
Organizations using Terraform to manage their infrastructure as code (IaC) need a reliable solution to ensure their infrastructure’s actual state aligns with its intended state.
Terraform stores information about the infrastructure it manages in state files, and any change to the infrastructure Terraform manages that Terraform has not triggered is called “drift.”
In this post, we will explore the reasons why drift happens, its associated risks, and the options available to remediate it.
What we will cover:
TL;DR
- Terraform drift is when real infrastructure no longer matches what your Terraform configuration/state expects (often due to manual changes or external automation).
- Detect drift by running
terraform plan(orterraform plan -refresh-onlyto update state from real resources without proposing changes to infra). Remediate it by either applying the desired config (terraform apply), importing/adopting the current reality (terraform import), or correcting state if needed. - Prevent recurrence by restricting manual changes and standardizing changes through PRs and Terraform runs, and automate detection with scheduled plans and alerts (and optionally automated reconciliation) using CI or a platform like Spacelift.
What is Terraform drift?
Terraform drift refers to the situation where the actual state of infrastructure in an environment diverges from the state defined in Terraform configuration files. Drift can happen due to changes outside of the Terraform workflow, such as manual modifications, automated external processes, or resource eviction.
- Manual changes: As a DevOps engineer, when you have severity one issues, you may make manual changes just to get the systems up and running, but this also means that you have to make these changes in the code afterward. Sometimes, you forget that you’ve made these changes, and your configuration will drift.
- External processes: You may have automated processes outside Terraform’s control, such as autoscaling actions triggered by cloud providers or external scripts that make changes to your infrastructure.
- Resource eviction: Due to cost-saving measures and policy violations, resources can be evicted or deleted, which can cause drift.
Drift is a significant concern that can lead to inconsistencies, complicating infrastructure management.
Watch the video below to see why Terraform drift is riskier than it looks:

Common sources of infrastructure drift
Consistency is a key goal when managing infrastructure using Terraform. With IaC, you can keep multiple environments consistent, irrespective of how many times they are recreated.
Infrastructure drift undermines that consistency. Here are some of its common sources:
Manual changes
Manual changes are a primary cause of infrastructure drift. These can be made either deliberately or unintentionally.
If a deployed system’s configuration needs to be changed to address a critical production incident, doing it manually can be the fastest way to fix it. Similarly, certain network configurations are tweaked for testing purposes to address a certain network security vulnerability. These are examples of intentional manual changes to the infrastructure.
However, sometimes users are not even aware they have made a manual change to the infrastructure. Identifying the components managed by Terraform is not always intuitive. When users log into the web console, they may perform specific tasks on resources without the knowledge of Terraform’s state file. Executing scripts that make API calls to the cloud platform is another possible source of unintentional change.
Irrespective of whether the change is deliberate or unintentional if the changes are not ported back into the Terraform configurations, this results in drift.
Automation tools
Organizations and large teams implement multiple automation tools to streamline operations. These tools all have specific workflows and lifecycle management capabilities, and responsibilities can overlap if boundaries of influence for these tools are unclear or wrongly implemented.
For example, using Terraform for infrastructure management alongside a configuration management tool like Ansible creates a high possibility of infrastructure drift. Although Ansible is responsible for managing the application layer of a business service, it also has infrastructure provisioning capabilities.
Ironically, the more automation tools you implement, the more manual effort is required to reconcile the changes they create in Terraform state files.
User scripts
Cloud platforms enable the triggering of user-defined scripts that are event-driven. These scripts allow users to perform actions on a resource or execute API calls to modify another resource.
For example, when creating Linux-based EC2 instances in AWS, it is possible to execute bash/shell scripts when the instance boots. These scripts are provided in the user_data field when creating an instance from the web console. Similarly, Terraform provides a way to supply the same using IaC.
Although providing user_data is not mandatory, it enables various automation capabilities to manage virtual machines. User_data scripts are used to run upgrades, install security patches, install dependencies, invoke various system processes, etc., as soon as the system boots.
Bash and shell scripts are powerful because they can change any network configuration of the system and execute API calls to modify other resources. This has the potential to introduce drift in infrastructure.
Risks and impact of infrastructure drift
Terraform IaC manages the infrastructure’s end-to-end lifecycle. It is responsible for creating and recreating cloud resources, as well as consistently introducing changes. To do this successfully, up-to-date information is saved in the state files.
Essentially, infrastructure drift is untracked changes. These untracked changes pose risks of varying severity and could have a drastic impact on the system. Similarly, some changes may be beneficial for the system, improving attributes like reliability, security, and performance.
Given the nature of infrastructure drift in the context of Terraform IaC, if it’s not addressed, it can create blind spots while managing the infrastructure in scope. Infrastructure changes that fall out of the scope of Terraform management go unnoticed.
Security vulnerabilities
Infrastructure drift exposes the system’s security vulnerabilities to attackers. This has the potential to cause serious damage not just to the system but to businesses in general. For example, when security group rules are manually modified to test a certain use case for public access, this can have multiple impacts, ranging from data breaches to the entire system being compromised.
Compliance violations
Automated policy execution or manual configuration changes can lead to breaches of regulatory requirements — for example, drift that results in the personal data of users being exposed to the public or actions that enable unauthorized access to data and resources.
Performance and operational difficulties
Infrastructure drift can impair system performance because of latency or reduced network throughput, underprovisioning of resources, disabling of auto-scaling configurations, etc. Drift also makes it challenging to identify, analyze, and investigate the root cause of the issues. Unknown and untracked changes introduce challenges that increase downtime and also impact the mean time to resolution.
Higher costs
Changes caused by infrastructure drift can have wide-ranging financial implications. Provisioning of unutilized cloud resources generates unnecessary cloud platform costs, and, because the changes are not tracked, the cost of remediation and maintenance also increases.
You can learn more about drift in this article: Infrastructure Drift Detection and How to Fix It With IaC Tools.

Example: How does Terraform drift look in practice
Imagine you deploy a production VPC and a set of EC2 instances with Terraform. Everything is clean, reviewed, and in sync with your Git repo. A week later, an on call engineer gets paged about high CPU and fixes it quickly in the AWS console instead of going through Terraform.
What happens:
- Initial state: Terraform code sets an Auto Scaling Group with
max_size = 5. The change is applied, and the Terraform state matches what runs in AWS. - Out of band change: During an incident, the engineer opens the AWS console, edits the Auto Scaling Group, and increases
max_sizeto 10 to handle a traffic spike. They forget to make the same change in Terraform. - Drift appears: In AWS, the Auto Scaling Group now has
max_size = 10. In the Terraform code and state, it still saysmax_size = 5. Your infrastructure has drifted away from the desired IaC definition. - Drift detection: The next time you run
terraform plan, Terraform shows a change that looks like this:~ max_size = 10 -> 5. This is Terraform telling you that the live configuration is different from what your code expects. - Decision point: You now have to choose:
- Update the Terraform code to
max_size = 10and apply it so the state matches reality. - Or keep
max_size = 5in code, apply, and intentionally roll the autoscaling limit back down.
- Update the Terraform code to
This is Terraform drift in practice. Someone changes cloud resources directly, Terraform does not know until you compare desired state to live state, and you only regain control when you update code or apply a plan.
How to detect Terraform drifts?
When infrastructure drift occurs, the first challenge is to identify it. As we have seen, drift has multiple sources, so it is not possible to track where and when the drift happens without a monitoring mechanism.
You can identify the existence of drift by running a couple of Terraform commands. The recommended way to surface drift with the Terraform CLI today is:
terraform plan— implicitly refreshes state in memory and shows any differences between configuration, state, and real infrastructure.terraform plan -refresh-only— explicitly refreshes state and shows the changes that would be written to the state file without proposing infrastructure changes.
The older terraform refresh subcommand is deprecated and should be avoided in favor of using the -refresh-only flag with terraform plan.
Without changing the Terraform config, if the execution of a plan command suggests either modifying or recreating a certain resource, this indicates that something else has modified the infrastructure. But this depends on when exactly the commands are run. It often happens when we prepare and check the status before implementing other intended changes.
The same principles apply if you’re using OpenTofu instead of Terraform. Commands and flags are compatible because OpenTofu is forked from Terraform 1.5.6.
Monitoring drift with Spacelift
Spacelift has built-in drift detection for Terraform and other IaC tools. Behind the scenes, it periodically runs proposed runs against your stable stack state (on private workers) and checks for any differences.
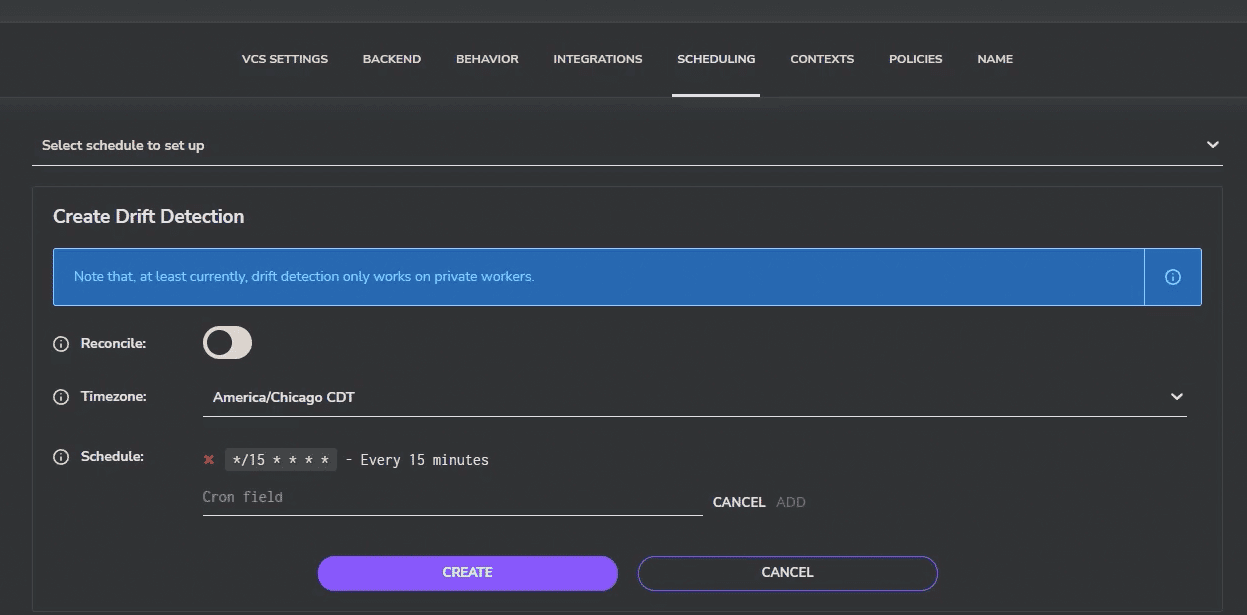
You can configure multiple cron-style schedules, decide whether detection should automatically trigger tracked “reconcile” runs, and manage all of this either in the UI (Settings → Scheduling) or as code using the spacelift_drift_detection Terraform resource.
To start, select the stack you wish to configure drift detection for and navigate to Settings > Scheduling. A couple of notable control options are provided here:
- Reconcile: When this is enabled, Spacelift automatically remediates the drift. When infrastructure drift is identified, Spacelift triggers the “terraform apply” workflow to restore the original state of infrastructure as per the Terraform configuration.
- Schedule: This is a simple cron job notation that determines the scanning frequency and compares the state of deployment. In the example below, the drift detection happens every 15 minutes.
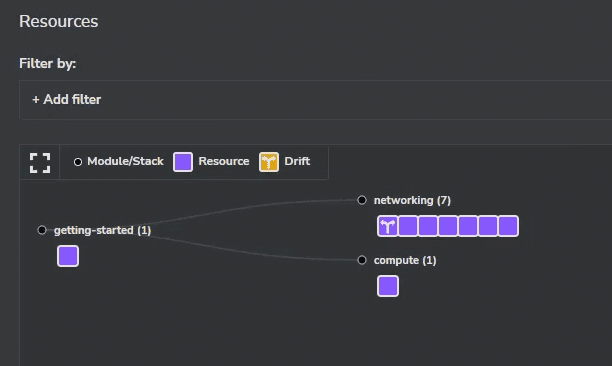
When drift is detected, it is represented in a very intuitive way, making it easy to interpret its impact.
The screenshot below shows that one of the network components has drifted.
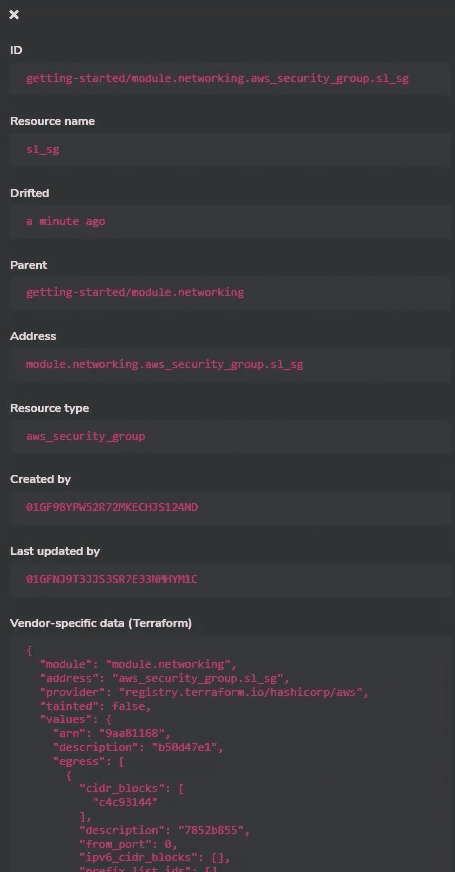
Clicking on the drifted block quickly reveals details of the drift.
Read more in the documentation.
How to fix Terraform drift with Spacelift?
Whenever drift is detected, it is important to identify the factors that caused it. As previously discussed, changes introduced outside the scope of Terraform could be either desirable or unwanted. Here are some examples:
- Changes caused by the scopes of automation tools overlapping are usually desirable. However, the responsibility is not clearly defined.
- Changes introduced manually to troubleshoot a related issue elsewhere but overlooked and not reverted are unwanted because they expose the system to various vulnerabilities and could have cost implications.
- Hotfixes implemented to address issues in critical services can be either permanent fixes or temporary workarounds, which makes it difficult to classify them as either desirable or unwanted. Further investigation is needed to decide.

“With Spacelift, one of the first things we did was a big drift detection. We overhauled our drift detection, drift remediation, how to handle and solve it, and how to prevent it from happening. Spacelift handles all of that for us automatically now.” - Trevor Rae, Cloud Platform Engineer, 1Password
As seen from the examples above, understanding drift needs some analysis. The course of remediation action usually boils down to the following:
- If the changes are desirable, import the configuration under Terraform management scope.
- If the changes are not desired, reinstate the original state by running “terraform apply”.
- If a resource is not supposed to be managed by Terraform, disassociate it from Terraform state and configuration.
When drift detection is enabled, Spacelift highlights the drift in the very next run. It depends on how frequently the drift detection runs are configured. When we enable the “Reconcile” option in the drift detection schedule, Spacelift automatically triggers Terraform runs to reinstate the original configuration. This is appropriate when the scope is clearly defined, and resource management policies are in place.
However, if the boundaries are not clearly defined, you should turn off the “Reconcile” option. This is because there may be a need to either import drift or disassociate infrastructure from the current Terraform configuration. The drift detection schedule again plays an important role in confirming mitigation actions post-import/disassociation.
Would you like to see it in action, or just want a tl;dr? Check out this video, where we demonstrate how drift can be automatically detected and remediated with Spacelift:

Terraform drift detection tools
Here are the main options and supporting tools you can use for Terraform drift detection:
- Terraform built in workflows – Running
terraform planon a schedule is the baseline way to spot drift, since any out of band change will show up as proposed updates. This works well if you already have automation that runs plans regularly and surfaces the results. - Drift-focused tooling – Tools such as driftctl are built specifically to detect AWS, GCP, or Azure resources that are unmanaged or out of sync with your Terraform code, helping you see which parts of your estate have quietly escaped IaC control.
- Testing and validation in your pipeline – While not drift tools by themselves, test frameworks like Terratest, TestInfra, and Kitchen Terraform help you enforce that your Terraform changes produce the expected infrastructure and behavior. Combined with scheduled plans, they form a safety net: plans catch state drift, tests catch broken assumptions about how that state should behave.
- GitOps and CI based checks – CI pipelines such as GitHub Actions, GitLab CI, or Jenkins can periodically run
terraform planand alert when there are unexpected changes. You get flexibility and reuse of your existing CI stack, but you are responsible for wiring up scheduling, storage, and alerting. - Specialized IaC management platforms – Platforms like Spacelift focus on Terraform and other IaC tools and can continuously compare live infrastructure with your desired state. They highlight drift, show clear diffs, and can hook into approval and remediation workflows instead of leaving you to parse raw plans.
Whichever mix you choose, the goal is the same: make drift detection automatic, visible, and part of your normal Terraform workflow so you do not waste time debugging “random” production issues that are really just infrastructure changes behind Terraform’s back.
Key points
Managing infrastructure drift is challenging because it may originate from any source. It is difficult to get absolute certainty of who changed what and when. The risk potential of such drift can range from low to critical, and the impact can affect the system’s security, cost, and reliability.
Terraform IaC and state files are the only reliable and predictable sources of information about the managed infrastructure. Spacelift’s drift detection encompasses monitoring and an intuitive UI to highlight the drift (and optionally automate the reconciliation). This makes it easy to identify what has changed and how to proceed with investigating it.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Detect and remediate drift with Spacelift
Drift happens, so let Spacelift deal with it. Spacelift provides drift detection and remediation for any infrastructure as code provider, helping you maintain the desired state for your infrastructure across teams, applications, and clouds.
Frequently asked questions
How do I detect Terraform drift automatically?
To detect Terraform drift automatically, use terraform plan in combination with remote state and scheduled checks in your CI/CD pipeline or a monitoring tool.
Should I auto-remediate Terraform drift?
Auto-remediating Terraform drift is generally not recommended in most production environments due to the potential for unintended changes and outages. Auto-remediation may be appropriate in tightly controlled, low-risk environments where infrastructure changes are fully automated and predictable.
Does drift detection apply to OpenTofu as well?
Yes, drift detection applies to OpenTofu just as it does to Terraform. Running opentofu plan will detect drift by comparing the current infrastructure state (from the state file and real-time cloud queries) with the declared configuration.
