
Kubernetes is a container orchestration system designed to simplify the process of deploying and managing containerized apps. It makes it easy to deploy multiple replicas of your containers across a cluster of compute Nodes, ensuring stable performance and fault tolerance.
One of Kubernetes’ greatest strengths is its support for scalability and high availability. You can automate scaling configuration at the workload or cluster level, allowing you to resize your deployments or even expand cluster capacity in response to dynamic events.
This article will show you how to control Kubernetes scaling options so you can operate your container workloads more robustly.
What is Kubernetes scaling?
Scalability, in general, refers to a system’s ability to scale when external conditions change. A scalable system is better able to meet performance requirements consistently because its capacity can be resized based on factors such as resource utilization, error rates, and active user counts.
Kubernetes scaling refers to the process of dynamically adjusting the number of pod replicas (instances of your application) in a Kubernetes cluster to meet varying demands. Depending on the use case, this can be done either manually or automatically. Scaling ensures your application can handle increased load or save resources during low-demand periods.
Systems that are easy to expand with additional resources are more scalable than those that operate in a fixed environment.
Kubernetes has good scalability because it uses a distributed architecture, where workloads are divided among multiple Nodes that you can freely add and remove; furthermore, individual workload deployments can be scaled with multiple replicas to increase service capacity and maximize failure resilience.
Types of Kubernetes scalability
Kubernetes can be scaled at either the workload or cluster level:
- Workload scaling deploys additional Pod replicas or assigns more resources to existing replicas.
- Cluster scaling expands overall cluster capacity by adding or resizing Nodes, allowing you to scale your workloads limitlessly.
More generally, Kubernetes scalability has two main forms:
- Horizontal scaling expands capacity by adding extra instances to your system, such as starting new Kubernetes Nodes or deployment replicas.
- Vertical scaling refers to resizing existing resources, such as by adding extra CPU or memory resources to existing Nodes, or allowing individual replicas to utilize more of the available resources.
The following table summarizes the types of scalability you can use in Kubernetes:
| Horizontal scaling | Vertical scaling | |
| Cluster scaling | Adding additional Nodes | Adding additional resources (CPU/memory, etc.) to existing Nodes |
| Workload scaling | Deploying additional Pod replicas | Allowing Pods to consume additional CPU/memory resources |
Guide: Setting up Kubernetes auto-scaling with different scaling options
It’s possible to scale Kubernetes Nodes and Pods manually, but this isn’t responsive enough for real-world production applications. Learning how to use the available Kubernetes auto-scaling mechanisms will ensure your clusters can continually scale dynamically without requiring an operations team to stay on standby.
1. Using Kubernetes Horizontal Pod Autoscaler (HPA) for horizontal scaling
Horizontal Pod Autoscaler (HPA) automatically modifies the replica count of Kubernetes Deployments and other workload objects in response to metrics changes. This allows you to provision additional Pod replicas as utilization evolves. It’s ideal for applications in heavy use, but each request requires relatively few resources to serve.
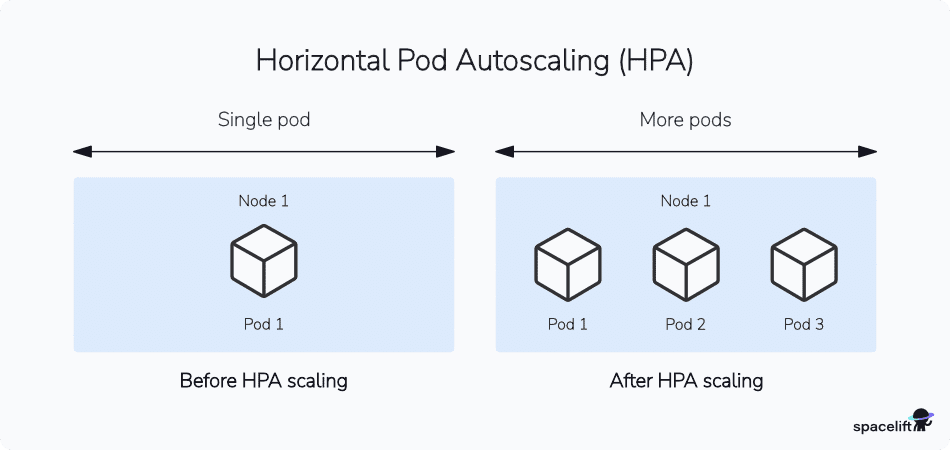
HPA can be connected to any kind of metrics source you require, including values generated by your app. It works with the Kubernetes Custom Metrics API, which can be connected through adapters to systems such as Prometheus. For instance, you could dynamically scale your app based on the number of incoming orders, user registrations, or any other application-specific metrics that are critical to your operation.
By default, HPA uses the Kubernetes Metrics-Server to support scaling based on changes in CPU and memory consumption. You specify the target CPU utilization or memory consumption for your deployment, then set the minimum and maximum number of Pods that can run. HPA will automatically adjust the actual replica count within these parameters.
Horizontal Pod Autoscaler limitations
HPA works predictably and has few limitations. However, it’s worth noting that you should avoid basing your HPA configuration on CPU and memory utilization if you’re also using VPA. Otherwise, the changing CPU and memory requests applied by VPA will destabilize HPA.
Kubernetes HPA example
The following Horizontal Pod Autoscaler manifest auto-scales the demo-app Deployment so that CPU utilization across the running Pods averages 60%. The minReplicas and maxReplicas parameters guarantee that regardless of CPU utilization, between five and 15 Pods will be running at any time.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: demo-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-app
minReplicas: 5
maxReplicas: 15
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 602. Using Kubernetes Vertical Pod Autoscaler (VPA) for vertical scaling
Vertical autoscaling is less common in Kubernetes but is possible if you install the optional vertical-pod-autoscaler component in your cluster. Once enabled, you can use the provided CRDs to set up vertical autoscaling configurations that dynamically change your workload’s CPU and memory resource requests.

Use of VPA isn’t advisable if your app’s resource utilization is predictable and scales linearly with increased usage. HPA will be more flexible and resilient in this scenario. Where VPA excels is resizing stateful workloads that may be tricky to configure for horizontal scalability.
VPA lets you ensure stable performance for databases, file servers, and caches by allowing them to access additional resources when required, without changing the number of Pods that run.
Vertical Pod Autoscaler limitations
Vertical autoscaling has an important limitation: When VPA wants to change a Pod’s resource request, it must terminate and recreate it. This could cause disruption, so you should utilize Pod Disruption Budgets to control the number of Pods that may become unavailable.
Kubernetes v1.27 introduced alpha support for in-place Pod resource constraint changes without a recreate, but it must be enabled manually via a cluster feature gate.
Kubernetes VPA example
The following VerticalPodAutoscaler example adjusts the demo-app Deployment’s resource requests between 1 and 2 CPU cores and 100Mi and 1Gi of memory, based on observed utilization:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: demo-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-app
resourcePolicy:
containerPolicies:
- containerName: demo
minAllowed:
cpu: 1
memory: 100Mi
maxAllowed:
cpu: 2
memory: 1Gi
controlledResources: ["cpu", "memory"]3. Using Kubernetes Cluster Autoscaler
Kubernetes cluster autoscaling allows you to dynamically scale the Nodes that host your cluster’s workloads. It supports both horizontal autoscaling — changing the number of Nodes — and vertical autoscaling, where existing Nodes are resized.
Cluster autoscaling is only possible when you’re operating your cluster in the cloud. Support is provided by the Cluster Autoscaler component. This should be preinstalled in your cluster if you’re using a compatible service. All major managed Kubernetes platforms provide an autoscaling integration.
Cluster autoscaling responds to two main events:
- When Pods are unschedulable due to unfulfillable Node resource requirements, cluster autoscaling will add new Nodes or resize existing ones.
- When your cluster has Nodes with no workloads, or Pod eviction onto other Nodes is possible, then excess Nodes will be automatically removed.

Using the Cluster Autoscaler solves the problem of HPA and VPA scaling ordinarily being capped by your cluster’s total capacity. With cluster autoscaling enabled, Nodes will be added or resized as cluster capacity is reached, enabling workloads to continue scaling up.
Cluster autoscaling can also improve the cost-effectiveness of your clusters. The autoscaler will remove or downsize Nodes after utilization subsides, reducing waste and helping to trim your cloud bill.
The Cluster Autoscaler component is designed to run directly on the Kubernetes control plane and shouldn’t normally be deployed manually to worker Nodes. To enable autoscaling, it’s best to use the options available in your cloud provider’s control panel, API, or CLI, referring to the service’s documentation for detailed guidance. You can manage your autoscaling configuration declaratively by using an IaC tool such as Terraform or Ansible to provision your cluster.
Kubernetes cluster autoscaling used in combination with HPA or VPA provides the strongest scalability and high availability for production workloads. However, you must ensure all your Pods are assigned correct resource requests so the autoscaler can accurately assess Node utilization and make appropriate rescaling decisions.
Cluster Autoscaler limitations
Kubernetes Cluster Autoscaler dynamically adjusts the number of nodes in a cluster based on resource needs, but it has limitations, such as reliance on accurate resource requests/limits and inability to scale down underutilized nodes with non-evictable pods (e.g., DaemonSets or pods with local storage). Additionally, it does not consider custom metrics for scaling and can face delays due to cloud provider API rate limits or cluster-specific configurations.
Read more: Karpenter vs. Cluster Autoscaler Comparison
Can Kubernetes scale down to zero?
Kubernetes can scale to zero, but this has caveats and is often ill-advised. While the default Horizontal Pod Autoscaler (HPA) usually maintains at least one pod, tools like KEDA or Knative enable scaling to zero for event-driven or serverless workloads. You can also manually scale deployments to zero using kubectl.
Scaling down to zero introduces a delay (cold start) when scaling back up, which can impact latency-sensitive applications.
At the workload level, it is possible to manually scale a Deployment object down to zero, leaving no running Pods. This can be achieved either by running the kubectl scale command, or by making an API call.
It doesn’t work when HPA is used: HPA requires at least one Pod to be running at all times, as otherwise, it can’t collect the metrics used to inform future scale-up decisions.
Your ability to scale cluster nodes down to zero depends on the Kubernetes distribution you’re using. Most self-contained distributions, such as Minikube and K3s, require clusters to maintain at least one Node, which runs the control plane and stores the cluster state. Cloud-managed services generally allow you to remove all your Node pools, leaving just the control plane running, but this may vary by provider.
Best practices for scaling Kubernetes
The following best practices will help ensure your Kubernetes clusters scale predictably and reliably:
- Use Horizontal/Vertical Pod Autoscaler to scale your workloads: Setting up HPA and VPA allows for hands-off auto-scaling, making your clusters more resilient to unforeseen workload utilization changes.
- Enable cluster auto-scaling: Utilizing cluster auto-scaling allows you to scale your clusters almost infinitely, ensuring your service remains available even during times of exceptional user demand.
- Ensure spare cluster capacity is available if not using auto-scaling: When you’re not using cluster auto-scaling, it’s important to ensure your cluster has sufficient spare Node capacity to accommodate scaling changes made to your deployments — otherwise, Pods will start to fail scheduling.
- Set appropriate resource requests and limits on all workloads: Correct auto-scaling behavior depends on your Pods being assigned suitable resource requests and limits. Missing requests prevent the autoscaler from accurately analyzing Node capacity.
- Keep resource requests and limits closely matched: Keeping resource requests and limits matched makes scaling behavior more predictable. In general, a Pod’s memory limit should always be set equal to its request, ensuring the Pod is reliably terminated when memory pressures occur, while the CPU limit may match the request or be left unset.
- Assign each workload to the most appropriate Node type: Many cluster admins provision multiple types of Nodes using different hardware tiers, such as standard Nodes for regular apps and high-powered GPU-equipped Nodes for more demanding workloads. Use affinity rules and label selectors to precisely allocate Pods to Nodes, ensuring efficient resource usage. This will prevent autoscaling from scheduling low-priority Pods onto high-end hardware.
- Utilize Pod Disruption Budgets so users aren’t affected by scaling changes: Pod Disruption Budgets limit the number of Pod replicas that can be simultaneously unavailable during a disruption event, such as scaling down or deploying a new version of your app. Configuring PDBs further improves your workload’s resilience by ensuring a minimum availability standard is continually maintained.
- Ensure the correct rollout strategy is used for each Deployment: Your Deployment’s rollout strategy affects scalability and high availability. For example, using the Recreate strategy, where Pods are terminated before they’re replaced, can increase the likelihood of disruption, whereas external tools like Argo Rollouts improve safety at scale by allowing you to use advanced canary and blue-green deployment methods.
Overall, it’s best to use HPA, VPA, and cluster auto-scaling to scale your clusters, instead of relying on manual scaling commands. However, auto-scaling doesn’t make human management completely unnecessary. You should still regularly monitor your clusters and review performance, then adjust your auto-scaling constraints where necessary.
Managing Kubernetes with Spacelift
If you need any assistance with managing your Kubernetes projects, consider Spacelift. It brings with it a GitOps flow, so your Kubernetes Deployments are synced with your Kubernetes Stacks, and pull requests show you a preview of what they’re planning to change.
With Spacelift, you get:
- Policies to control what kind of resources engineers can create, what parameters they can have, how many approvals you need for a run, what kind of task you execute, what happens when a pull request is open, and where to send your notifications
- Stack dependencies to build multi-infrastructure automation workflows with dependencies, having the ability to build a workflow that can combine Terraform with Kubernetes, Ansible, and other infrastructure-as-code (IaC) tools such as OpenTofu, Pulumi, and CloudFormation,
- Self-service infrastructure via Blueprints enabling your developers to do what matters – developing application code while not sacrificing control
- Creature comforts such as contexts (reusable containers for your environment variables, files, and hooks), and the ability to run arbitrary code
- Drift detection and optional remediation
If you want to learn more about Spacelift, create a free account today or book a demo with one of our engineers.
Key points
We’ve explored Kubernetes scaling options and how they contribute to robust cluster operations. Utilizing Kubernetes allows you to benefit from automatic scaling, high availability, and fault tolerance, but you still have to configure these facilities and ensure your workloads are optimized to take advantage of them.
You can further improve your infrastructure’s scalability by using IaC tools to declaratively configure your resources. This enables you to provision new environments or add extra capacity by adjusting your IaC config file, and then running automated tooling to apply the change to your infrastructure.
Manage Kubernetes Easier and Faster
Spacelift allows you to automate, audit, secure, and continuously deliver your infrastructure. It helps overcome common state management issues and adds several must-have features for infrastructure management.
Frequently asked questions
Is Kubernetes vertical or horizontal scaling?
Kubernetes supports both vertical and horizontal scaling, but horizontal scaling is the primary and most efficient method used in production environments.
What are the two types of autoscaling?
The two types of autoscaling are horizontal scaling and vertical scaling. Horizontal scaling (scale out/in) adds or removes instances, such as VMs or containers, to handle load changes. Vertical scaling (scale up/down) adjusts resources (CPU, RAM) on a single instance. Most cloud-native environments prioritize horizontal scaling due to better fault tolerance and flexibility.
How does Kubernetes know when to scale?
Kubernetes knows when to scale based on configured metrics and policies. The Horizontal Pod Autoscaler (HPA) uses metrics like CPU or memory usage, custom metrics, or external metrics. It evaluates metrics on a periodic sync loop, which defaults to about 15 seconds, and adjusts pod counts to meet target thresholds.
