
In this post, I will explore some best practices for using Kubernetes (K8s) in production.
As the most popular container orchestration system, Kubernetes is the de facto standard for the modern cloud engineer to learn. However, K8s is notoriously complex to use and maintain, so knowing what you should and should not do and what is possible will help you get your deployment off to a solid start.
These recommendations cover common issues within three broad categories: application development, governance, and cluster configuration.
Kubernetes Best Practices:
- Use namespaces
- Use readiness and liveness probes
- Use autoscaling
- Use resource requests and limits
- Deploy your Pods as part of a Deployment, DaemonSet, ReplicaSet or StatefulSet across nodes
- Use multiple nodes
- Use Role-based access control (RBAC)
- Host your Kubernetes cluster externally (use a cloud service)
- Upgrade your Kubernetes version
- Monitor your cluster resources and audit policy logs
- Use a version control system
- Use a Git-based workflow (GitOps)
- Reduce the size of your containers
- Organize your objects with labels
- Use network policies
- Use a firewall
- Use declarative configuration
1. Use namespaces
For security purposes, you should utilize Kubernetes namespaces to organize your objects and create logical partitions within your cluster. By default, a K8s cluster has three namespaces: default, kube-public, and kube-system.
Role-based access control (RBAC) can be used to control access to particular namespaces and limit the blast radius of any mistakes that might occur. For example, a group of developers may have access to a namespace called dev and no access to the production namespace. The ability to limit different teams to different namespaces can be valuable to avoid duplicated work or resource conflict.
LimitRange objects can also be configured against namespaces to define the standard size for a container deployed in the namespace. ResourceQuotas can also be used to limit the total resource consumption of all containers inside a namespace. Network policies can be used against namespaces to limit traffic between pods.
Here’s a summary of the most important best practices for using Kubernetes namespaces:
- Organize by environment – Use namespaces to separate environments such as
dev,staging, andprodto ensure clear segmentation and prevent cross-environment interference. - Apply resource quotas – Assign resource quotas (e.g., CPU and memory limits) to namespaces to prevent one team or workload from consuming all cluster resources.
- Use RBAC – Configure RBAC to control access at the namespace level, granting users or groups only the permissions they need.
- Standardize naming conventions – Adopt consistent naming patterns for namespaces to simplify identification and management, such as
<team>-<environment>or<project>-<use-case>. - Monitor and label – Label namespaces with additional metadata (e.g., owner, purpose) and enable logging/monitoring to track activity and usage trends.
To learn more, check out our Working with Kubernetes Namespaces tutorial.
2. Use readiness and liveness probes
Readiness and liveness probes are essentially types of health checks and another very important concept to utilize in K8s.
Readiness probes ensure that requests to a pod are only directed to it when the pod is ready to serve requests. If it is not ready, requests are directed elsewhere. It is important to define the readiness probe for each container because no default values are set for these in K8s.
For example, if a pod takes 20 seconds to start and the readiness probe is missing, any traffic directed to that pod during the startup time would cause a failure. Readiness probes should be independent and not take into account any dependencies on other services, such as a backend database or caching service.
Liveness probes test whether the application is running so that it can be marked as healthy. For example, if a particular path of a web app is tested and found to be unresponsive, the pod will not be marked as healthy, and the probe failure will cause the Kubelet to launch a new pod, which will then be tested. This type of probe is used as a recovery mechanism for unresponsive processes.
3. Use autoscaling
Where appropriate, Kubernetes autoscaling can be employed to dynamically adjust the number of pods (Horizontal Pod Autoscaler), the number of resources consumed by the pods (Vertical Pod Autoscaler), or the number of nodes in the cluster (Cluster Autoscaler), depending on the demand for the resources.
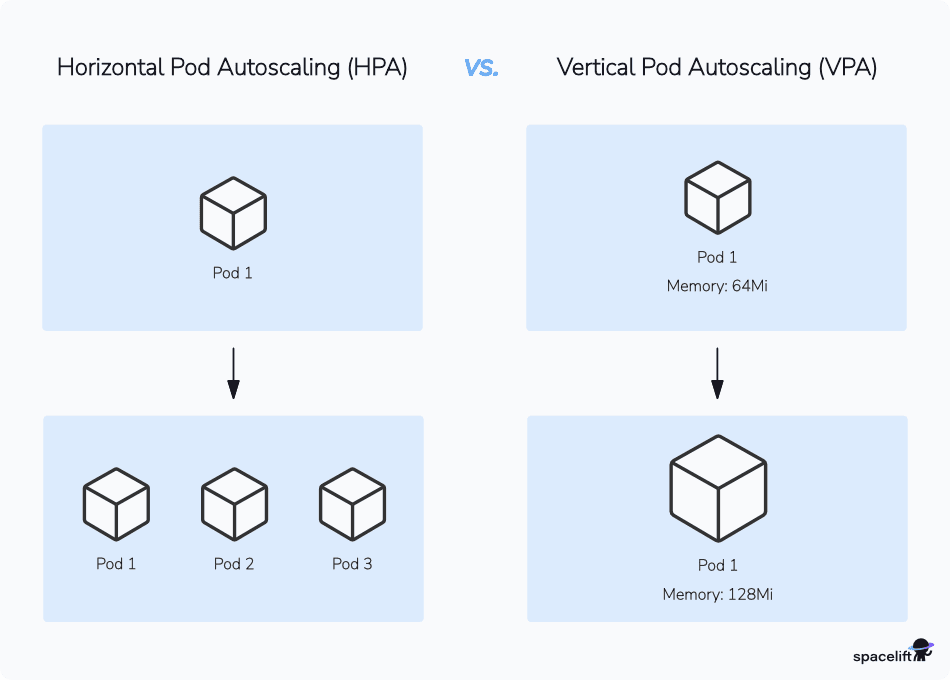
The HPA can also scale a replication controller, ReplicaSet, or StatefulSets based on CPU demand.
Scaling also brings challenges, such as not storing persistent data in the container’s local filesystem, as this would prevent horizontal autoscaling. Instead, a PersistentVolume could be used. (Read more about Kubernetes Persistent Volumes.)
The Cluster Autoscaler is useful when highly variable workloads on the cluster may require different amounts of resources at different times based on demand. Automatically removing unused nodes is also a great way to save money!
4. Use resource requests and limits
Resource requests and limits (the minimum and maximum amount of resources that can be used in a container) should be set to prevent a container from starting without the required resources assigned or the cluster from running out of available resources.
- Without limits, pods can utilize more resources than required, reducing the total resources available, which may cause a problem with other applications on the cluster. Nodes may crash, and the scheduler may be unable to place new pods correctly.
- Without requests, if the application cannot be assigned enough resources, it may fail when attempting to start or may perform erratically.
Resource requests and limits define the amount of CPU and memory available in millicores and mebibytes.
Note: If your process exceeds the memory limit, the process is terminated, so it may not always be appropriate in all cases to set this. If your container exceeds the CPU limit, the process is throttled.
5. Deploy your pods as part of a Deployment, DaemonSet, ReplicaSet, or StatefulSet across nodes
A single pod should never be run individually. To improve fault tolerance, they should always be part of a Deployment, DaemonSet, ReplicaSet, or StatefulSet. The pods can then be deployed across nodes using anti-affinity rules in your deployments to avoid all pods being run on a single node, which may cause downtime if it were to go down.
6. Use multiple nodes
Running Kubernetes on a single node is not a good idea if you want to build fault tolerance. Your cluster should have multiple nodes so workloads can be spread between them.
7. Use role-based access control (RBAC)
Using RBAC in your K8s cluster is essential to properly secure your system. Users, Groups, and Service accounts can be assigned permissions to perform permitted actions on a particular namespace (a Role) or to the entire cluster (ClusterRole). Each role can have multiple permissions. To tie the defined roles to the users, groups, or service accounts, RoleBinding or ClusterRoleBinding objects are used.
RBAC roles should be set up to grant permissions using the principle of least privilege, i.e., only the required permissions are granted. For example, the admin’s group may have access to all resources, and your operator’s group may be able to deploy but not be able to read Secrets.
8. Host your Kubernetes cluster externally (use a cloud service)
Hosting a Kubernetes cluster on your own hardware can be a complex undertaking. Cloud services offer K8s clusters as platform as a service (PaaS), such as AKS (Azure Kubernetes Service) on Azure, or EKS (Amazon Elastic Kubernetes Service) on Amazon Web Services.
Using PaaS means your cloud provider manages the underlying infrastructure, making it easier to accomplish tasks such as adding and removing nodes when scaling your cluster and leaving your engineers to manage what is running on the K8s cluster itself.
9. Upgrade your Kubernetes version
New Kubernetes versions introduce new features and include vulnerability and security fixes, making it important to run an up-to-date version on your cluster. Support is likely to be better for newer versions than for newer ones.
However, migrating to a new version should be treated with caution because certain features can be deprecated and new ones can be added. Before upgrading, you should also check the apps running on your cluster to ensure they are compatible with the newer targeted version.
10. Monitor your cluster resources and audit policy logs
Monitoring the components in the Kubernetes control plane is important for controlling resource consumption. The control plane at the core of Kubernetes contains Kubernetes API, kubelet, etcd, controller-manager, kube-proxy and kube-dns, which are vital for keeping the system running.
Control plane components can output metrics in a format Prometheus —the most common K8s monitoring tool — can use.
Rather than manually managing alerts, you should use automated monitoring tools.
Audit logging in K8s can be turned on while starting the kube-apiserver to enable deeper investigation using the tools of your choice. The audit.log will detail all requests made to the K8s API and should be inspected regularly for any issues that might cause problems on the cluster. The Kubernetes cluster default policies are defined in the audit-policy.yaml file and can be amended as required.
A log aggregation tool, such as Azure Monitor, can send logs to a log analytics workspace from AKS for future interrogation using Kusto queries. On AWS, you can use CloudWatch. Third-party tools, such as Dynatrace and Datadog, also provide deeper monitoring functionality.
Finally, the logs should have a defined retention period, which is typically 30–45 days.
Tracking key metrics regularly and reviewing audit policy logs can help uncover inefficiencies, prevent resource over-allocation, and detect suspicious activity. Here are some of the cluster metrics you should be tracking:
| Category | Metric | Why it’s important |
| Node performance | CPU Usage | Detects over- or under-utilization of node resources. |
| Memory Usage | Identifies potential memory bottlenecks. | |
| Pod health | Pod Restart Count | Indicates potential instability or misconfigurations in pods. |
| Pod Scheduling Latency | Tracks delays in pod placement due to resource constraints. | |
| Cluster health | API Server Latency | Helps ensure the control plane is responsive and stable. |
| ETCD Disk I/O | Monitors the health and speed of the cluster’s data store. | |
| Security | Unauthorized Access Attempts | Identifies potential security breaches or threats. |
| Configuration Drift | Detects unauthorized or unintended changes in cluster configs. | |
| Network | Network Traffic Volume | Ensures network traffic is within expected limits. |
| Network Latency | Tracks delays in communication between services. |
11. Use a version control system
Kubernetes configuration files should be controlled in a VCS. This enables a raft of benefits, including increased security and the potential to establish an audit trail of changes. It will also increase the cluster’s stability. Approval gates for any changes made will allow the team to peer-review the changes before they are committed to the main branch.
12. Use a git-based workflow (GitOps)
Successful deployments of Kubernetes require satisfactory workflow processes.
Using a Git-based workflow enables automation through the use of continuous integration/continuous delivery (CI/CD) pipelines, which increases application deployment efficiency and speed. CI/CD also provides an audit trail of deployments.
Git should be the single source of truth for all automation and will enable unified management of the K8s cluster. You can also consider using a dedicated infrastructure delivery platform such as Spacelift, which recently introduced Kubernetes support.
Learn how to maintain operations around the Kubernetes Cluster.
13. Reduce the size of your containers
Smaller image sizes will help speed up your builds and deployments and reduce the amount of resources the containers consume on your K8s cluster. Unnecessary packages should be removed where possible, and small OS distribution images such as Alpine should be favored. Smaller images can be pulled faster than larger images and consume less storage space.
Following this approach also provides security benefits by reducing the number of potential attack vectors for malicious actors.
14. Organize your objects with labels
Kubernetes labels are key-value pairs attached to objects to organize cluster resources. They should provide meaningful metadata that provides a mechanism to track how different components in the K8s system interact.
Recommended labels for pods in the official K8s documentation include name, instance, version, component, part-of, and managed-by.
Labels can also be used similarly to tags to track business-related elements in cloud-environment resources, such as object ownership and the environment an object should belong to.
It is also recommended to use labels to detail security requirements, including confidentiality and compliance.
15. Use network policies
Network policies should be employed to restrict traffic between objects in the K8s cluster.
By default, all containers can talk to each other in the network, which presents a security risk if malicious actors gain access to a container and can traverse objects in the cluster.
Network policies can control traffic at the IP and port level, similar to the concept of security groups in cloud platforms to restrict access to resources. Typically, all traffic should be denied by default, with rules in place to allow required traffic.
16. Use a firewall
In addition to using network policies to restrict internal traffic on your K8s cluster, you should also put a firewall in front of it to restrict requests to the API server from the outside world. IP addresses should be whitelisted, and open ports should be restricted.
17. Use declarative configuration
Declarative configuration involves specifying the desired state of your resources in YAML or JSON files and then using tools like kubectl apply to apply these configurations to your cluster.
You describe what your resources should look like rather than issuing imperative commands to achieve a specific state. Declarative configuration is idempotent, meaning that applying the same configuration multiple times results in the same desired state.
Managing Kubernetes with Spacelift
If you need any assistance with managing your Kubernetes projects, consider Spacelift. It brings with it a GitOps flow, so your Kubernetes Deployments are synced with your Kubernetes Stacks, and pull requests show you a preview of what they’re planning to change.
With Spacelift, you get:
- Policies to control what kind of resources engineers can create, what parameters they can have, how many approvals you need for a run, what kind of task you execute, what happens when a pull request is open, and where to send your notifications
- Stack dependencies to build multi-infrastructure automation workflows with dependencies, having the ability to build a workflow that can combine Terraform with Kubernetes, Ansible, and other infrastructure-as-code (IaC) tools such as OpenTofu, Pulumi, and CloudFormation,
- Self-service infrastructure via Blueprints enabling your developers to do what matters – developing application code while not sacrificing control
- Creature comforts such as contexts (reusable containers for your environment variables, files, and hooks), and the ability to run arbitrary code
- Drift detection and optional remediation
If you want to learn more about Spacelift, create a free account today or book a demo with one of our engineers.

When you shift to treating infrastructure like a software project, you need all of the same components that a software project would have. That means having a CI/CD platform in place, and most aren’t suited to the demands of IaC. Insurtech company Kin discovered that Spacelift was purpose-built to fill that gap.
Key points
Following the best practices listed in this article when designing, running, and maintaining your Kubernetes cluster will help make your applications successful. You should also check out 15 challenges and pitfalls to look for each time you use Kubernetes.
Manage Kubernetes Easier and Faster
Spacelift allows you to automate, audit, secure, and continuously deliver your infrastructure. It helps overcome common state management issues and adds several must-have features for infrastructure management.
