Terraform project is that aspect of IaC adoption that is realized in the later stages when the infrastructure design tends to grow. It is important to understand the files created and automatically generated by a generic Terraform project setup so that the customizations are implemented in a way that is more maintainable and easy.
In this post, we discussed how complexity quickly increases in growing projects. We also discussed a few approaches to manage the same via structuring the files based on services being supported or the nature of infrastructure components being managed.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Terraform management made easy
Orchestrate Terraform workflows with policy as code, programmatic configuration, context sharing, drift detection, resource visualization, and more.
Frequently asked questions
Does Terraform care what you name *.tf files?
No. Terraform loads all *.tf files in the current working directory and evaluates them as a single configuration. Filenames like main.tf, variables.tf, and outputs.tf are conventions for readability, not requirements.
In what order does Terraform read *.tf files?
In practice, the order doesn’t matter. Terraform evaluates the module directory as one configuration and builds a dependency graph from references between resources, data sources, and modules — not from filenames. (Override files like override.tf and *_override.tf are a special case and are processed after the rest, in lexicographical order.)
What’s the minimum set of Terraform files for a new project?
You can start with a single main.tf. A common baseline as things grow is:
- main.tf for resources and module calls
- variables.tf for input variables
- outputs.tf for outputs
- versions.tf (or providers.tf) for terraform {} and provider requirements
This layout is a convention, but it scales well.
Where should the terraform {} block live?
terraform {} block can live in any *.tf file in the root module. Many teams put required_version, required_providers, and the backend configuration in versions.tf (or providers.tf) so it’s easy to find during reviews.
Should I commit .terraform.lock.hcl?
Yes, you should commit .terraform.lock.hcl. Terraform recommends keeping it in version control so provider selections and checksums stay consistent across machines and CI, and changes can go through review.
What Terraform files should not be committed to Git?
Generally, you shouldn’t commit:
- .terraform/
- *.tfstate and *.tfstate.* (including backups)
- crash logs
- override files (override.tf, *_override.tf, and their .tf.json equivalents)
State should usually live in a remote backend rather than your repo.
Why doesn’t Terraform load *.tf files from subdirectories?
Terraform only auto-loads the top-level configuration files in the module directory you run from. Subdirectories are separate modules and are only included when you call them explicitly with a module block (for example, source = “./modules/vpc”).
