
When you run Terraform on your own, storing state locally works fine. But as soon as a second engineer runs terraform apply on the same project, things can go wrong fast. Conflicting state files, accidental overwrites, and infrastructure drift are all common consequences of unmanaged local state.
Remote state solves this by storing your state file in a shared, centralized backend with built-in locking, encryption, and access control. It is the standard approach for any team managing infrastructure with Terraform and a prerequisite for safe collaboration at scale.
In this guide, we will cover:
- What is a Terraform remote state?
- Benefits of using Terraform remote state
- How to set up Terraform remote state
- How to access Terraform remote state
- Alternative ways to share data
- Terraform remote state with Spacelift
The source code used in this article is available here:
What is a Terraform remote state?
Terraform remote state allows the storage of state information about your infrastructure resources in a remote data store. It offers security and protection against corruption when you work on Terraform projects in a collaborative environment.
Terraform supports multiple platforms, such as AWS S3 and Azure Blob Storage, for managing remote state backends. The Terraform binary has incorporated the APIs exposed by these platforms to perform state management.
By adopting remote state management, teams can unlock enhanced collaboration, version control integration, and a more robust foundation for their infrastructure projects. On the one hand, Terraform’s remote state avoids race conditions by prioritizing execution requests using a FIFO approach. On the other hand, the backends offer stringent security control to prevent unintended access.
What is the difference between the remote and local state in Terraform?
By default, a local state backend is configured for any Terraform project. The local state is stored on the local machine where Terraform is run, while the remote state is stored in a shared backend for enhanced collaboration, security, accessibility, and state locking.
Benefits of using Terraform remote state
Some of the remote state key features and benefits include:
1. Concurrency and collaboration
The remote state enables multiple team members to work concurrently on the same infrastructure codebase without conflicting state changes. This eliminates the risk of accidental overwrites and ensures a smooth collaborative workflow.
2. Centralized storage
Remote state stores Terraform state files in a central, secure location, such as an object storage service. This prevents state files from being lost or corrupted due to local machine failures.
3. Security and access control
Remote state solutions often come with access controls, allowing you to restrict who can read or modify the state, which includes sensitive infrastructure information. This also limits the risk of accidentally deleting or misplacing the state files.
4. Cross-team and cross-project consistency
When working on multiple projects or with different teams, the Terraform remote state ensures consistency across environments by storing a single information source for your infrastructure configuration.
5. Disaster recovery and replication
Many remote state solutions offer disaster recovery features, such as automated backups and cross-region replication. This ensures that your state data remains resilient even in the face of unexpected outages.
6. Remote operations
Some Terraform remote state backends offer remote execution of Terraform operations, which can be especially useful when you want to keep the execution environment separate from your local machine.
Incorporating remote state management into your Terraform workflows offers the benefits mentioned above and more, making it an essential practice for modern infrastructure provisioning and management. The choice of backend for managing remote state files depends on two factors:
- How the backend performs remote operations – the ability to execute apply and destroy operations along with the general plan and state query operations. Typically, state queries are fundamental requirements of any backend, and operational abilities are optional.
- Storage encryption and locking – you often want the project state file to be stored, retrieved, and updated securely. Thus, encryption at rest and in transit becomes important. Additionally, the remote backend should also provide state file-locking functionality to avoid race conditions – which can potentially corrupt the state files.
The limitations of managing the Terraform state file locally
A few drawbacks of managing the state file locally are:
- Issues with team collaboration – When working in a team, each developer maintains their version of the state file depending on the modifications to the Terraform configuration they perform. This introduces inconsistencies and results in undesired/unexpected duplication or destruction of cloud resources.
- Cannot be shared as part of Git repo – State files contain sensitive information that is stored in plain text. It is not recommended to commit this file in Git VCS, as it may expose these secrets and sensitive values to unintended audiences.
- Race conditions – Even if we manage to overcome the secure sharing of state files between developers, local state management does not address the issue of race conditions. Multiple developers attempting to run Terraform operations simultaneously can result in unexpected results and errors.
The drawbacks described above are serious issues; however, implementing remote backends addresses all of them.
Remote state backends also enable cross-team collaboration capabilities by using the terraform_remote_state data source. When multiple Terraform configurations are being developed by separate teams, the dependencies are managed using this data source. We will take a look at it in detail in the next section.
How to set up Terraform remote state
To understand how remote state backends work and how to configure one, let’s first see how the default – local – state works.
As discussed in the previous section, two main features that Terraform state management depends on are the ability to query state information and storage and locking features.
The state backend configurations are done in the provider block of a Terraform project. If no backend configuration block exists in this block, it is understood to have a default state managed locally within the project’s directory.
Take a look at an example Terraform configuration below:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.44"
}
}
}
resource "aws_instance" "my_vm" {
ami = var.ami //Ubuntu AMI
instance_type = var.instance_type
tags = {
Name = var.name_tag,
}
}When this configuration is initialized and planned (with terraform plan command), it downloads the requested Terraform provider module – in this case, “hashicorp/aws” v6.44 module and stores it in .terraform directory in the project root. It also creates terraform.tfstate and .terraform.lock.hcl files to store the state information and enable the locking functionality.
Versions used in this guide: Terraform v1.10+, hashicorp/aws provider v6.44.0. Configuration syntax and backend behavior may differ on older versions. Always check the AWS provider changelog when upgrading across major versions.
The current project directory should look as in the screenshot below.

Add the backend resource block to our provider configuration to configure a remote state backend for this project. The backend of our choice here is the AWS S3 bucket, as seen in the code below.
Some of the attributes and their purposes:
bucket– the name of the bucket where state files will be storedkey– the path to the state file within the bucketregion– AWS region where this bucket existsuse_lockfile– enables native S3 state locking (set to true)encrypt– encrypts the state file at rest
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.44"
}
}
backend "s3" {
bucket = "tfremotestate-ec2"
key = "state"
region = "eu-central-1"
use_lockfile = true
encrypt = true
}
}When we use S3 as the backend, Terraform automatically handles the storage and locking features.
Note: Since Terraform 1.10, the S3 backend locks state natively when you set use_lockfile = true, so a separate DynamoDB table is no longer required. DynamoDB-based locking still works through the dynamodb_table argument, but that argument is deprecated as of Terraform 1.11 and will be removed in a future version. To migrate without downtime, set both use_lockfile = true and dynamodb_table for a transition period, then drop dynamodb_table once every machine runs Terraform 1.11 or later.
Refer to this document for information about additional features related to s3 and support available for other backends. (See also the Terraform s3 backend best practices.)
In our case, Terraform internally handles the logic to store, manage, and lock state using AWS APIs. For other supported backends, Terraform handles the same internally with corresponding APIs.
If we now try to run the terraform plan command after enabling this backend, it will throw an error:
terraform plan
╷
│ Error: Backend initialization required, please run "terraform init"
│
│ Reason: Initial configuration of the requested backend "s3"
│
│ The "backend" is the interface that Terraform uses to store state,
│ perform operations, etc. If this message is showing up, it means that the
│ Terraform configuration you're using is using a custom configuration for
│ the Terraform backend.
│
│ Changes to backend configurations require reinitialization. This allows
│ Terraform to set up the new configuration, copy existing state, etc. Please run
│ "terraform init" with either the "-reconfigure" or "-migrate-state" flags to
│ use the current configuration.
│
│ If the change reason above is incorrect, please verify your configuration
│ hasn't changed and try again. At this point, no changes to your existing
│ configuration or state have been made.This is expected — since we have added a new backend setting in the provider block, Terraform has detected the same and asked us to reconfigure the backend with the “-migrate-state” flag. Doing this would let Terraform connect to the specified S3 bucket, and transfer the state files in that bucket.
terraform init -migrate-state
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- terraform.io/builtin/terraform is built in to Terraform
- Reusing previous version of hashicorp/aws from the dependency lock file
- Using previously-installed hashicorp/aws v6.44
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.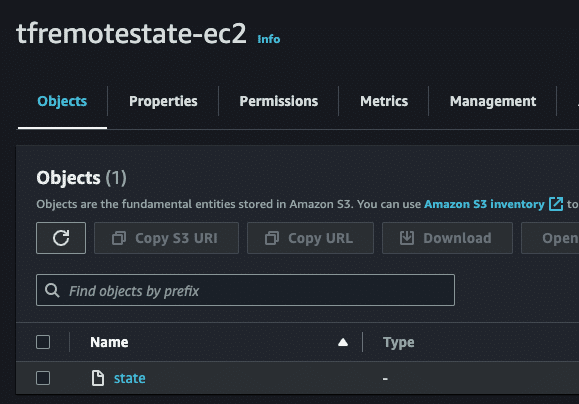
All the Terraform operations would refer to this state file in the S3 bucket. We have successfully migrated the state from our local backend to the remote backend.
It is also possible to migrate it back locally by simply removing the backend “s3” block from the provider and running terraform init again with “-migrate-state” flag. Read more: How to Migrate Terraform State Between Different Backends
Also, while the state is being stored in the remote backend, it is possible to manually pull the state file locally to perform any desired tasks based on the information.
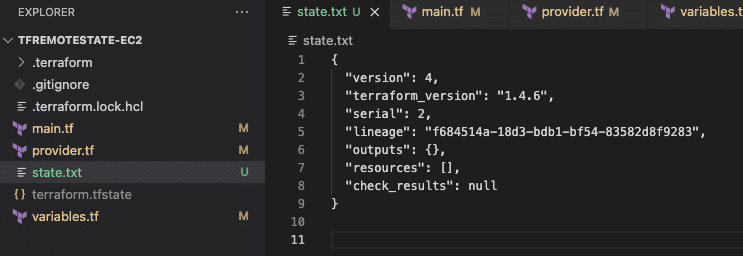
For example, running the command below pulls and stores the state in the “state.txt” file in the project root directory. A manual push is also possible, but doing so is highly discouraged.
terraform state pull >> state.txtThe screenshot below shows that we have pulled the state into our project root directory. The state contains no resources since we have not yet applied any configuration.
How to access Terraform remote state
When Terraform projects grow large, it’s recommended to modularize them by logically separating cloud infrastructure components into multiple projects. For example, when responsibilities for managing compute, storage, databases, and networking requirements are distributed among different teams. In such cases, each team maintains a separate Terraform repository and, as a result, a separate state file.
To manage dependencies, each Terraform project may need access to state information from other projects. There are two ways to achieve this:
- Access the state file of other projects using terraform_remote_state data source.
- Use resource specific data sources to query from the cloud platform directly.
The second option is the recommended approach since accessing the state files might have security drawbacks. Read more about Terraform data sources and examples.
Let’s assume that the VPC and subnet configurations are being managed by a different team in a separate repository. Our task is to provision compute resources (EC2 instances) in each subnet of the VPC, which is maintained in a separate repository.
To fetch the subnet information from the state file of the VPC project, first, the VPC project has to expose that information using output variables – as seen here, and in the code below:
output "subnets" {
value = [aws_subnet.public_a.id, aws_subnet.private_a.id]
}
output "subnet_pub_id" {
value = aws_subnet.public_a.id
}
output "subnet_pri_id" {
value = aws_subnet.private_a.id
}Here, the VPC project has exposed subnet ids in two ways – a list(string) and individual subnet id variables in the form of string.
Next, in our compute Terraform project, we declare a data source to fetch this information from VPC project’s state file.
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "tfremotestate-vpc"
key = "state" // Path to state file within this bucket
region = "eu-central-1" // Change this to the appropriate region
}
}
output subnet_ids {
value = data.terraform_remote_state.network.outputs.subnets
}This data source is configured to access the S3 backend of the VPC project by providing the corresponding bucket name, key, and region attributes. We have also declared the output variable to read the value from this data source to output the “subnets” information, which is exposed as a list(string) in the previous code sample (VPC project).
Running terraform plan reveals the subnet IDs:
.
.
.
+ user_data_replace_on_change = false
+ vpc_security_group_ids = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ subnet_ids = [
+ "subnet-0fad314b1f1e652bc",
+ "subnet-03a33174741fd9cb4",
]Now that we have subnet information in our compute project, we can update the EC2 resource (aws_instance) to create EC2 instances in each subnet.
The code below demonstrates the usage of for_each loop to dynamically create these compute EC2 instances. The advantage of this approach is that the configuration becomes dynamic. Tomorrow, if the VPC project decides to add additional subnets, then more EC2 instances will be automatically created in them.
resource "aws_instance" "my_vm" {
for_each = toset(data.terraform_remote_state.network.outputs.subnets)
ami = var.ami //Ubuntu AMI
instance_type = var.instance_type
subnet_id = each.key
tags = {
Name = var.name_tag,
}
}Alternative ways to share data
Accessing Terraform state files via the terraform_remote_state data source is not recommended. There are several approaches to accessing the resource data instead.
First, use custom or 3rd-party tools to make state file information available securely for consumption, for example, the Consul (by HashiCorp) key-value store. But organizations can also develop or reuse in-house solutions to expose this data via APIs, ensuring it is encrypted in transit and at rest.
The second way is to use the Terraform data sources available in the Terraform registry for each resource type. In this case, the data sources used directly query the Cloud Platform APIs with appropriate filters and fetch only the required data.
In the example discussed above, replace the terraform_remote_state data source with the one that gets the subnets information for a given VPC ID.
To configure the data source for retrieving Subnets information from AWS, replace the terraform_remote_state data source with the one below:
data "aws_subnets" "my_subnets" {
filter {
name = "vpc-id"
values = ["vpc-0cb1aa34b173b1bb6"]
}
}Here, we are using aws_subnets data source. It is assumed that we know the value of VPC Id, and thus, we have set the filters appropriately. So, if multiple VPCs are present in this AWS region, the data source will retrieve only the relevant subnet ids.
Adjust the aws_instance configuration to use this data source instead.
resource "aws_instance" "my_vm" {
for_each = toset(data.aws_subnets.my_subnets.ids)
ami = var.ami //Ubuntu AMI
instance_type = var.instance_type
subnet_id = each.key
tags = {
Name = var.name_tag,
}
}The rest of the logic remains the same for aws_instance resource. This enables us to query for specific information via AWS APIs, which are secure in nature.
Terraform remote state best practices
Here are the key practices to follow when managing Terraform remote state in collaborative environments.
- Always enable state locking –With the S3 backend, enable native locking by setting use_lockfile = true. A separate DynamoDB table is no longer required, and the
dynamodb_tableargument is deprecated as of Terraform 1.11. - Encrypt state at rest and in transit – State files store sensitive values like resource IDs, passwords, and private IPs in plain text. Always enable encryption in your backend configuration and enforce it at the bucket or storage level as a secondary safeguard.
- Use a dedicated state bucket with least-privilege IAM policies – Storing state in a general-purpose bucket increases the risk of unintended access or modification. Create a dedicated bucket for Terraform state, restrict access to only the specific S3 permissions each role requires (plus DynamoDB permissions if you still rely on legacy DynamoDB locking), and enable bucket versioning to allow recovery from accidental corruption or deletion.
- Organize state files by environment and component – A single state file for your entire infrastructure increases the risk of unintended changes across unrelated resources. Use a path structure that reflects your environment and component, for example
myapp/prod/networking/terraform.tfstate, so that each team or service manages its own isolated state. - Prefer cloud data sources over
terraform_remote_statefor cross-team sharing – Theterraform_remote_statedata source requires read access to another team’s full state file, which may expose unrelated sensitive outputs. Where possible, use native cloud data sources likeaws_vpcoraws_subnetsthat query the provider API directly and return only the values you need. - Use CLI commands to manage state, never edit it manually – Manual edits to state files are a common cause of drift and corruption. Use
terraform state mvto rename or move resources,terraform state rmto remove resources from state without destroying the underlying infrastructure, andterraform importto bring existing resources under Terraform management.
Terraform remote state with Spacelift
One of the ways to classify remote backends based on the features provided is their ability to run operational commands executed by Terraform. There are two main categories:
- Regular backends that provide the function to store, update, and lock state files on their infrastructure. Any Terraform CLI command to interact with state files works as far as we are querying or updating the state files. However, these backends do not have the ability (compute resources) to execute operations like apply and destroy. AWS S3 is an example of a regular backend.
- Enhanced backends – also known as “remote” backends in the provider configuration. Along with state file storage and management capabilities offered by regular backends, these backends also provide the required compute resources to execute, plan and destroy operations.
Note that not all “remote” backends provide this enhanced functionality. Operational capabilities are additions on top of the state management features.
Spacelift offers enhanced backends in the form of remote backends. To configure Spacelift’s remote backend, use the backend block as shown below.
terraform {
backend "remote" {
hostname = "spacelift.io"
organization = "letsdotech"
workspaces {
name = "mycomputeresources"
}
}
}If we use Spacelift as a remote backend, the hostname would always remain the same – “spacelift.io”.
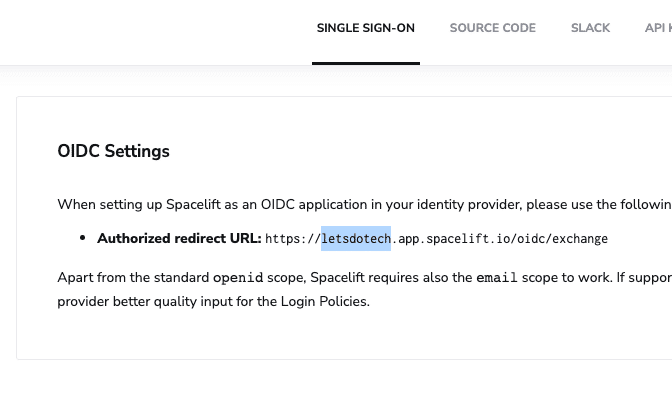
Organization is the name we used while signing up with Spacelift. It is also visible as part of the URL while accessing the dashboard. For example, we have used the organization’s name, “letsdotech,” as shown in the highlighted section of the screenshot below.
To access the state file using the terraform_remote_state data source, declare it as shown below.
Notice the difference between this data source when we tried to access the state file from the S3 backend and the Spacelift’s remote state. In the example below, we provide configs related to the remote state, as discussed in the previous paragraph.
data "terraform_remote_state" "mycomputestate" {
backend = "remote"
config = {
hostname = "spacelift.io"
organization = "letsdotech"
workspaces = {
name = "mycomputeresources"
}
}
}The rest of the state manipulation operations would carry on the way they are carried for the S3 backend in the previous example. For more information, refer to this blog post, which shows in detail Spacelift’s remote state capabilities.
If you need any additional help managing your Terraform infrastructure, building more complex workflows with Terraform, or managing AWS credentials per run instead of using a static pair on your local machine, Spacelift is a fantastic tool for this. It supports Git workflows, policy-as-code, programmatic configuration, context sharing, drift detection, and many other great features right out of the box.
You can create a free account today, or book a demo with one of our engineers to learn more.
Key points
As we have seen in this post, by storing our state files in a secure, accessible location, we mitigate the risks of version conflicts, accidental deletions, and unauthorized access. This promotes collaboration within teams and across projects, ensuring a more efficient and organized development environment. As the cloud infrastructure projects grow, harnessing the power of remote state not only optimizes our workflows but also lays the foundation for scalable, consistent, and dependable infrastructure deployments.
The benefits of the Terraform remote state include improved collaboration and reduced human errors to enhanced auditability and traceability. By offloading the management of our state to dedicated, secure backends, we are not only ensuring the stability of our deployments but also gaining the ability to focus on the strategic aspects of our infrastructure architecture.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Terraform management made easy
Orchestrate Terraform workflows with policy as code, programmatic configuration, context sharing, drift detection, resource visualization, and more.
Frequently asked questions
Is Terraform remote state supported in OpenTofu?
Yes. OpenTofu supports the same backend types as Terraform, including S3, Azure Blob Storage, and Google Cloud Storage. The backend configuration syntax is identical, so existing configurations can be used without modification.
What happens if the Terraform state file gets corrupted?
If you have versioning enabled on your S3 bucket, you can restore a previous version of the state file directly from the AWS console or using the AWS CLI. This is one of the main reasons bucket versioning is strongly recommended. If versioning is not enabled and the file is corrupted, you may need to manually reconstruct the state using terraform import for each affected resource.
Can multiple teams share the same state file?
It is possible but not recommended. Sharing a single state file across teams increases the risk of conflicts and unintended changes to unrelated resources. The better approach is to split infrastructure into separate components, each with its own state file, and use cloud data sources or well-defined output variables to share only the values that other teams need.
Terraform Docs. Backend Type: s3. Accessed: 26 June 2026
Terraform Docs. The terraform_remote_state Data Source. Accessed: 26 June 2026
Terraform Docs. State: Remote Storage. Accessed: 26 June 2026
