
Infrastructure drift can significantly disrupt IT operations, causing a ripple effect across your reliability, visibility, governance, and even costs. Drift may start as a small inconvenience, but over time, these differences increase and lead to unexpected behaviors and vulnerabilities and bypass established processes.
Understanding the primary causes of infrastructure drift is essential to preventing it and maintaining a reliable and governed cloud environment.
What is infrastructure drift?
Infrastructure drift refers to changes made to your infrastructure outside your IaC processes that result in differences between the desired state of your infrastructure and the actual state. Drift can arise from various sources, such as manual fixes, ad-hoc changes, or updates made in response to critical issues, all of which bypass IaC workflows.
Read more about how drift can affect your organization.
What can cause infrastructure drift?
Cause 1: High-severity issue that needs to be fixed
You have a high-severity issue that causes downtime or performance issues. In this case, you have to fix it as soon as possible, often working around your IaC or change management processes. This usually means that you will do it manually. At this point, you have introduced drift because your IaC state doesn’t reflect the real state of your infrastructure.
You should note this change and implement it as soon as possible in your IaC, but this rarely happens. As soon as you rerun your infrastructure pipelines, you will reintroduce the initial high-severity issue and have to fix it again. If only there were a system you could use to prevent this.
Cause 2: Frustration with using set processes/tools vs the easy way
Implementing processes is a great way to avoid infrastructure drift. But what about processes that are too complex?
If you can’t experiment with small changes you want to make, you must decide either to waste time going through the process for something very small, or be more practical and just make the change. Most engineers will select the second option, but the consequences can be severe. In this case, the process needs fine-tuning, as practitioners are frustrated with it, and the process itself is actually causing drift.
Cause 3: Human errors
Engineers make mistakes. Even the most experienced ones are prone to error, especially under pressure. Overlooked details can quickly lead to discrepancies between the desired state of your IaC and the actual infrastructure.
These mistakes can be trivial in the beginning, but they can increase over time, leading to considerable drift. The best approach is to implement shift-left mechanisms that deal with human error and ensure that drift is kept to a minimum.
Cause 4: Edge cases that require making quick changes
This cause is pretty similar to the high-severity issue that needs to be fixed. An unexpected security vulnerability can feel urgent, even if it hasn’t been exploited yet, so engineers will feel compelled to solve it as soon as possible. Again, this means they will do something outside the process, introducing drift. Although it’s crucial to resolve these kinds of issues fast, it’s equally important to track them and integrate them into IaC fast.
Cause 5: Lack of automation
If your infrastructure lacks automation, it’s hard to keep track of the IaC state and its actual state. If engineers are all running IaC from their local machines without a state locking mechanism, this will not only introduce drift, but also probably create a huge blast radius. Automation is essential for maintaining your infrastructure accuracy, and having a mechanism that continuously checks for drift will solve this issue.
Cause 6: API changes
APIs evolve over time, so you need to ensure that you are using fixed versions for IaC tools and providers. An outdated API might no longer support certain configurations, leading to discrepancies in your infrastructure state.
As a best practice, you should strive to stay on top of these changes, and whenever you upgrade the versions you are using, be mindful of all the configuration changes you have to make.
Cause 7: Poor access control management
If everyone can make changes, then everyone will, and this will create chaos (and drift, of course). If you don’t rely on RBAC with minimum access privileges and don’t enforce the correct policies to your cloud account and CI/CD platform/IaC orchestration platform, you can get into big trouble.
Ensuring proper governance is a proactive measure that helps prevent drift before it begins, aligning IaC with organizational standards and best practices.
How to prevent drift
To prevent drift, you need to address its root causes. Here are some of the best practices that help you do so:
1. Implement continuous drift detection
Using an automated drift detection tool to continuously monitor and alert you to any differences between the actual and desired state of your infrastructure is a life-saver. Having this information in a single view for all your infrastructure, getting alerts that notify you about drift, and being able to automatically remediate is critical for your organization’s reliability.
2. Define clear governance and compliance
Leveraging RBAC to limit who can make changes to the infrastructure, and requiring everything to be done through IaC is a good starting point. Having approval gates in your CI/CD or infrastructure orchestration platform to prevent unauthorized changes from being deployed is another good practice.
3. Leverage policy as code
Policy as code can validate IaC configurations to ensure they comply with your organizational policies. By automating a block on creating unauthorized resources, you significantly reduce the chances of drift.
4. Use security vulnerability scanners
One of the most common causes of drift is responding to a high-severity vulnerability by manually resolving it. By using a security vulnerability scanner in your infrastructure workflow before the deployment step, you will prevent vulnerabilities, meaning that you will face far fewer high-severity issues and, thus fewer issues being resolved manually.
5. Streamline your change management process
We’ve seen how frustration can lead to drift, so the change management process should be as uncomplicated as possible. In big organizations with multiple environments (at least dev, qa, staging, and prod environments), getting something into production can be a nightmare and, without the proper processes, may take months. Production deployments should happen weekly or biweekly and be as straightforward as possible to avoid engineers getting frustrated when they don’t see their changes.
Even in small organizations, engineers should have a sandbox environment where they can test small changes without affecting the production environment, reducing the temptation to bypass the process.
6. Regularly update IaC tools and provider versions
By regularly updating your IaC tools and provider versions, you avoid drift caused by outdated cloud service versions. Sometimes outdated versions simply no longer work due to API changes. As a best practice, you should always use version pinning and version control systems to ensure that updates are managed and applied consistently across your organization.
How Spacelift helps you avoid drift
Spacelift is an infrastructure orchestration platform that helps you provision, configure, and govern your infrastructure in a single workflow. By leveraging Spacelift, you can prevent, detect, and remediate drift.
Let’s take a look at what Spacelift can do to help you avoid drift:
1. Spaces for Role Based Access Control (RBAC)
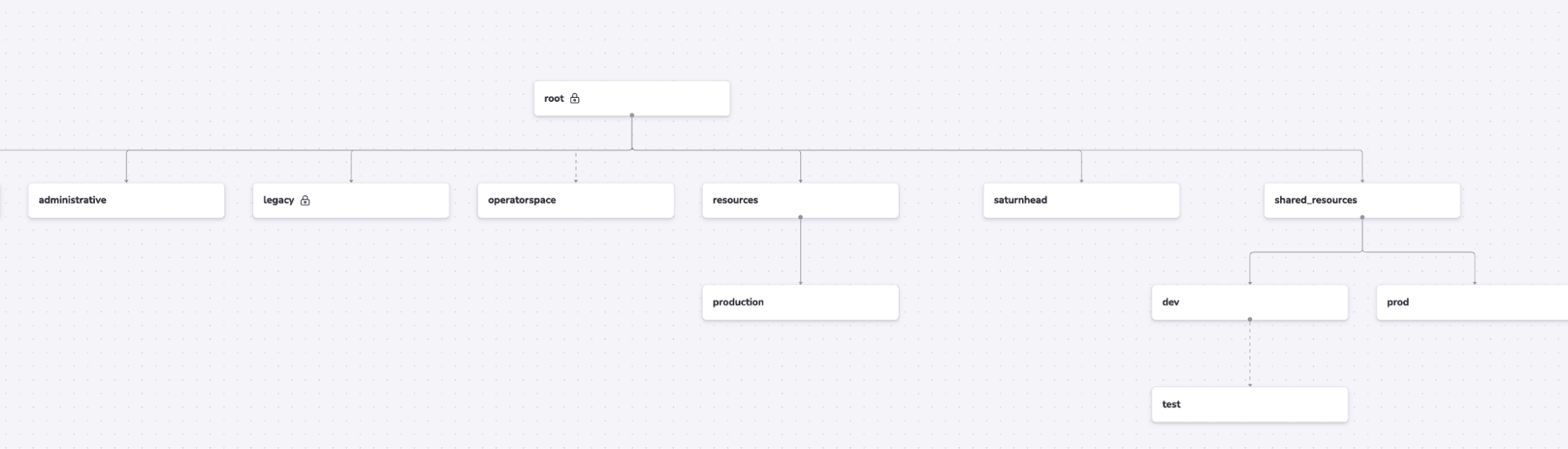
Spacelift lets you provide partial admin rights for your engineers. As many of Kubernetes’ resources are namespaced, Spacelift resources are spaced, meaning that they belong to a particular space.
Spaces allow you to limit users’ read/write/admin privileges to the spaces you specify. Using the Spaces image from above as an example, somebody with admin privileges on the shared_resources space will have admin access to the child spaces of this space, but they won’t be able to access anything else.
This helps you prevent drift because you have the option to let your engineers work in their own spaces, giving them a better separation, you can even build a test space in which they’ll be able to do any tests they want.
2. Policy as code
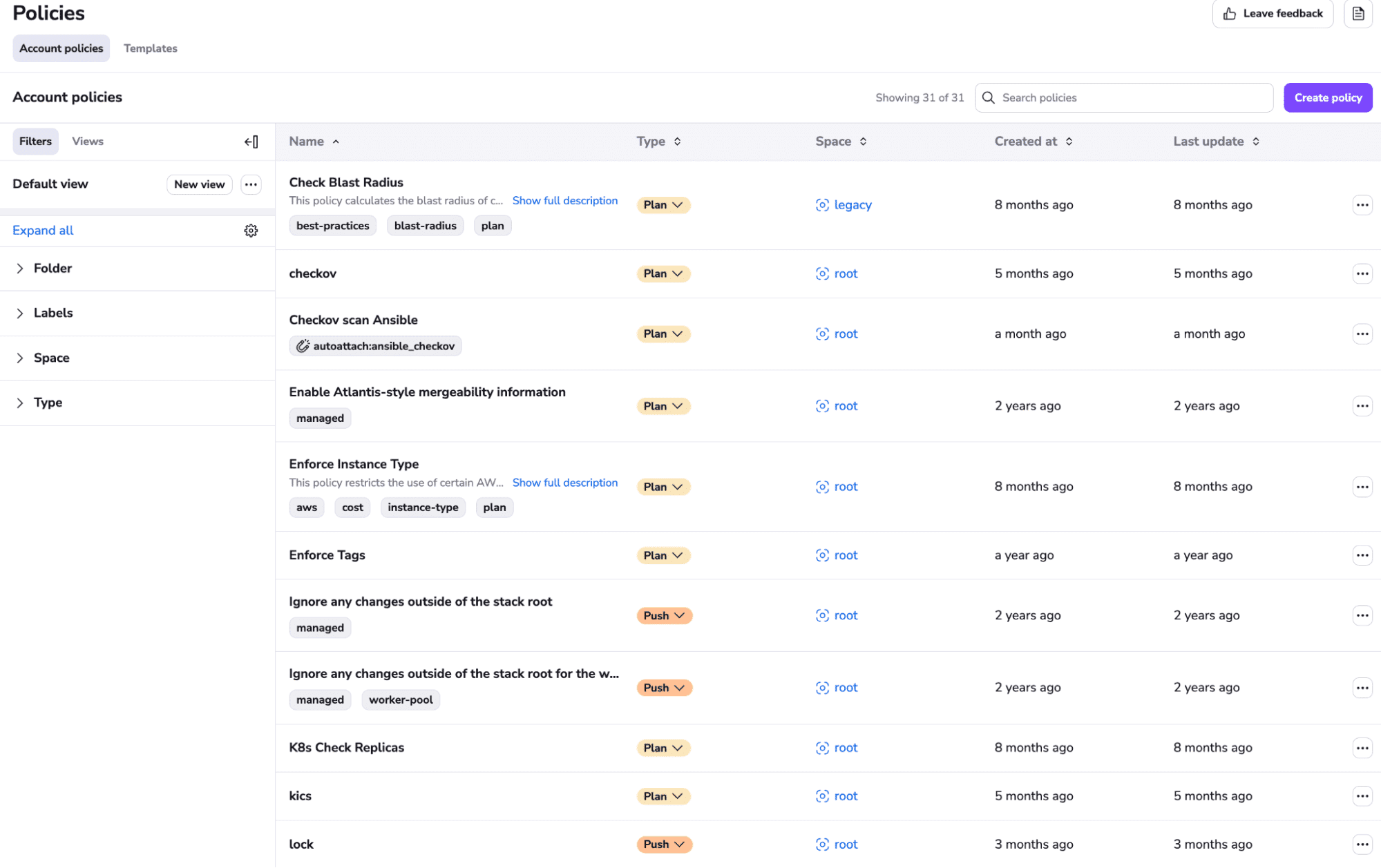
Spacelift offers several types of policies (based on the Open Policy Agent) that can help you ensure the overall governance required for your organization:
- Plan policies – restrict certain resources or certain parameters
- Approval policies – add a minimum number of run approvers, or what kind of tasks you can run (thus, this can help you implement approval gates)
- Push policies – determine what happens when a pull request is opened or merged
- Notification policies – determine where to send notifications
- Trigger policies – create dependencies between your stacks
By leveraging these policies, the potential for drift can be reduced significantly. The best part? You don’t even need to know how to write OPA policy because your account has an embedded policy library — the only thing you have to do is import the policies you want to use.
3. Custom inputs
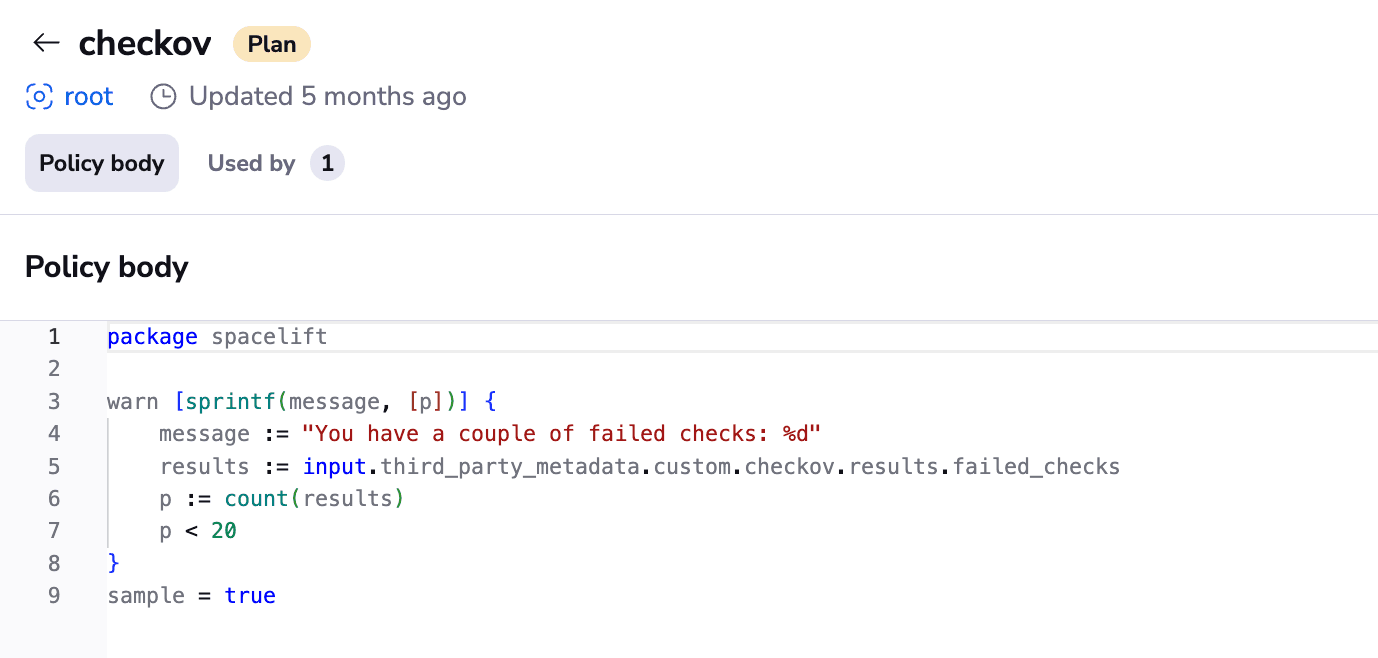
Spacelift can integrate with any tool you want, including security vulnerability scanning tools. To take it up a notch, you can even create custom plan policies for your security vulnerability scanning tools using custom inputs, and deny runs automatically if they don’t meet your criteria.
4. Blueprints for self-service infrastructure
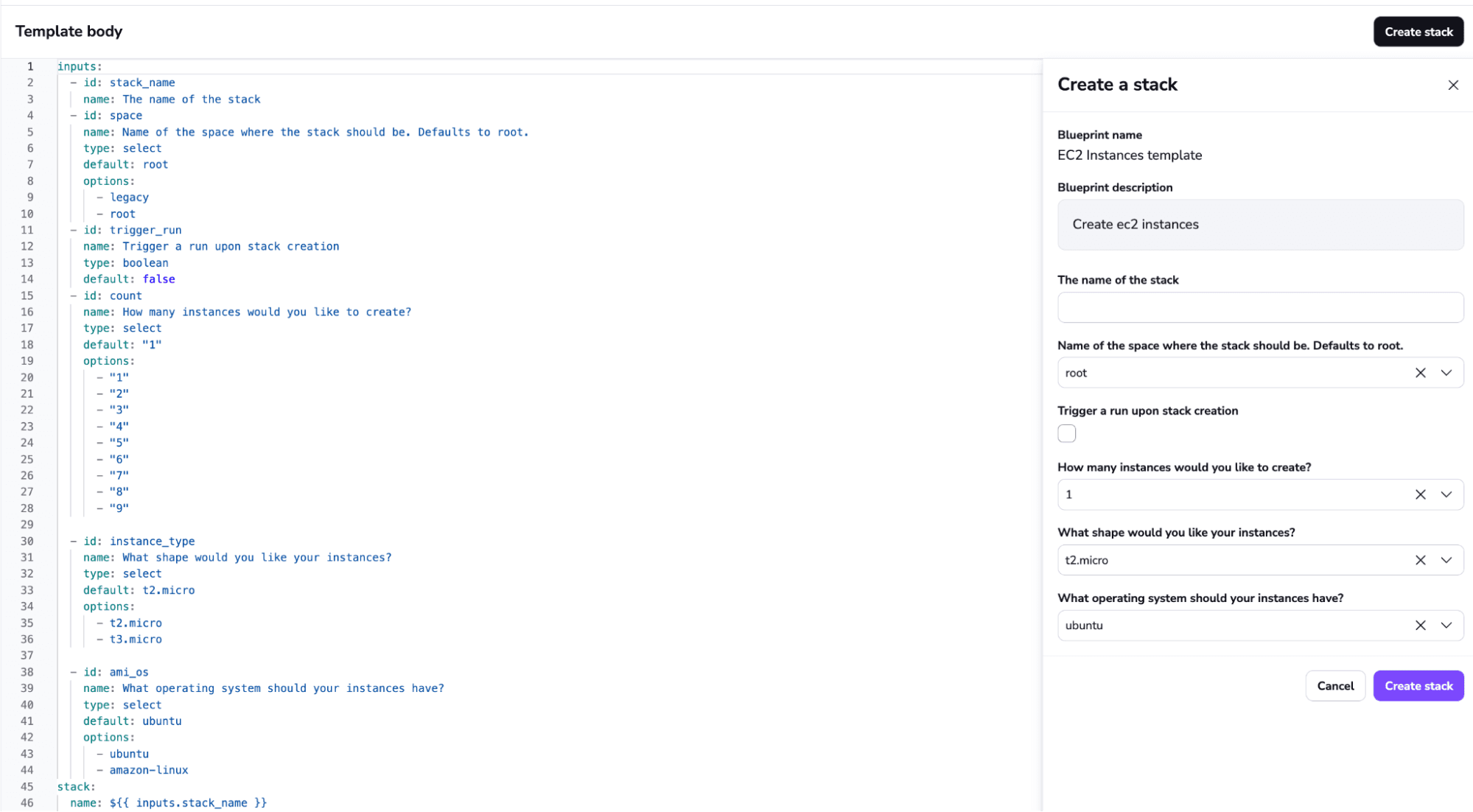
Leveraging self-service infrastructure is another feature that can help prevent drift. Blueprints allow you and your internal customers to create infrastructure by simply leveraging a form.
This also helps minimize process frustration — if the people who will use the template are involved in creating it, they probably won’t get frustrated or need to make changes to the infrastructure they deploy.
5. Contexts
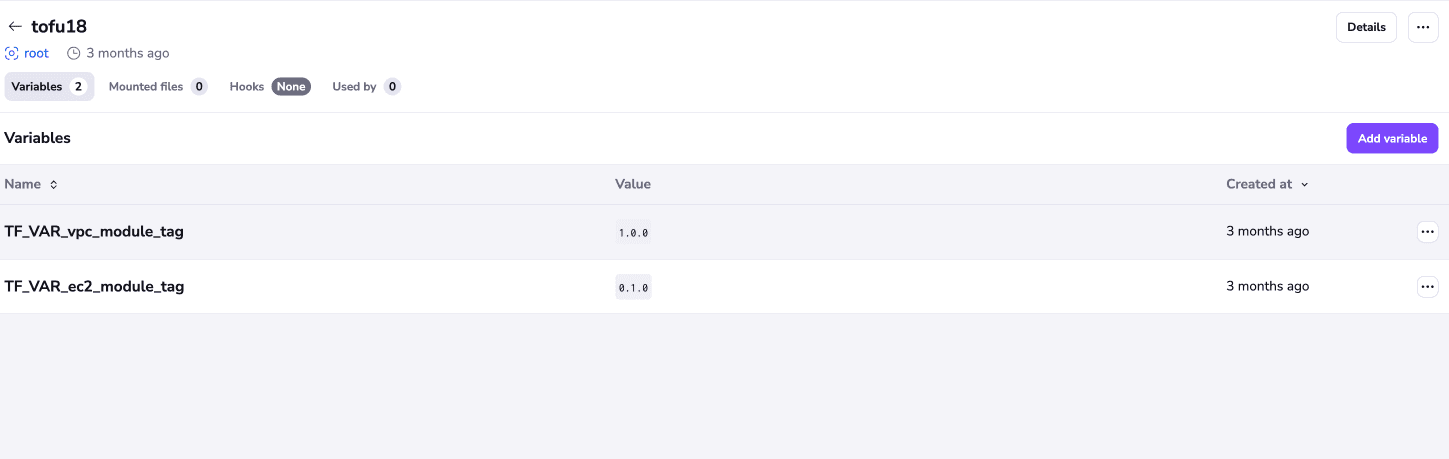
Contexts are reusable logical containers that hold your environment variables, mounted files, and lifecycle hooks and can be attached to any number of stacks. This helps you prevent drift by avoiding misconfiguration. If you get it right once and put it in the context, it will always be right.
6. Cloud integrations
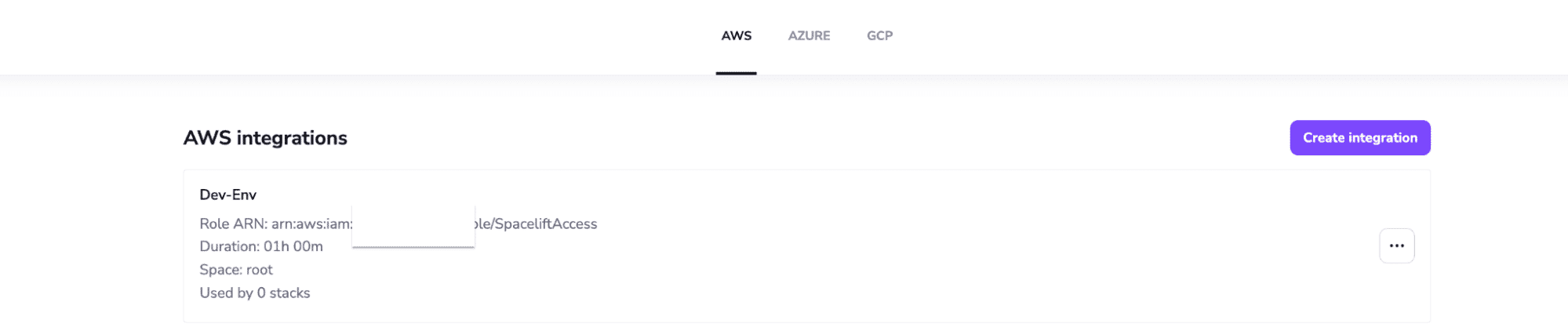
Cloud integrations generate dynamic and short-lived credentials for AWS, Azure, and GCP. By configuring these correctly, you can reuse them for any number of stacks, ensuring that no other accounts or roles are targeted by mistake.
Spacelift for drift detection and remediation
Although Spacelift offers many mechanisms for preventing drift, drift is inevitable in certain cases, which is why we offer a feature that detects drift and can optionally remediate it.
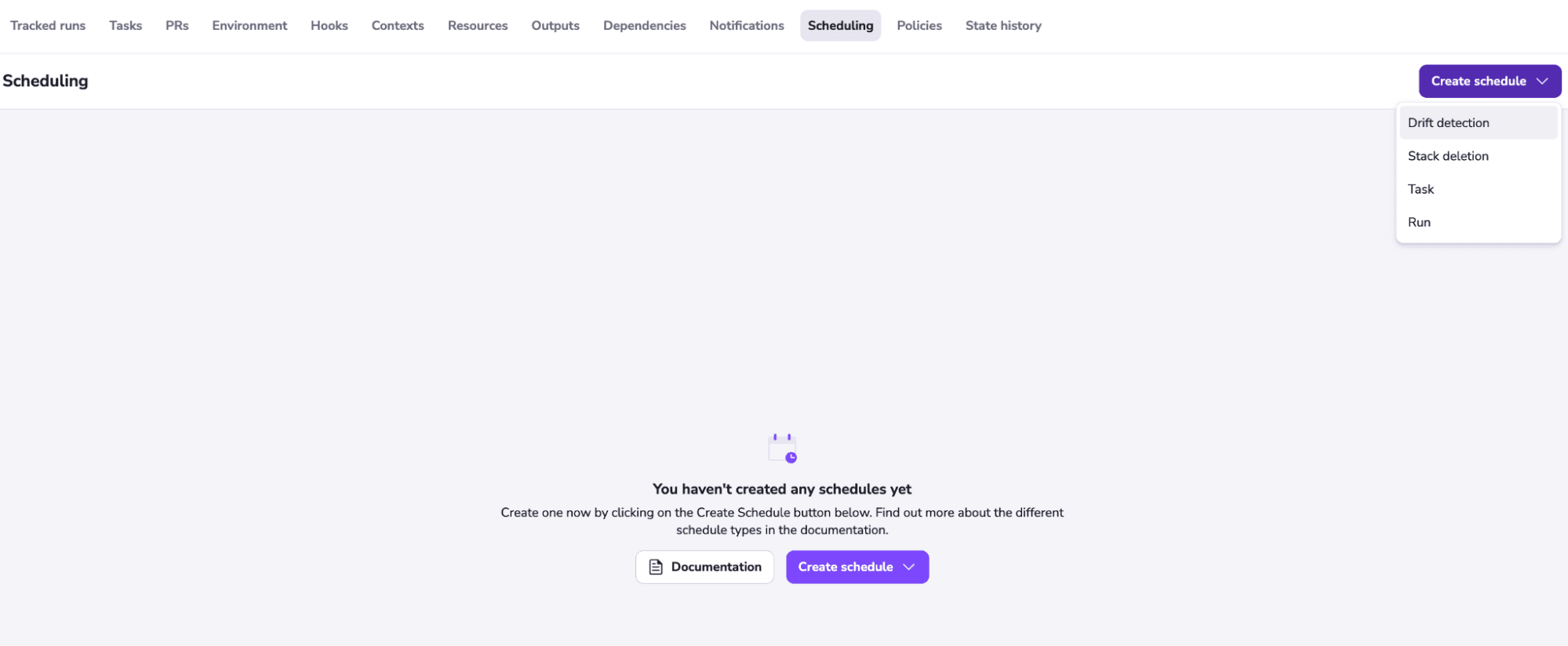
To use Spacelift’s drift detection, you must ensure that your stack is using private workers (this is available from the Starter+ tier). To set up drift detection, first go to your stack and select the Scheduling tab. Next, choose the Create schedule and select Drift detection.
You can set up the drift detection schedule as a cron expression and by default, it will run every 15 minutes. In addition, you also have the option to Reconcile, which means that as soon as drift has been detected, a job will run to remediate it.
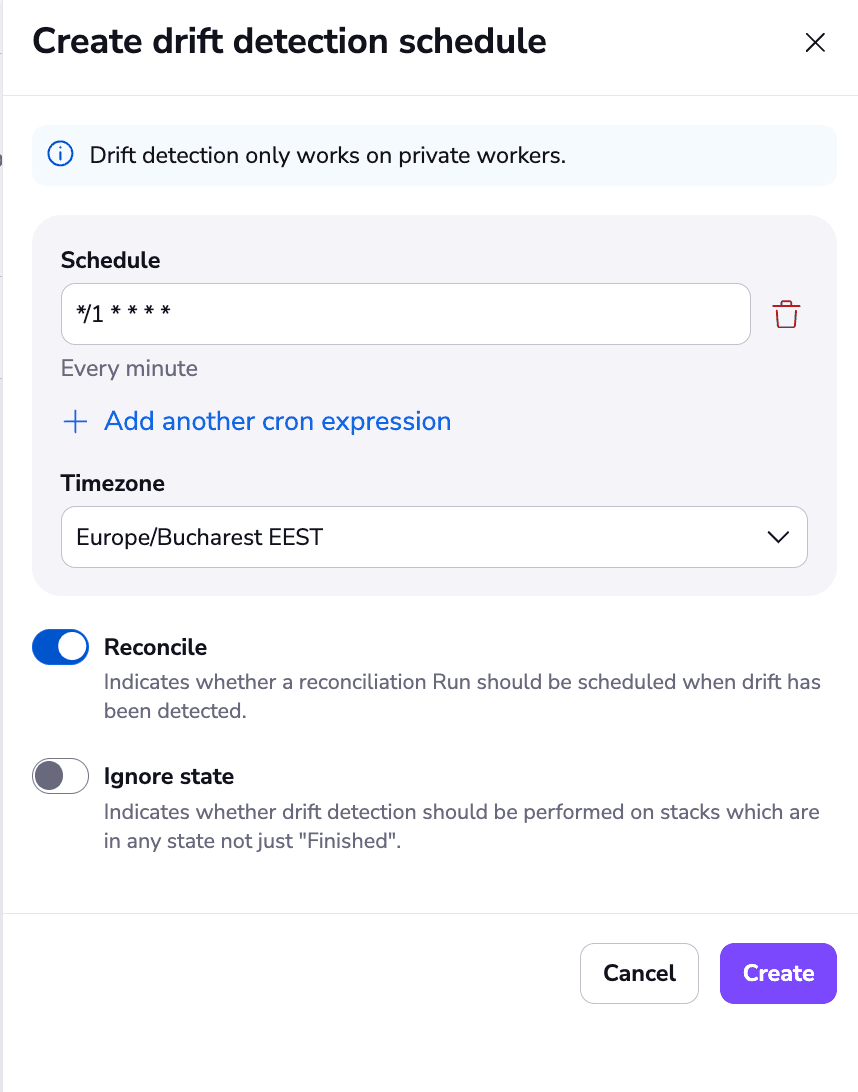
For this example, I am running the schedule every minute, and I also want to remediate the drift. This is what it will look like after I click on the Create button.
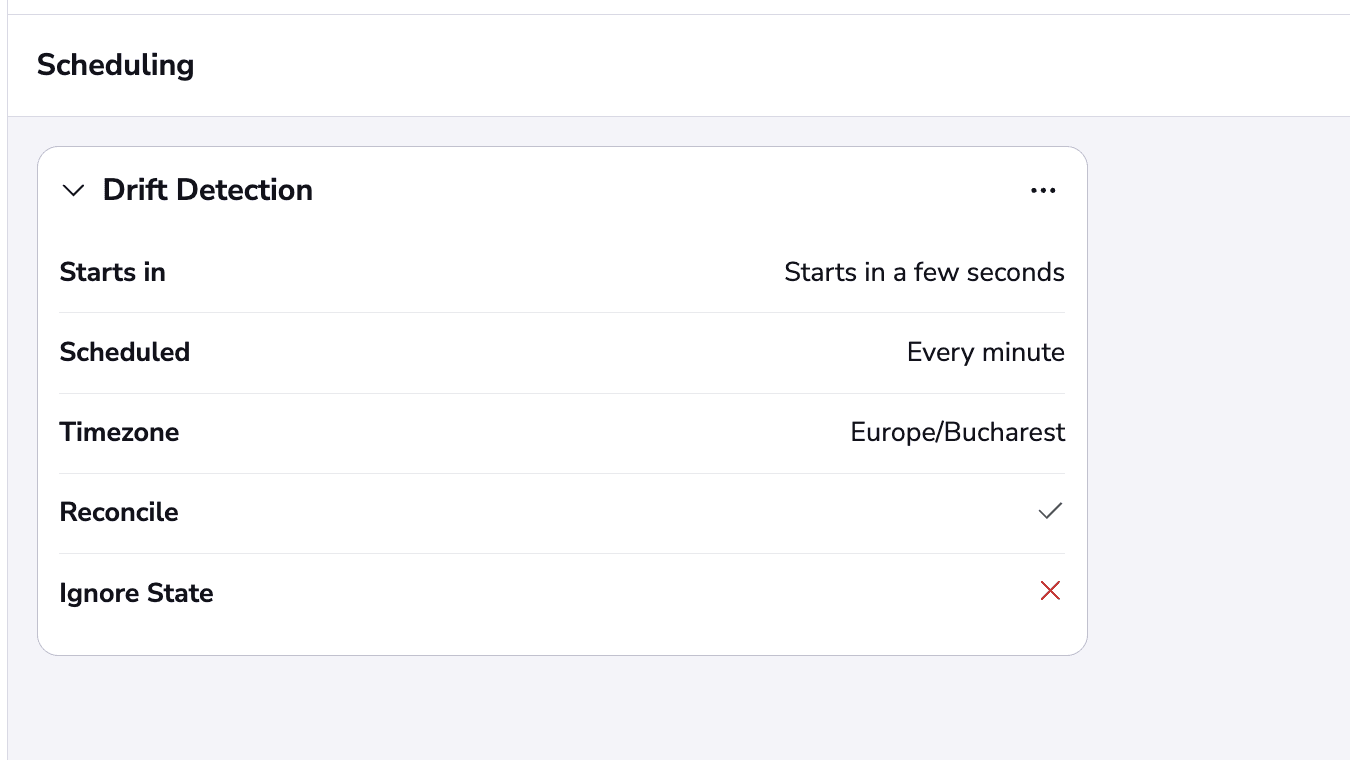
In this example, I will delete an instance manually, so as soon as the drift detection job finishes running, we should see the drift.
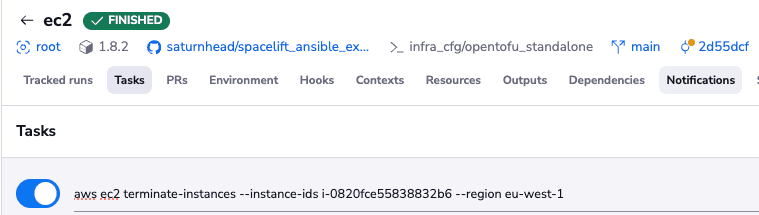
I am using a Spacelift task for this, so I will terminate the instance from the stack level manually. This creates the potential for mistakes, indicating a lack of proper governance that could have been avoided easily using an approval policy.
This is what the instances look like now:

As you wait, you can see the status changes for the drift detection job:
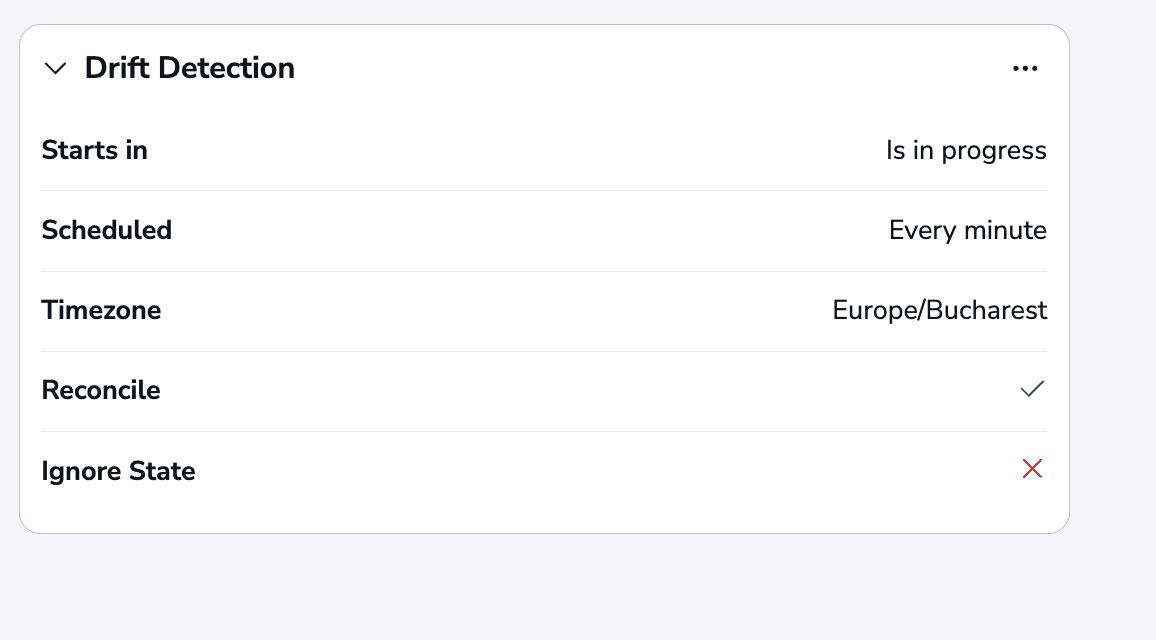
As soon as the drift has finished, we can navigate to our Resources view to see the resource has drifted:
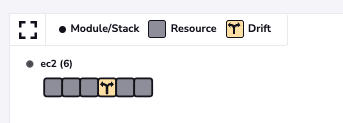
Because we have selected reconciliation, a job was triggered automatically to solve the drift:

The plan is finished, so we can see the instance will be recreated:

After the code is applied, if we return to the resource view, we will see that there are no more drifted resources:

Would you like to see it in action, or just want a tl;dr? Check out this video, where we demonstrate how drift can be automatically detected and remediated with Spacelift:

Key points
Infrastructure drift is inevitable no matter what you do to prevent it. However, it’s very important to implement all the mechanisms specified in this article to prevent it as much as possible. When prevention fails, you need to have a mechanism that detects the drift and gives you the option to remediate it.
Spacelift’s drift detection and remediation feature gives you this ability. You can easily define a drift detection schedule for your stacks and then make decisions based on the drift result.
If you want drift prevention, detection, and remediation, create a free account with Spacelift or book a demo with one of our engineers.
Detect and Remediate Drift with Spacelift
Drift happens, so let Spacelift deal with it. Spacelift provides drift detection capabilities to any IaC provider to enable the desired state for application infrastructure across teams, applications, and clouds.
