
Kubernetes has become one of the standard container orchestration systems. As applications running on Kubernetes clusters face varying workload demands, the ability to automatically scale resources becomes a critical requirement for modern cloud-native architectures.
Kubernetes offers several approaches to handling these scaling needs, with two solutions emerging for cluster-level scaling: the traditional Kubernetes Cluster Autoscaler and the newer, more sophisticated Karpenter. Although both tools serve the fundamental purpose of automatically adjusting cluster capacity, they differ significantly in their approach and implementation.
This article compares these autoscaling solutions, exploring their architectures, differences, and use cases.
What we will cover:
Kubernetes autoscaling basics
In Kubernetes, containers and pods spin up and down constantly, so efficient resource management is crucial for performance and cost optimization. Before we discuss the specifics of each solution, let’s review the basics of Kubernetes autoscaling.
Scaling Kubernetes workloads
Kubernetes provides two layers of autoscaling to handle different aspects of resource management. The first layer includes autoscaling at the application level, either by automatically adjusting the number of pod replicas in a deployment or replication controller or by adjusting the size of the pods.
Horizontal Pod Autoscaler (HPA)
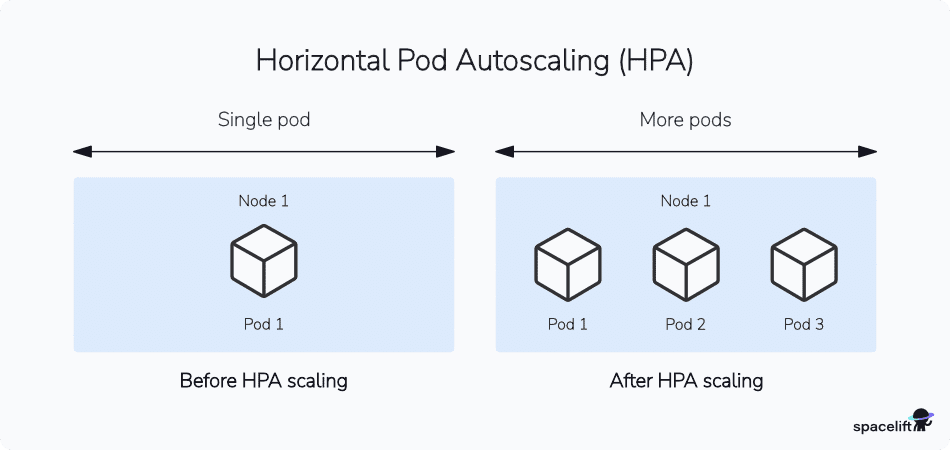
The Horizontal Pod Autoscaler (HPA) is the most common tool for automatically scaling horizontally the number of pods a deployment needs. HPA operates at the application level and monitors metrics such as CPU utilization, memory usage, or custom metrics.
When the tracked metrics exceed the defined thresholds, HPA increases the number of pods accordingly. Similarly, when resource usage drops, HPA scales down the number of pods. The HorizontalPodAutoscaler is implemented as a Kubernetes API resource and a controller.
Vertical Pod Autoscaler (VPA)
Another option for application-level autoscaling is the Vertical Auto Scaling method, which is implemented by the Vertical Pod Autoscaler (VPA).
VPA takes a different approach. Instead of changing the number of pods according to usage, it changes their size. VPA can scale down pods that are over-requesting resources and scale up pods that are under-requesting resources based on their usage over time.

A core difference between the two solutions is that vertical auto-scaling involves downtime. The controller needs to update the pod resources, which forces the pods to be deleted and recreated. VPA should not be used with the HPA on the same resource metric (CPU or memory).
Scaling Kubernetes clusters
HPA handles the scaling of individual workloads, whereas cluster-level scaling is necessary to ensure enough underlying compute resources to accommodate these workloads.
Cluster autoscaling in Kubernetes involves automatically adjusting the number of nodes in a cluster based on resource demands. The cluster autoscaling mechanism adds extra nodes when pods can’t be scheduled due to insufficient resources. Similarly, when nodes are underutilized, they can be removed to optimize costs.
Two of the most popular solutions for cluster autoscaling in Kubernetes include:
- Cluster Autoscaler (CA): This is the traditional, widely adopted, and battle-tested solution that follows a more rigid scaling approach based on predefined node groups and configurations.
- Karpenter: This is a newer, more flexible solution that dynamically provisions nodes based on workload requirements without the need for predefined node groups. It offers faster scaling and better resource optimization.
Both solutions address the same fundamental problem in different ways. In the following sections, we’ll explore each solution in detail.
What is Kubernetes Cluster Autoscaler (CA)?
The Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster by adding or removing nodes in response to resource demands. It ensures your cluster has the right compute resources to handle your workloads efficiently while optimizing costs.
How Cluster Autoscaler (CA) works
CA is triggered and provisions extra nodes when pods are pending to run in the cluster due to insufficient resources. When nodes in the cluster have been underutilized for an extended period of time and their pods can be placed on other existing nodes, CA will also be triggered to delete these nodes.

CA integrates with cloud providers or with Kubernetes’ cluster API, to achieve node management. For example, AWS EKS integrates into Kubernetes using its AWS Auto Scaling group functionality to automatically add and remove EC2 virtual machines that serve as cluster nodes.
Cluster Autoscaler (CA) benefits
Here are the key benefits of using the Cluster Autoscaler:
- Cost and resource optimization: Automatically removes unneeded infrastructure nodes balances resource availability and utilization
- Operational Efficiency: Reduces manual effort and intervention needed for cluster scaling and maintaining infrastructure components
- High Availability (HA): Contributes to HA by ensuring sufficient resources for all pods to run properly
- Multiple Cloud Provider support: Check the README for the available CA list of cloud provider integrations.
Important considerations and best practices for Cluster Autoscaler (CA)
When using a CA in Kubernetes or other environments, you should follow important considerations and best practices to ensure efficient, stable, and cost-effective scaling.
- Set Resource Requests and Limits: For CA to operate efficiently, you must set appropriate resource requests and limits for your application pods.
- The main purpose of CA is to get pending pods to a place to run: CA doesn’t consider the actual CPU or memory usage for scaling decisions. It only checks for pods’ requests and limits to make scaling decisions.
- Combine CA with HPA: HPA and CA work together in a complementary way to manage resources efficiently. When CPU utilization rises, HPA automatically increases the number of pod replicas in a deployment.
If the cluster lacks sufficient resources to schedule these new pods, the CA provides additional nodes. Conversely, when CPU utilization drops, HPA reduces the number of pod replicas. This reduction in pods can leave nodes underutilized or empty, prompting the CA to remove these unnecessary nodes.
- Monitor autoscaling events and adjust configurations: Operating efficiently with CA is not a task you set and forget. Because workloads’ needs change constantly, you have to monitor the autoscaling events of the cluster and tweak configurations accordingly.
- Don’t modify the autoscaled nodes manually: All nodes within the same node group should have the same capacity, labels, and system pods running on them.
- Set pod disruption budgets for critical workloads: Pod disruption budgets limit the number of pods of a replicated application that can be down simultaneously due to voluntary disruptions. They act as a safeguard during cluster operations like node drains or autoscaling, ensuring high availability by preventing too many instances of your application from being unavailable at once.
- Scaling latency: During sudden traffic spikes, CA will request the cloud provider to scale up the cluster. The actual time it takes to create and prepare a new node for hosting your new pods could be several minutes.
What are the limitations of Cluster Autoscaler?
The Cluster Autoscaler adjusts Kubernetes cluster size but faces limitations like scaling delays, unschedulable pods, cloud provider constraints, and challenges with non-evictable pods. It lacks predictive scaling, may struggle with large clusters or cost optimization, and relies on Kubernetes and cloud APIs. Effective planning, PDBs, and complementary tools can help mitigate these issues.
What is Karpenter?
Karpenter is a flexible, high-performant Kubernetes cluster auto scaler built by AWS, which was open-sourced and donated to the Cloud Native Computing Foundation (CNCF) through the Kubernetes SIG autoscaling.
Karpenter automatically launches just the right compute resources to handle your cluster’s applications. It is designed to let you take full advantage of the cloud with fast and simple compute provisioning for Kubernetes clusters.
How does Karpenter work
Karpenter works by watching for pods that the Kubernetes scheduler has marked as unschedulable, evaluating scheduling constraints, provisioning nodes that meet the requirements of the pods, and disrupting the nodes when the nodes are no longer needed.

To configure Karpenter, you create NodePools, which define how Karpenter manages unschedulable pods and configures nodes. Although most use cases are addressed with a single NodePool for multiple teams, multiple NodePools help isolate nodes for billing or use different node constraints (such as no GPUs for a team).
Karpenter will delete nodes when they are no longer needed. If enabled, the Consolidation mode actively attempts to reduce cluster costs by identifying when nodes can be replaced with cheaper variants or removed after shuffling around workloads. Another useful feature of Karpenter relates to drift. Karpenter will mark nodes as drifted and disrupt nodes that have drifted from their desired specification.
Karpenter automatically refreshes nodes after a predefined Expiration setting. This is extremely useful for automating node upgrades. When nodes expire and are terminated, Karpenter spins up a new node with the latest machine image, including the latest software and operating system updates.
Karpenter benefits
Karpenter offers several benefits for scaling Kubernetes clusters:
- Faster node provisioning: Karpenter integrates directly with the cloud provider APIs for spinning up instances and manages each instance directly without the use of additional orchestration mechanisms like node groups. This enables it to retry in milliseconds instead of minutes when capacity is unavailable and allows for improved pod scheduling at scale.
- Cost optimization: Because Karpenter easily considers multiple instance types and purchase options, it provides improved resource efficiency with just-in-time node provisioning, fine-grained resource matching, and automatic cleanup of underutilized nodes. Karpenter integrates nicely with Spot instances and can handle interruptions and mitigations natively.
- Compute flexibility: Different teams and workloads might have different compute needs. Karpenter offers access to diverse instance types and purchase options with a simple configuration and without creating hundreds of node groups.
- Operational benefits: Karpenter offers features such as node expiry and automatically creates new nodes using the latest compatible machine image, effectively simplifying data plane upgrades. This means less maintenance for nodes and upgrades because nodes are replaced automatically with newly provisioned upgraded instances after a predefined time frame.
- Increasing multicloud support: An active community has built up around Karpenter, which has become extremely popular with AWS. Karpenter is currently a multicloud project with additional implementations for Azure and AlibabaCloud that are gathering interest.
Important considerations and best practices for Karpenter
To effectively implement Karpenter, consider the following best practices:
- Use Karpenter for fluctuating workloads: Karpenter shines at fast and efficient autoscaling by bypassing cloud provider abstractions such as node groups to bring flexibility directly to node provisioning. This means Karpenter is best used for clusters with workloads that have high, spiky demand periods or diverse compute requirements.
- Do not run Karpenter on a node that is managed by Karpenter: Karpenter should run on a node that isn’t managed by Karpenter to avoid any issues with scheduling.
- Be flexible with instance type selection: Avoid overly constraining the instance types that Karpenter can provision, especially when utilizing Spot. As a best practice, try to exclude only the instance types that do not fit your workload. The more instance types you allow Karpenter to utilize, the better it can optimize your environments.
- Interruption handling: When Karpenter detects involuntary interruptions such as spot interruptions or scheduled maintenance events, it automatically taints, drains, and terminates the nodes. It does this ahead of time to start a graceful cleanup of workloads before disruption.
- Achieve multi-tenancy with multiple NodePools: Different teams sharing a cluster might need to run workloads with different requirements on different worker nodes or OS types. In these cases, configure multiple NodePools to accommodate multi-tenancy.
- Use TTL to automatically refresh nodes: Node expiry can be used to upgrade so that nodes are retired and replaced with updated versions. See Expiration in the Karpenter documentation for information.
- Resource Usage and High Availability: Define appropriate resource requests and limits for your workloads to ensure Karpenter is performing optimally. When the information about your workload requirements is accurate, Karpenter can launch nodes that best fit your workloads. This is particularly important if you are using Karpenter’s consolidation feature. To ensure your applications are running in a high-availability fashion, implement Disruption Budgets and Pod Topology Spread.
Check out the detailed Getting Started with Karpenter guide for more information on setting things up and follow the Karpenter Workshop to deep dive into all the details.
Karpenter vs Cluster Autoscaler table comparison
The table below summarizes the differences and similarities between Cluster Autoscaler and Karpenter.
| Cluster Autoscaler (CA) | Karpenter | |
| Scaling mechanism | Node group approach; scales predefined node groups. | Dynamically provisions nodes based on real-time pod requirements. |
| Resource utilization and cost optimization | Possibility of having underutilized nodes due to specific node type selection. | Optimized resource usage by “just-in-time” scaling approach by selecting appropriate instance types for workloads. Advanced consolidation features to reduce costs. |
| Cloud provider support | Multiple Cloud Provider Support | Currently: AWS, Azure, AlibabaCloud |
| Spot instance spport | Supported, but limited. | First-class support for Spot instances and interruption handling. |
| Scaling speed | Typical slower due to the reliance on the extra abstraction layer of the Cloud Provider (e.g. Auto Scaling Groups on AWS). | Faster scaling by directly interacting with Cloud Provider APIs for Virtual Machines (EC2). |
| Maturity and adoption | Established and battle-tested. | A newer tool that started focused on AWS, but with growing adoption. |
| Operational characteristics | More complex for diverse workloads since you need to manage multiple node groups; limited flexibility | Focused on simplified operations with features such as Consolidation, Expiry, and Disruption for Spot. Simplified configurations for diversified workloads. |
Key differences between Karpenter and Cluster Autoscaler
Cluster Autoscaler operates at the node group level, adjusting the size of pre-defined node groups based on pending pods, while Karpenter is more flexible. It provisioned individual nodes tailored to workload requirements and supported custom configurations like instance types and zones.
1. Architecture and scaling mechanism
Cluster Autoscaler operates at the node group level leveraging the cloud providers’ abstractions, whereas Karpenter interacts directly with the cloud provider instance provisioning APIs, allowing it to add individual nodes dynamically.
2. Scaling speed
Due to the fact that Cluster Autoscaler operates through predefined node groups and scaling policies, it tends to have slower scaling speed responses compared to Karpenter. Karpenters’ direct interaction with the cloud provider enables it to provision nodes quickly, reducing latency for applications requiring immediate resources.
3. Workload consolidation and compute flexibility
Karpenter allows the selection of instance types and configurations that best match the workload’s current needs. This flexibility makes Karpenter a more responsive and adaptive solution. Cluster Autoscaler may sometimes lead to over-provisioning since it doesn’t always provide optimal and fine-grained selection for specific workloads.
Although Cluster Autoscaler can work with spot instances, it lacks the advanced integration for managing spot interruptions and choosing optimal spot instances that Karpenter offers.
4. Cloud provider integration
In terms of cloud providers and systems support, CA has the upper hand. CA works with multiple cloud providers, whereas Karpenter currently works with AWS, Azure, and Alibaba Cloud.
5. Operational characteristics
Cluster Autoscaler is well-established and battle-tested while offering broader cloud provider support. However, its setup can become complex for diverse workloads when you need to manage multiple node groups, and it offers limited flexibility in general.
Karpenter leverages a more modern design that focuses on simplified operations. Features such as Consolidation, Expiry, and Disruption for Spot make maintenance and upgrades easier for Kubernetes administrators.
6. Use case suitability
Cluster Autoscaler is more suitable for traditional deployment patterns with simple and predictable workloads and predefined configurations. It’s also more versatile in terms of multicloud support, making it a good choice for teams running Kubernetes clusters across multiple cloud environments.
Karpenter is best suited for dynamic workloads and cost-sensitive operations. Its simplified operations approach makes it an excellent fit for cases where you want to reduce operational overhead for undifferentiated heavy lifting with a strong focus on cost optimization.
Although Karpenter started from AWS, it’s expanding to other cloud providers, such as Azure.
Is Karpenter better than Cluster Autoscaler?
Karpenter offers a more dynamic and flexible approach to scaling Kubernetes clusters, with faster scaling times and optimized resource utilization. However, its current primary support for AWS environments may limit its applicability in multicloud scenarios.
Cluster Autoscaler provides a stable, predictable scaling mechanism compatible with multiple cloud providers but may lead to inefficiencies due to its reliance on predefined node groups.
The choice between the two should be based on specific workload requirements, cloud environment, and priorities regarding scaling speed and resource optimization.
Future considerations
As organizations expand their multicloud and hybrid cloud strategies, auto scalers like Karpenter are expected to expand support beyond AWS to include other major cloud providers (check out this GitHub issue). This expansion will offer greater flexibility, enabling workloads to scale seamlessly across diverse infrastructures.
Future auto-scaling solutions are anticipated to leverage AI and ML to predict workload patterns and proactively adjust resources. By analyzing historical data and usage trends, these intelligent systems can optimize scaling decisions, leading to improved performance and reduced costs.
Next, improvements in auto scalers are expected to enable them to become more workload-aware. Autoscalers should be able to consider specific application requirements like latency sensitivity, data locality, and compliance needs to enable more granular and effective scaling decisions.
Managing Kubernetes with Spacelift
For assistance with managing your Kubernetes projects, consider Spacelift. It brings with it a GitOps flow, so your Kubernetes deployments are synced with your Kubernetes stacks, and pull requests offer a preview of what they’re planning to change.
To take this one step further, you could add custom policies to harden the security and reliability of your configurations and deployments. Spacelift provides different types of policies and workflows easily customizable to fit every use case. For instance, you could add plan policies to restrict or warn about security or compliance violations or approval policies to add an approval step during deployments.
You can try it for free by creating a trial account or booking a demo with one of our engineers.
Key points
In this blog post, we compared CA and Karpenter.
CA adjusts the number of nodes in a cluster by interacting with the cloud provider’s APIs based on Kubernetes’ pod scheduling requirements, offering a stable and widely used solution.
Karpenter, on the other hand, provides more flexibility by dynamically provisioning nodes with custom instance types, optimizing for cost and performance, and supporting faster scale-up times, making it a modern alternative for dynamic workloads.
We explored how these tools approach the challenge of automatic Kubernetes cluster scaling in different ways and discussed their benefits and use cases. Finally, we examined their differences and suitability for various use cases.
Manage Kubernetes easier and faster
Spacelift allows you to automate, audit, secure, and continuously deliver your infrastructure. It helps overcome common state management issues and adds several must-have features for infrastructure management.
Kubernetes Autoscaler Docs. Vertical Pod Autoscaler README. Accessed: 17 October 2025
Kubernetes Autoscaler Docs. Cluster Autoscaler README. Accessed: 17 October 2025
Kubernetes Community Docs. Autoscaling Special Interest Group. Accessed: 17 October 2025
Karpenter. Documentation. Accessed: 17 October 2025
Amazon EC2 Auto Scaling User Guide. What is Amazon EC2 Auto Scaling?. Accessed: 17 October 2025
