
Engineers’ methods of developing, testing, building, and deploying their applications and infrastructure have changed several times in the last two decades. Every change has improved the overall workflow, giving teams better ways to implement standardization and build powerful guardrails while improving deployment speed, and offering more stability. One of the methodologies that has emerged is platform engineering.
In this post, we will explore platform engineering, its benefits, the technologies involved, how to build a platform engineering team, and more.
What we will cover:
- What is platform engineering?
- Why is platform engineering important?
- Benefits of platform engineering
- Understanding platform engineering technologies
- How to implement platform engineering?
- How can Spacelift help with platform engineering?
- Best practices in platform engineering
- Challenges in platform engineering
What is platform engineering?
Platform engineering focuses on designing, building, and maintaining platforms that support the development, deployment, and operation of software applications, giving developers speed while maintaining control. The main focus of a platform engineering team is to create a scalable and reusable infrastructure that can be used throughout the organization in multiple teams.
Whereas DevOps engineers focus mostly on CI/CD and site reliability engineers focus more on observability, platform engineers concentrate mainly on infrastructure management and its associated workflow (CI/CD, guardrails, compliance, RBAC).
Why is platform engineering important?
Platform engineering prepares organizations for future improvements. Building a flexible and scalable platform gives organizations the ability to build, deploy, and manage infrastructure and applications more efficiently and reliably.
By leveraging platform engineering, you support scalability, improve developer velocity, increase operational efficiency, and ensure the overall availability and performance of your systems.
Benefits of platform engineering
Platform engineering offers several benefits that enhance the software development lifecycle (SDLC), increase governance and compliance, and enable a collaboration culture and operational efficiency.
1. Streamlined development process
Platform engineering reduces the complexity and time required to build, test, and deploy your applications. This leads to faster delivery times and an improved bug-fixing process.
2. Enhanced developer velocity
When properly implemented, platform engineering always offers developers a self-service mechanism. With access to a self-service mechanism for generating infrastructure that is governed by guardrails, developers can test their changes faster and don’t need to worry too much about the underlying infrastructure.
3. Increased governance and compliance
Enforcing governance policies and staying compliant with your organization’s standards are key to a successful workflow. Automated processes and standardized configurations reduce the risks of human errors, lead to enhanced efficiency, and reduce costs. Such measures set clear guidelines for all teams included in the workflow, implement the RACI framework and ensure all initiatives are executed within the project scope, budget, and timelines.
4. Improved operational efficiency
Platform engineering implements best practices in observability, monitoring, and incident management. Following these practices ensures that issues are detected and resolved quickly and applications run smoothly in the production environment. Also, by adopting specific infrastructure technologies such as infrastructure as code (IaC), configuration management (CM), continuous integration and continuous delivery (CI/CD), and container orchestration (CO), organizations can achieve greater consistency and reliability in their deployments.
5. Increased collaboration
By leveraging platform engineering, you break down silos between development, operations, and security teams by providing a set of shared tools and practices. Collaboration enhances team productivity and encourages innovation.
Understanding platform engineering technologies
Platform engineering teams work with several technologies in different areas to build a powerful platform. Let’s explore these components in detail:
IaC technologies
IaC is the process in which infrastructure is described as code and its entire lifecycle is managed through code and automation rather than leveraging manual processes. By leveraging IaC, you make your infrastructure easily repeatable, simplifying the management of complex environments.
Here are some benefits of using IaC tools:
- Automation – reduces the overall potential of human error by automating repetitive tasks
- Versioning – enables easy reversion to a previous version of your code if you keep it in a VCS
- Idempotency – ensures that running the same code multiple times will produce the same result
- Scalability – scaling your infrastructure to accommodate your needs is easy
Some of the most popular IaC tools are:
- OpenTofu
- Terraform
- Pulumi
- CloudFormation
- Azure Bicep
- Google CDM
You can see a list of the most useful tools here.

Configuration management
CM is the process of automatically configuring your infrastructure after it is provisioned. This ensures that your infrastructure is configured correctly whenever changes are made.
Configuration management introduces the following benefits:
- Automation – gives users the ability to easily configure their virtual machines (VMs) as soon as they are provisioned and minimizes human errors
- Consistency – ensures that all deployments are consistent with their specified configuration
- Scalability – CM is capable of managing thousands of servers, applying changes consistently across large-scale environments
The most popular configuration management tools are:
- Ansible
- Chef
- Puppet
- SaltStack

Continuous integration/Continuous delivery
CI involves frequently integrating code changes into the codebase, followed by automated lint checks, security vulnerability scanning, build and unit, functional, and integration tests. CD is the process by which these code changes are deployed into your environment after going through the CI pipeline.
These are the benefits of using CI/CD:
- Faster and safer deployments – By using CI, you avoid adding any vulnerabilities to your environment and check that all changes will go according to plan. With CD, you ensure that deployments happen whenever you pass all the conditions.
- Automation – You can easily build, test, and deploy your infrastructure/applications without any manual intervention.
- Unlimited integrations – You can easily integrate your preferred tools into your workflow and use them without any manual steps.
- Human error is minimized – Leveraging an automated process ensures that no deployment steps are omitted, guaranteeing everything will work according to plan.
Some of the most popular CI/CD tools are:
- Jenkins
- GitHub Actions
- GitLab CI/CD
- Azure DevOps
- Circle CI

Container orchestration
The process of containerizing an application has changed the way software engineers think about the development process. Splitting an application into microservices has many benefits, such as:
- Isolation – Every microservice will run independently, reducing issues and simplifying the debugging process.
- Scalability – Resources can be easily scaled up or down, based on demand. Auto-scaling capabilities are also available.
- Resilience – Stability is improved because even if you have issues with one service, the entire application will not be affected.
- Faster deployments – Smaller microservices enable quicker development and deployment processes.
Some of the most popular container orchestration tools are:
- K8s
- Docker Swarm
- RedHat OpenShift
- Cloud K8s services (EKS, AKS, GKE)

Monitoring and observability
Monitoring and observability help you maintain the health and performance of your application, which is critical for your organization’s success. Monitoring tracks your application’s performance and availability, whereas observability provides insights into your system.
The main benefits of implementing monitoring and observability into your platform are:
- Quick issue detection – improves stability, and performance and ensures the overall availability of your application
- Increased visibility – brings awareness to your system’s health and infrastructure status
- Capacity planning – helps you analyze usage trends and helps you plan your capacity based on them
- Compliance and auditing – maintains records of the system performance and incidents for compliance and audits
Some of the most popular monitoring and observability tools are:
- DataDog
- Grafana
- Prometheus

Security and compliance
By implementing security measures such as least privilege access, adding vulnerability scanning to your platform, and using a policy mechanism to restrict certain behaviors, you ensure your platform respects industry standards and regulations and your users’ information is safe.
The main benefits of implementing security and compliance measures are:
- Risk mitigation – Protect against data breaches and cyber-attacks.
- Enhanced trust – Build confidence among your users by demonstrating a commitment to protect their data.
- Operational resilience – Improve your organization’s ability to respond to security issues and recover from them.
Some of the most popular security and compliance tools are:
- Vault
- Snyk
- Sonarqube
- Open Policy Agent

Infrastructure management platforms
Infrastructure management platforms combine all the concepts we’ve discussed in a single platform that manages them all.
You get all the concepts’ benefits, plus:
- Efficiency – Reduce manual effort and potential for error.
- Flexibility – The ability to integrate multiple tools in a single workflow and split them into smaller chunks gives you the flexibility required to ensure your organization’s success.
- Improved collaboration – By providing shared tools and best practices, you streamline the collaboration between development, operations, and security.
Some of the most popular infrastructure management platforms are:
- Spacelift
- Terraform Cloud
- Pulumi Cloud
Leading online gaming operator Novibet needed to expand its IaC capabilities to align with its ambitious growth strategy. The Spacelift platform has allowed the team to deploy faster and with more control as they advance toward a platform engineering mindset and enable autonomy with guardrails.
How to implement platform engineering?
The nature of your organization will dictate how you implement platform engineering. However, these general guidelines are useful.

Step 1 – Assess current infrastructure and processes
Transitioning to platform engineering doesn’t mean that you have to remove everything you have in place. You should first asses what works, what doesn’t, and what can be improved.
This translates into three steps:
- Perform an infrastructure audit – Go through the tools you use, and identify how are your resources created, how are they configured, how you do deployments, and everything you have created. This is a thorough, but necessary step for identifying what can be improved. For example, you may already use infrastructure as code, but you may be doing configuration and deployment manually. This would create an action item to identify the configurations, translate them to code, and prepare CI/CD pipelines that would perform the necessary checks, provision your configuration, and configure it.
- Identify pain points and bottlenecks – After performing the audit, examine your biggest pain points and performance issues. Establish whether any of the manual processes you are using could be automated.
- Gather feedback — Feedback will play a crucial role in how platform engineering will be built inside your organization. Don’t overlook input from junior engineers because they may see something senior engineers have missed. You should also seek feedback from your end users.
In this step, it is crucial to take no action, simply take notes about everything you are currently doing. Based on your notes, you will define objectives and goals for your team.
Step 2 – Define objectives and goals
Based on your analysis from the first step, you need to define objectives and goals for your platform team. You should differentiate between short-term and long-term goals and ensure each of these goals is SMART (Specific, Measurable, Achievable, Relevant, and Time-bound). These goals should be aligned with the business strategy to ensure the successful implementation of platform engineering.
Let’s look at an example. In the analysis, you may have noticed that half your infrastructure resources are managed with OpenTofu, and the other half are managed without IaC.
We will define the following goal: “Consistent use of IaC for all our resources”. Let’s see the SMART breakdown:
- Specific – Fully automate infrastructure provisioning using OpenTofu.
- Measurable – Achieve 100% infrastructure provisioning using OpenTofu by monitoring the percentage of resources defined and managed using this tool.
- Achievable – Use the skills of the existing team, train team members lacking experience with IaC, and hire IaC experts to ensure the successful implementation of the goal.
- Relevant – This supports broader platform engineering objectives, and using IaC exclusively will enhance consistency and reduce errors.
- Time-bound – Complete the transition within four months with specific milestones
- Month 1 – Have 25% of resources managed in OpenTofu.
- Month 2 – Have 50% of resources managed in OpenTofu.
- Month 3 – Have 75% of resources managed in OpenTofu.
- Month 4 – Have 100% of resources managed in OpenTofu.
Repeat the process for every objective you want to achieve when building your platform.
Step 3 – Choose the right tools and technologies
Choosing the right tools and technologies can be cumbersome, especially given the multiplicity of choices in today’s market. Imagine shopping for curtains — you have to decide on the material, color, and even how much material to use. The store has many options, so making a well-informed decision can take considerable time.
In this example, your decision will be influenced by factors such as the colors in your room and the cardinal position of your windows (you may want a blackout curtain for a window facing south). All curtains share the same purpose, but your ultimate choice will depend on your needs and preferences.
Choosing platform engineering tools involves a similar process. Many tools share the same purpose, but you need to choose the right tools for your specific use case. Let’s see how you can make the decision easier.
There are four aspects you need to consider when making the decision:
1. Define your criteria
- Compatibility – Ensure the tools you choose are compatible with existing systems and future needs (if you are using Microsoft Azure, you won’t be able to leverage AWS CloudFormation for IaC).
- Scalability – Think of scaling from the beginning and don’t choose tools just because they are popular. Search for case studies related to scale and your tool and see how others have used them. Check out how you can implement infrastructure at scale here.
- Support – Choose tools with active communities and development.
2. Do comparisons and evaluations and read them
IaC, configuration management, container orchestration, CI/CD, monitoring and observability, security, and governance. Evaluate as many tools as possible, request demos, and talk with other companies that have successfully implemented platform engineering using the tools you are considering. Here are some useful comparisons, how-tos, and tops that you can use to evaluate tools:
- 16 most useful infrastructure as code tools
- 13 most useful ci/cd tools for DevOps
- Terraform vs Crossplane
- Pulumi vs Terraform
- Terraform vs Ansible
- 26 Top Kubernetes tools for your K8s ecosystem
- 12 K8s use cases
- Top 10 most popular alternatives for Jenkins
- Using ArgoCD and Terraform
3. Think about how these tools would integrate into your existing workflows
Determine how much you can automate, whether a seamless integration is possible, and the level of manual effort required.
4. Choose tools that align with your team’s skills or based on your hiring budget
If you are not planning to hire any new team members, try to ensure the tools you are using align with your current team’s skills, or you plan different training sessions to upskill your team members.
Step 4 – Build a skilled team
When platform engineering is implemented, the most common split for the infrastructure team is between platform engineers and site reliability engineers. Usually, at least one cloud architect assists the platform team with the platform’s architecture and design. A dedicated security team will also assist with everything related to security, governance, and compliance.
Other roles might include DevOps engineers, automation engineers, and quality assurance engineers.

Let’s explore the responsibilities of the most interesting roles:
- Platform engineers – responsible for designing, building, and maintaining the platform infrastructure
- Site reliability engineers (SREs) – handle deployments to superior environments, are experienced in incident management and response, and have strong problem-solving skills.
- Cloud architects – experts in designing platforms and ensuring the platform architecture is resilient and satisfies all the organization’s needs.
- Security engineers – work hand in hand with the platform engineers and cloud architects to implement and maintain the security best practices for the platform.
Read more: How to Build a Platform Engineering Team
Step 5 – Design the platform architecture
After you have chosen the right team and tools for your platform, you need to architect it. This is where your cloud architects, platform engineers, and security experts work together to define the platform and challenge each other’s opinions to build something worthwhile.
When defining the architecture, you should respect the good architecture principles design:
- Build a modular architecture – The platform should have modular components that can be managed independently and allow for easier maintenance and scalability.
- Implement resilience – Redundancy and failover mechanisms should be in place.
- Keep it simple – The architecture should be kept as simple as possible, to avoid unnecessary complexities.
- Incorporate security best practices – This should be done from the beginning to ensure governance and compliance and minimize data breaches.
Everything should be well documented from the start to speed up the onboarding of new team members and increase efficiency throughout the team.
Commit to the decisions you make, but be mindful that some of your initial plans may not be relevant in the future. Your architecture should be flexible enough to accommodate change.
Step 6 – Build the IaC/CM/CO code
Now that you have an agreed plan in place, it’s time to build the necessary code components to spin up your environments. Build your IaC code, but keep it modular and versioned so you can easily make changes and use different versions of your code when you are testing things. If you are using microservices VMs or both, build your CM and CO code accordingly and consider how these different pieces will work together when you are doing the deployments.
Follow best practices for Terraform, best practices for Ansible, and best practices for K8s, and use these tools for what they were designed to do. It is possible to do CM with OpenTofu or use Ansible to do IaC, for example, but you will have many problems.
You should perform automated tests of the code you are building, including security vulnerability scanning, and build policies for your tools to enforce guardrails.
Step 7 – Build your CI/CD pipelines and/or infrastructure management platforms
By now, you should know whether you will use a CI/CD pipeline, an infrastructure management platform, or both. The recommended approach is to leverage an infrastructure management platform in conjunction with a generic CI/CD pipeline for other aspects of your platform.
You should have implemented a branching strategy, defined the workflows for your tools, integrated testing, and ensured best practices associated with these types of products. In this step, you should also incorporate practices associated with security, compliance, and governance to minimize the risk of human error and reduce the possibility of downtimes.
You should already know whether you will leverage self-service infrastructure for your developers. This is vital for enabling their velocity and can be achieved easily with an infrastructure management platform.
Step 8 – Implement continuous monitoring and observability
At this point, monitoring and observability should be implemented to improve your platform’s availability and resilience. You should already have repositories in place to configure and deploy monitoring, logging, and observability tools in your platform, and they should have comprehensive coverage of everything else that is running in your platform.
With these tools, you should collect metrics on performance and availability. By leveraging log management, you can easily aggregate and analyze this information for troubleshooting and analysis.
Step 9 – Continue improvements
Your platform should be implemented by now. However, the job is not quite yet done because you will always need to make improvements. The more tools you use, the more vulnerabilities they may have, so you always need to keep an eye out to fix them.
Gather feedback from all the parties involved to see what’s going well and what isn’t and make decisions accordingly.
Platform engineering is a continuous process, that doesn’t stop when you have everything in place.
How can Spacelift help with platform engineering?
Spacelift offers all the mechanisms required to build a successful platform. Apart from being the product you can easily leverage in step 7 of how to implement platform engineering, by checking the website, documentation and blog posts, all the other steps can be facilitated.
Let’s explore how Spacelift can help.
1. Policies
With policies, you can control what kind of resources people can create, what kind of parameters these resources can have, build custom policies for third-party tools you integrate into your workflow, control how many approvals you need for runs, and more:
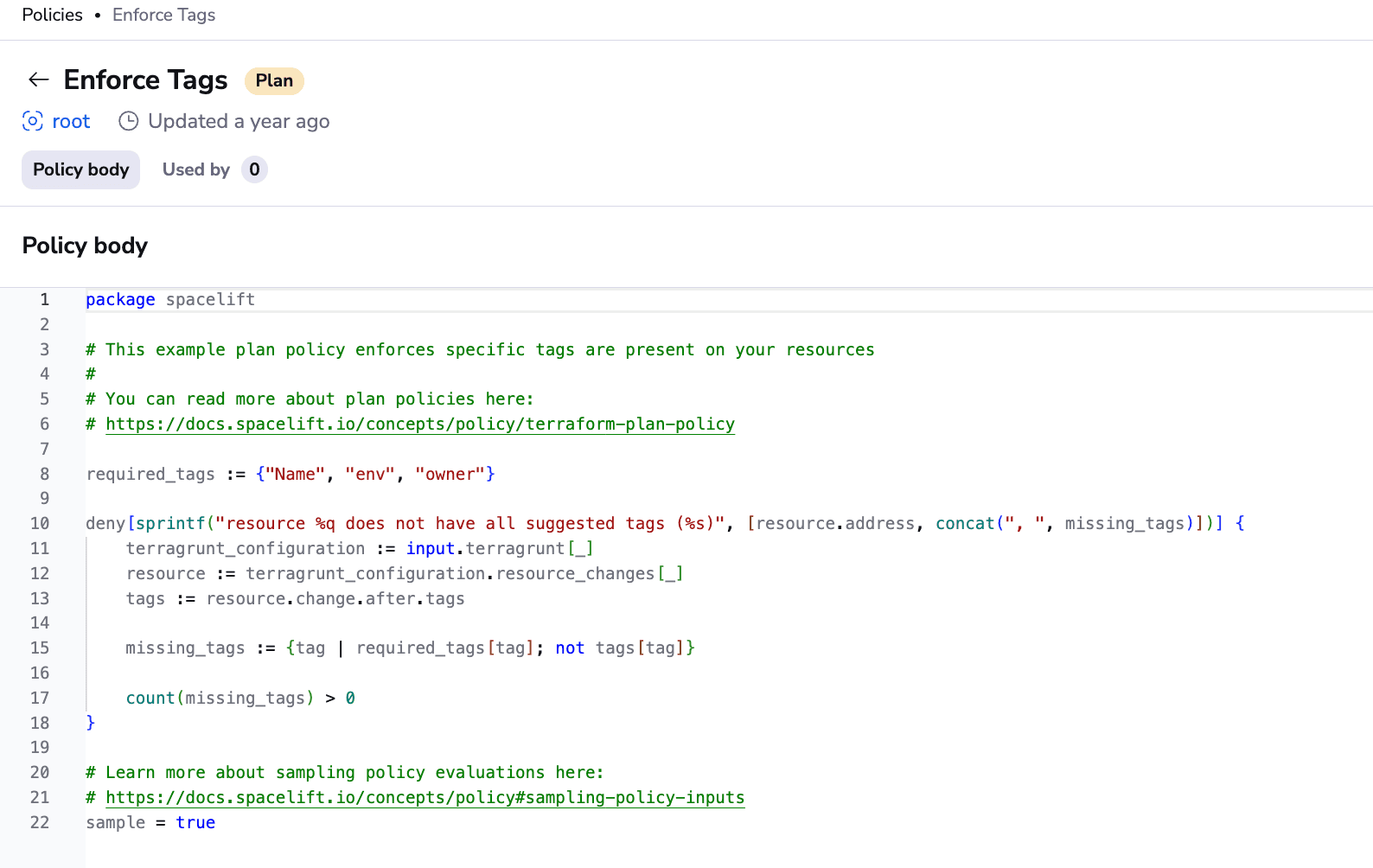
In the above example, we are enforcing a couple of mandatory tags for our resources (Name, env, and owner).
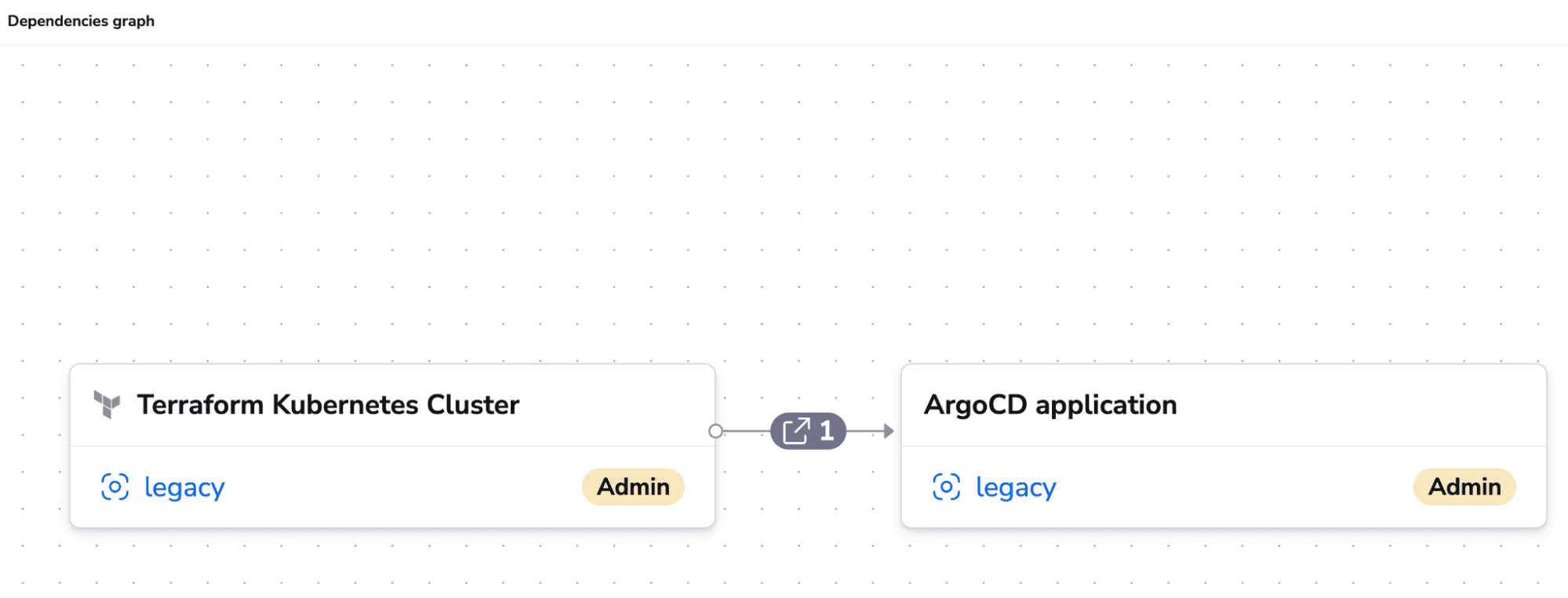
2. Stack dependencies
With stack dependencies, you can build dependencies between your configurations, and even share outputs between them. You don’t have any constraint to the number of dependencies you want to create, and whenever a parent configuration finishes a run successfully, it will trigger runs to its children. As Spacelift supports multiple infrastructure tools, you can build dependencies between them, so a parent stack can use OpenTofu for example, and a child stack can use Kubernetes.
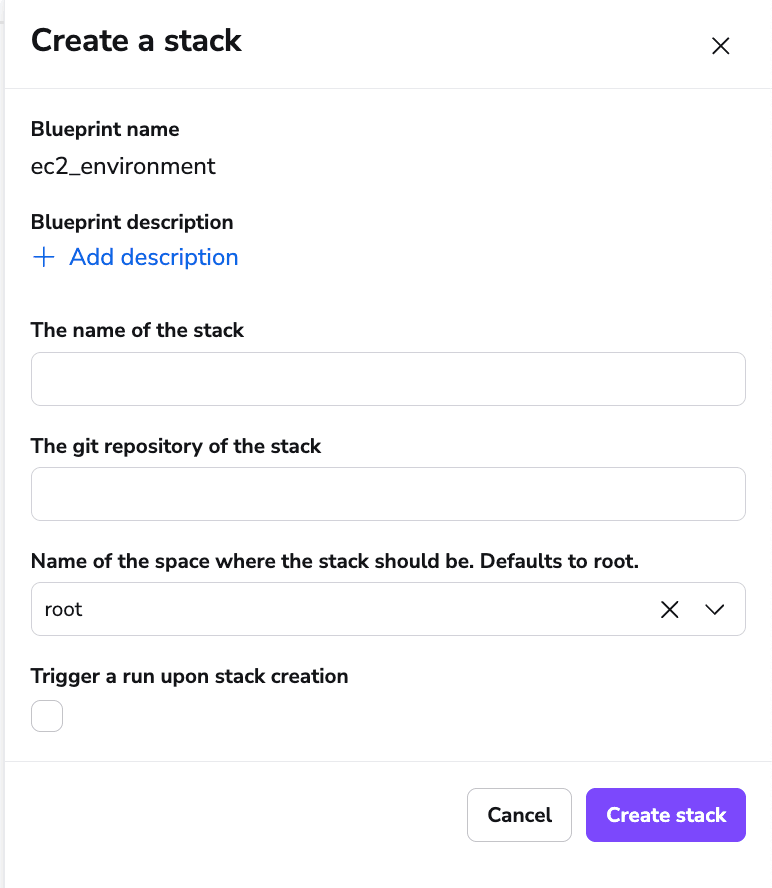
3. Blueprints
Blueprints enable you to configure every aspect of your stack, including governance and compliance. With blueprints, you can create self-service infrastructure, and by this your developer velocity will increase considerably.
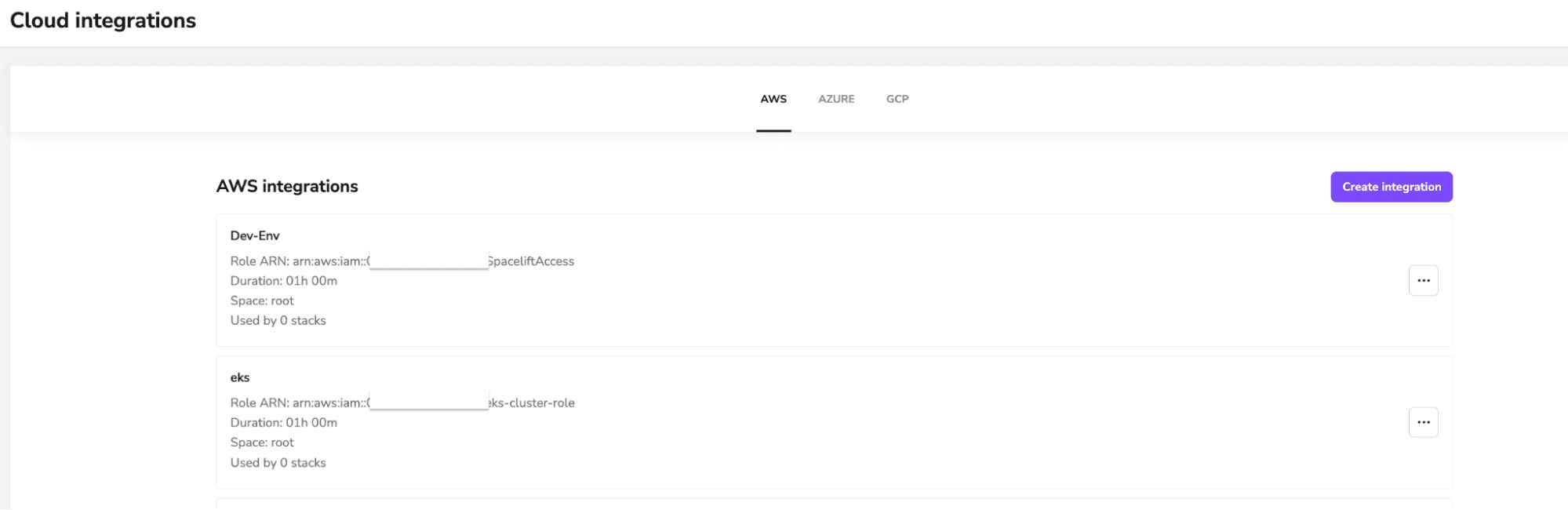
4. Cloud integrations
Static credentials are easily intercepted and can be used with malicious intent. Spacelift understands that, so it offers you the ability to integrate natively with AWS, Microsoft Azure, and Google Cloud to generate dynamic credentials. Based on the roles you are using, these integrations can offer as few or as many permissions as you want:
5. Spaces
Spaces help you implement RBAC, and give partial admin rights to your users.
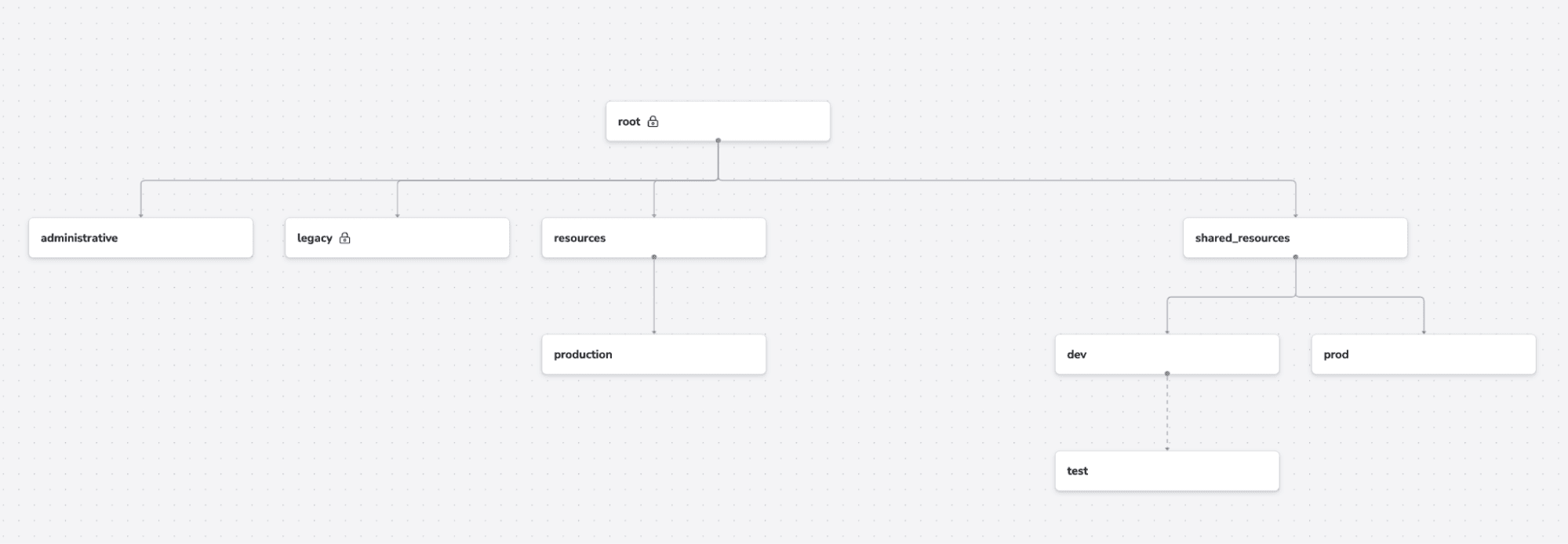
In the above example, if you give a user admin rights to the resources space, and no other rights, he will have all permissions to the resources and production space, but he won’t be able to even view resources in other spaces.
6. Contexts
Contexts are logical containers that can be shared between multiple configurations and contain environment variables, mounted files, and lifecycle hooks, making it easier to ensure reusability and idempotency.

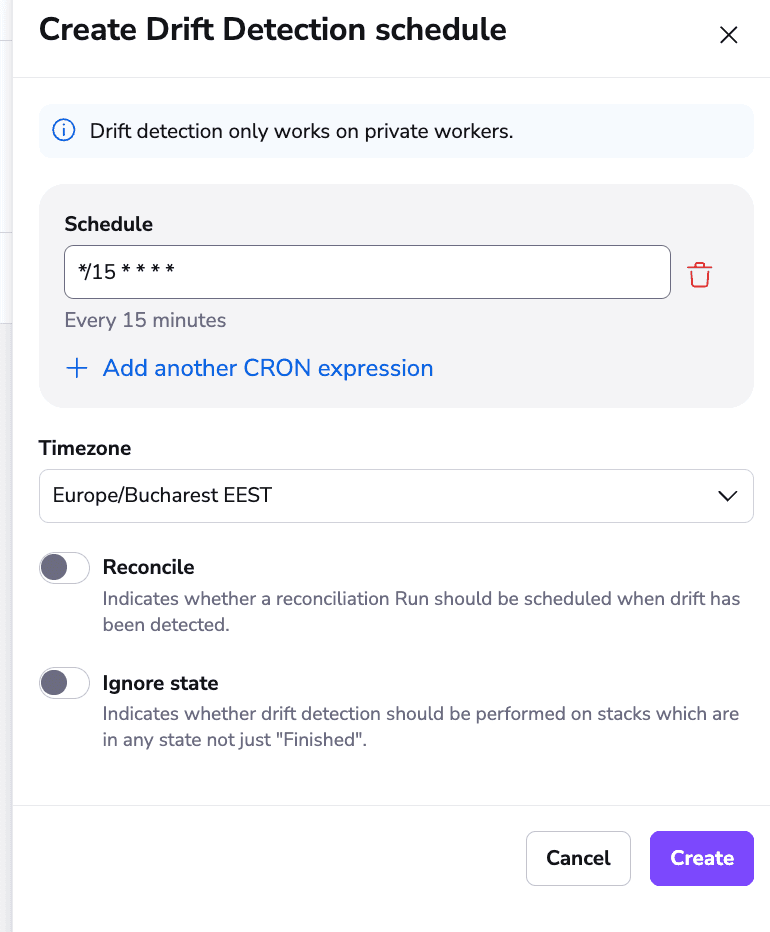
7. Drift detection and optional remediation
Infrastructure drift can be one of the worst problems you can have because if, for example, you fix something manually and then apply the code again at a later time, you will reintroduce the bug into your configuration.
Spacelift offers a drift detection mechanism that runs a schedule that informs you about drift and can optionally remediate it:
8. Resources view
With Spacelift, you can see all the resources that have been deployed into your Spacelift account (based on the permissions you have), details about them and their health:
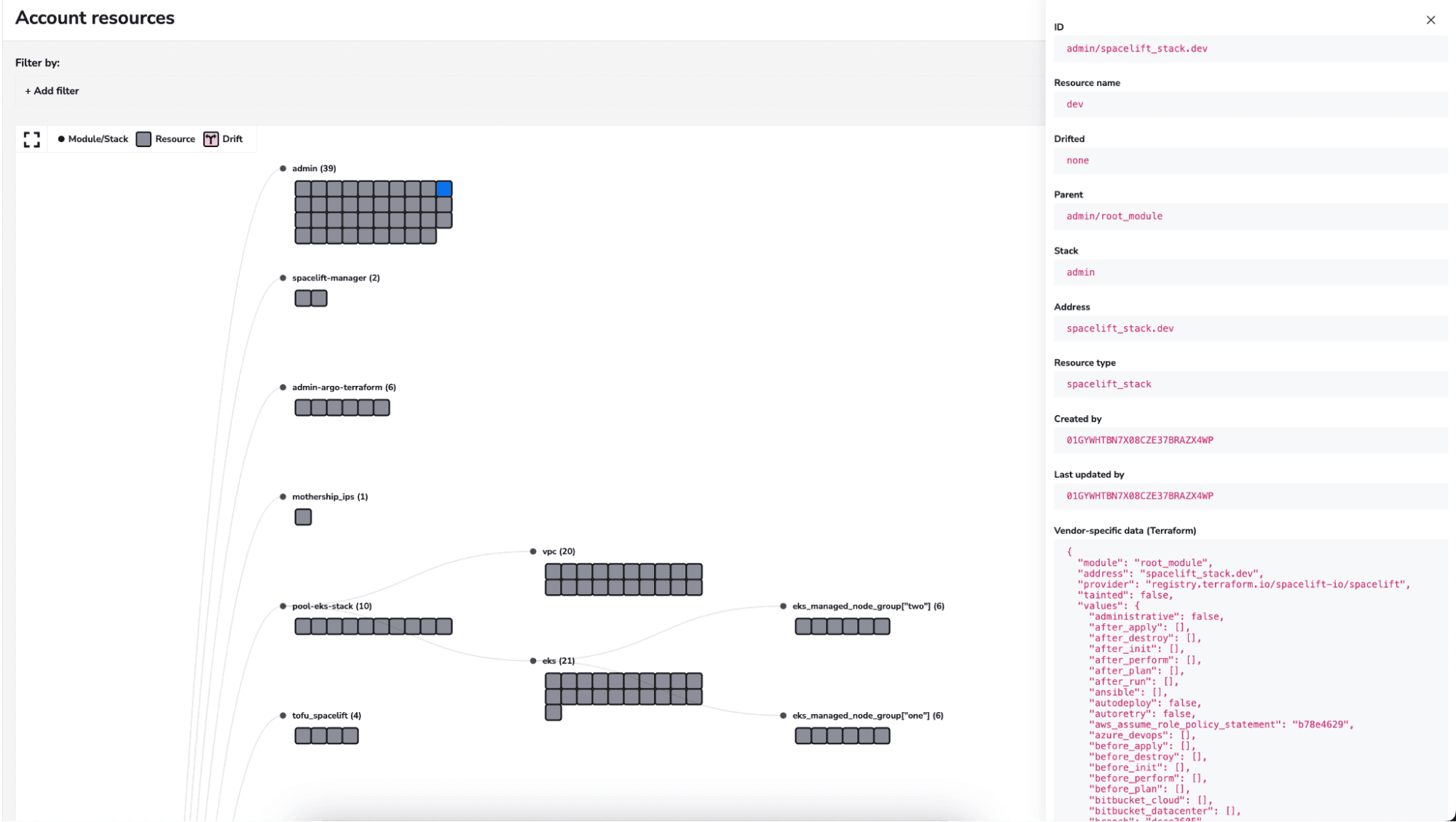
There are other features that Spacelift offers that enable you to enhance your platform’s capabilities.
Best practices in platform engineering
Apart from following all your platform tools’ best practices, you should consider the following when it comes to platform engineering:
- Scalability and flexibility – You should be able to accommodate different tools, especially if you are leveraging open-source because you have already seen how these licenses change. Your platform should be highly scalable to accommodate the different use cases you may face
- Foster a collaboration culture – Communication is key in an organization that leverages platform engineering. Regular retrospectives, knowledge sharing, and even ad-hoc discussions will contribute hugely to the overall success of your platform.
- Embrace continuous improvement – The platform is a living creature. It will continue to improve if you feed it the right things and give it the right amount of exercise. You should continuously search for issues, solve them, and keep improving the platform to make it more resilient and scalable.
- Enable developer velocity – Self-service infrastructure brings both power and responsibility. You need deprovisioning mechanisms to reduce unnecessary costs, and you should also have a channel open for developers to request improvements on the infrastructure they can provision.
Challenges in platform engineering
Here are some of the key challenges in platform engineering and how you can overcome them:
| Challenge | Solution |
| Tools – Compatibility, complexity, and costs | You need to ensure compatibility between the different tools you use, document your work, and regularly review and optimize the infrastructure used to reduce costs by enabling a deprovisioning mechanism and governance. |
| Cultural resistance | Ensure strong leadership support that sets the tone for change and maintain open communication that promotes a safe space where people’s voices can be heard. |
| Security issues | Incorporate security best practices from the beginning and enable standardization and compliance. Implement monitoring and observability to detect and respond to threats. |
| Scaling | Build a platform that enables horizontal and vertical scaling, and takes advantage of auto-scaling wherever possible. All the components you build should be modular, as they can be easily improved and scaled. |
Future trends in platform engineering
Artificial intelligence (AI), machine learning (ML), and generative AI (GenAI) will play pivotal roles in how we think about platform engineering. GenAI can help build boilerplate code that platform engineers can improve, and AI/ML can be used to predict and optimize infrastructure performance and detect anomalies.
Event-driven architectures have become increasingly popular, and serverless technologies could be used more in platform engineering. By simplifying infrastructure management, they could accelerate the development and deployment of the platform.
Key points
In this post, we have explored platform engineering, how to implement it, and the best practices surrounding it.
Many factors contribute to a platform’s success. One of them is infrastructure management, which incorporates all your workflow tools in a single place.
To find out more about Spacelift’s infrastructure management platform, create an account today or book a demo with one of our engineers.
Solve your infrastructure challenges
At Spacelift, we understand that you need a platform that not only helps you with infrastructure provisioning, configuring, and governing but also fosters collaboration and increases developer velocity.
CIO. The RACI matrix: Your blueprint for project success. Accessed: 22 October 2025
Microsoft Learn. Platform engineering principles. Accessed: 22 October 2025
GitHub Resources. What is Platform engineering?. Accessed: 22 October 2025
