
Managing Kubernetes environments means dealing with two distinct layers of state: the infrastructure your cluster runs on (VPCs, node groups, IAM roles) and the applications running inside it. Handling these separately creates drift, where what’s running in the cluster no longer matches what’s defined in code, leading to inconsistencies across environments that are difficult to debug and costly to fix.
GitOps addresses this by making Git the single source of truth for both layers. Terraform handles the infrastructure side declaratively, while ArgoCD continuously reconciles the desired application state in Git with what’s actually deployed in the cluster, automatically correcting any drift. Together, they give you a consistent, auditable, and automated delivery workflow across your entire Kubernetes stack.
What we will cover:
TL;DR
This tutorial walks you through provisioning an EKS cluster and deploying ArgoCD with Terraform, then wiring up a GitHub Actions pipeline to automate the entire workflow. You’ll end up with a fully GitOps-driven setup where both your infrastructure and application state are managed declaratively from a single Git repository.
Why use ArgoCD with Terraform?
Using ArgoCD with Terraform combines infrastructure provisioning with application delivery into a single, coherent GitOps workflow. Each tool solves a distinct problem: Terraform provisions and manages the resources your cluster depends on, whereas ArgoCD takes over once the cluster is running, keeping your applications in sync with what’s defined in Git.
Here are the key benefits of using them together:
- Declarative infrastructure as code (IaC) and application management – Both tools share a declarative model: you describe the desired state and let the tool figure out how to get there. Terraform reconciles your cloud infrastructure against your HCL configuration, and ArgoCD continuously reconciles your Kubernetes workloads against your Git repository. This consistency across both layers makes your entire stack easier to reason about, review, and audit.
- GitOps workflow – You can achieve a GitOps workflow for both tools: out of the box for ArgoCD, and with a specialized product for Terraform. In GitOps, Git is the single source of truth, so you can manage your workflow and keep everything in sync. (Read more about Terraform GitOps.)
- Consistency – Using ArgoCD and Terraform together, you deploy the same configuration across environments, reducing the risk of errors and discrepancies between staging and production.
- Automated drift correction – Without continuous reconciliation, Kubernetes clusters drift. Someone applies a hotfix manually, a node group is updated out of band, or a config change lands directly in the cluster without going through Git. ArgoCD detects these deviations automatically and can correct them without manual intervention, whereas Terraform provides the same guarantee at the infrastructure level.
- Full auditability – Every infrastructure change made with Terraform and every application change synced by ArgoCD traces back to a Git commit. This gives you a complete history of what changed, when, and who approved it, without relying on cloud provider logs or kubectl audit trails, which is particularly valuable for teams working under compliance requirements.
Tutorial: How to manage Kubernetes cluster with ArgoCD and Terraform
Let’s build an automation that showcases how to manage a K8s cluster with ArgoCD and Terraform.
Prerequisites
For this automation, you need to have an AWS account, everything else will be built and shared during the tutorial. You can get the repository code here.
Step 1 – Prepare Terraform code for EKS
To ensure everything works smoothly, we will create all the components necessary to have an EKS cluster running:
- Network (VPC, Subnets, Route table, Internet Gateway)
- IAM (Role and Policies)
- Node Group
- EKS cluster
Network resources:
data "aws_availability_zones" "available" {}
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "main-vpc"
}
}
resource "aws_subnet" "public_subnet" {
count = 2
vpc_id = aws_vpc.main.id
cidr_block = cidrsubnet(aws_vpc.main.cidr_block, 8, count.index)
availability_zone = data.aws_availability_zones.available.names[count.index]
map_public_ip_on_launch = true
tags = {
Name = "public-subnet-${count.index}"
}
}
resource "aws_internet_gateway" "main" {
vpc_id = aws_vpc.main.id
tags = {
Name = "main-igw"
}
}
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.main.id
}
tags = {
Name = "main-route-table"
}
}
resource "aws_route_table_association" "a" {
count = 2
subnet_id = aws_subnet.public_subnet.*.id[count.index]
route_table_id = aws_route_table.public.id
}We are creating one VPC, two subnets for the EKS nodes, an internet gateway, and a route table with a rule to the internet gateway. We associate the route table with the two subnets.
Next, we create a node role and a cluster role:
locals {
policies = ["arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy", "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy", "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"]
}
resource "aws_iam_role" "eks_cluster_role" {
name = "eks-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "eks.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
tags = {
Name = "eks-role"
}
}
resource "aws_iam_role_policy_attachment" "eks_cluster_role_attachment" {
role = aws_iam_role.eks_cluster_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
}
resource "aws_iam_role" "eks_node_role" {
name = "eks-node-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
tags = {
Name = "eks-node-role"
}
}
resource "aws_iam_role_policy_attachment" "eks_role_attachment" {
for_each = toset(local.policies)
role = aws_iam_role.eks_node_role.name
policy_arn = each.value
}Finally, we create the EKS cluster and the EKS node group:
resource "aws_eks_cluster" "main" {
name = "main-eks-cluster"
role_arn = aws_iam_role.eks_cluster_role.arn
vpc_config {
subnet_ids = aws_subnet.public_subnet.*.id
}
tags = {
Name = "main-eks-cluster"
}
}
resource "aws_eks_node_group" "main" {
cluster_name = aws_eks_cluster.main.name
node_group_name = "main-eks-node-group"
node_role_arn = aws_iam_role.eks_node_role.arn
subnet_ids = aws_subnet.public_subnet.*.id
scaling_config {
desired_size = 2
max_size = 3
min_size = 1
}
tags = {
Name = "main-eks-node-group"
}
}Step 2 – Prepare the Terraform code that deploys ArgoCD
For this deployment, we will use the helm provider to deploy the ArgoCD Helm chart in our Kubernetes cluster. It will also deploy a load balancer to access it.
data "aws_eks_cluster_auth" "main" {
name = aws_eks_cluster.main.name
}
resource "helm_release" "argocd" {
depends_on = [aws_eks_node_group.main]
name = "argocd"
repository = "https://argoproj.github.io/argo-helm"
chart = "argo-cd"
version = "9.5.3"
namespace = "argocd"
create_namespace = true
set {
name = "server.service.type"
value = "LoadBalancer"
}
set {
name = "server.service.annotations.service\\.beta\\.kubernetes\\.io/aws-load-balancer-type"
value = "nlb"
}
}
data "kubernetes_service" "argocd_server" {
metadata {
name = "argocd-server"
namespace = helm_release.argocd.namespace
}
}The version above reflects the latest ArgoCD Helm chart at the time of writing. Since the chart releases frequently, check the official releases page for the most current version before deploying.
Step 3 – Configure remote state
It is essential to keep your state in a remote location. You can learn more in our guide: How to manage Terraform remote state.
For our example, we will use an S3 backend:
terraform {
required_version = "1.5.7"
backend "s3" {
bucket = "your-bucket-name"
key = "your-bucket-key"
region = "eu-west-1"
}
}You will need to specify a bucket name, the region where the bucket can be found, and a name for your state file.
Step 4 – Run the Terraform code
First, navigate to the directory that contains your Terraform code and run terraform init.
terraform init
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Finding latest version of hashicorp/kubernetes...
- Finding latest version of hashicorp/helm...
- Installing hashicorp/aws v5.50.0...
- Installed hashicorp/aws v5.50.0 (signed by HashiCorp)
- Installing hashicorp/kubernetes v2.23.0...
- Installed hashicorp/kubernetes v2.23.0 (unauthenticated)
- Installing hashicorp/helm v2.13.2...
- Installed hashicorp/helm v2.13.2 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.Let’s apply the code:
terraform apply -auto-approve
...
Plan: 16 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ argocd_initial_admin_secret = "kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath={.data.password} | base64 -d"
+ argocd_server_load_balancer = (known after apply)
+ eks_connect = "aws eks --region eu-west-1 update-kubeconfig --name main-eks-cluster"It takes about ten minutes for all the resources to be created.
Apply complete! Resources: 16 added, 0 changed, 0 destroyed.
Outputs:
argocd_initial_admin_secret = "kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath=\"{.data.password}\" | base64 -d"
argocd_server_load_balancer = "a53a6bf4abebe46f79da6179425ca5f4-7d359c1121a50305.elb.eu-west-1.amazonaws.com"
eks_connect = "aws eks --region eu-west-1 update-kubeconfig --name main-eks-cluster"Step 5 – Prepare the Kubernetes manifests to deploy a sample nginx application
In this step, we want to prepare the configuration that will be deployed with ArgoCD. We will create a simple nginx application that will output “Hello from Argo”. For that, we will need a configmap, a deployment, and a service:
# confimap_yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-config
namespace: default
data:
index.html: |
<html>
<head><title>Hello from Argo</title></head>
<body>
<h1>Hello from Argo</h1>
</body>
</html>In the Kubernetes configmap, we save the index.html configuration file that will be used by our nginx deployment.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
volumeMounts:
- name: nginx-config-volume
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-config-volume
configMap:
name: nginx-configIn the deployment file, we specify which containers we want to use (nginx in our case), and we mount our configmap to get the index.html file.
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: default
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancerWe will expose our application through a load balancer service.
Step 6 – Create the ArgoCD application manifest
Before creating the manifest, we need to ensure that we push this code to a VCS repository. If you are using the repository I have provided, you can leave this file as it is. Otherwise, you should make it point to the correct repository.
The ArgoCD application manifest will look like this:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: nginx-app
namespace: argocd
spec:
project: default
source:
repoURL: 'https://github.com/saturnhead/eks-argo-terraform'
targetRevision: HEAD
path: 'argocd/app'
destination:
server: 'https://kubernetes.default.svc'
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueNow, we need to connect to our Kubernetes cluster. This can be done by running the following command:
aws eks --region eu-west-1 update-kubeconfig --name main-eks-clusterNext, we can run our application manifest:
kubectl apply -f argocd-app.yaml
application.argoproj.io/nginx-app createdStep 7 – Log in to Argo and see the application
To log in to Argo, we can use the outputs exposed by our Terraform code:
argocd_initial_admin_secret = "kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath={.data.password} | base64 -d"
argocd_server_load_balancer = "a53a6bf4abebe46f79da6179425ca5f4-7d359c1121a50305.elb.eu-west-1.amazonaws.com"We need to get the initial ArgoCD admin secret, so we can run the first command for that:
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath=\"{.data.password}\" | base64 -d"Now, open a browser and go to the argocd_server_load_balancer address:

Use admin as the username and provide the password you got when you ran the first command.
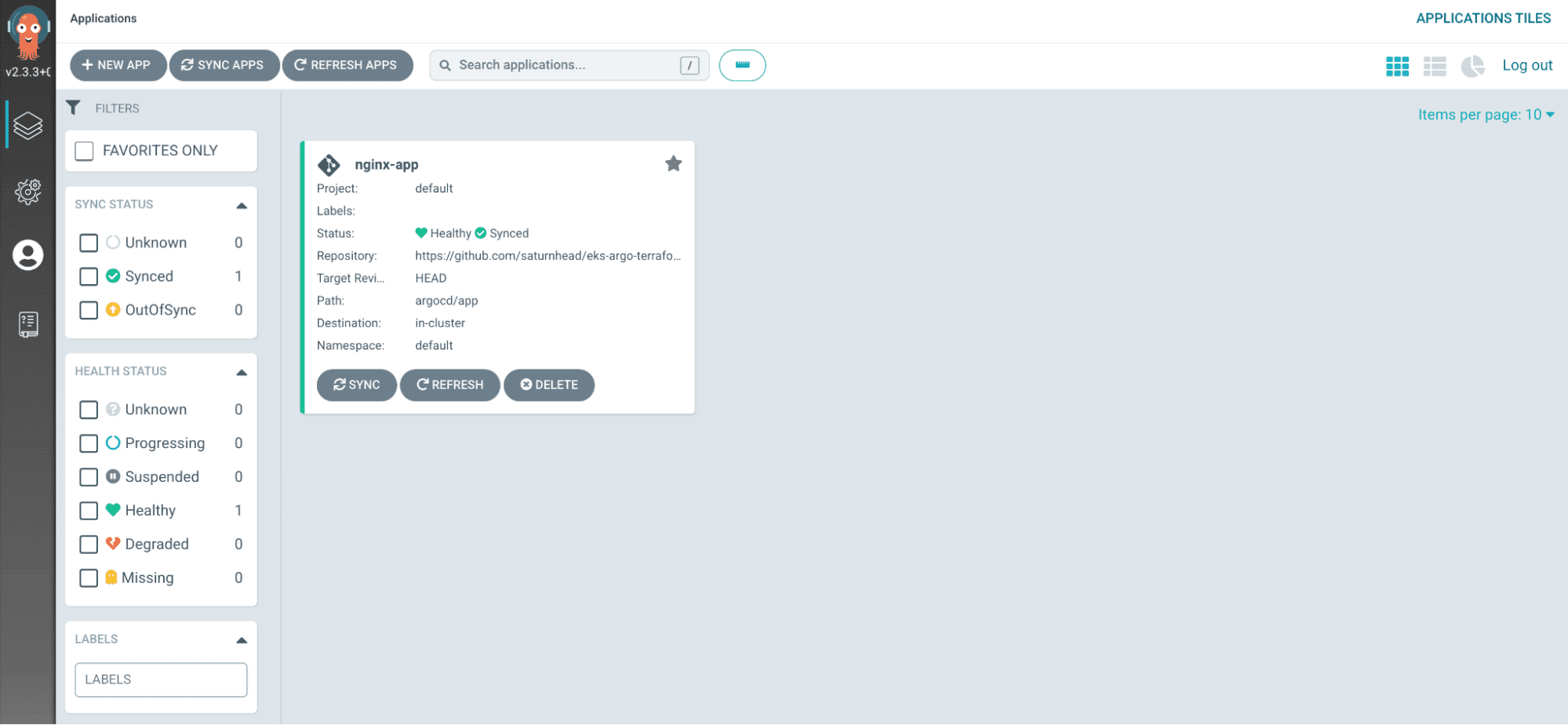
You should see your application healthy and synced. If you click on it, you will see all the resources that have been deployed with Argo:
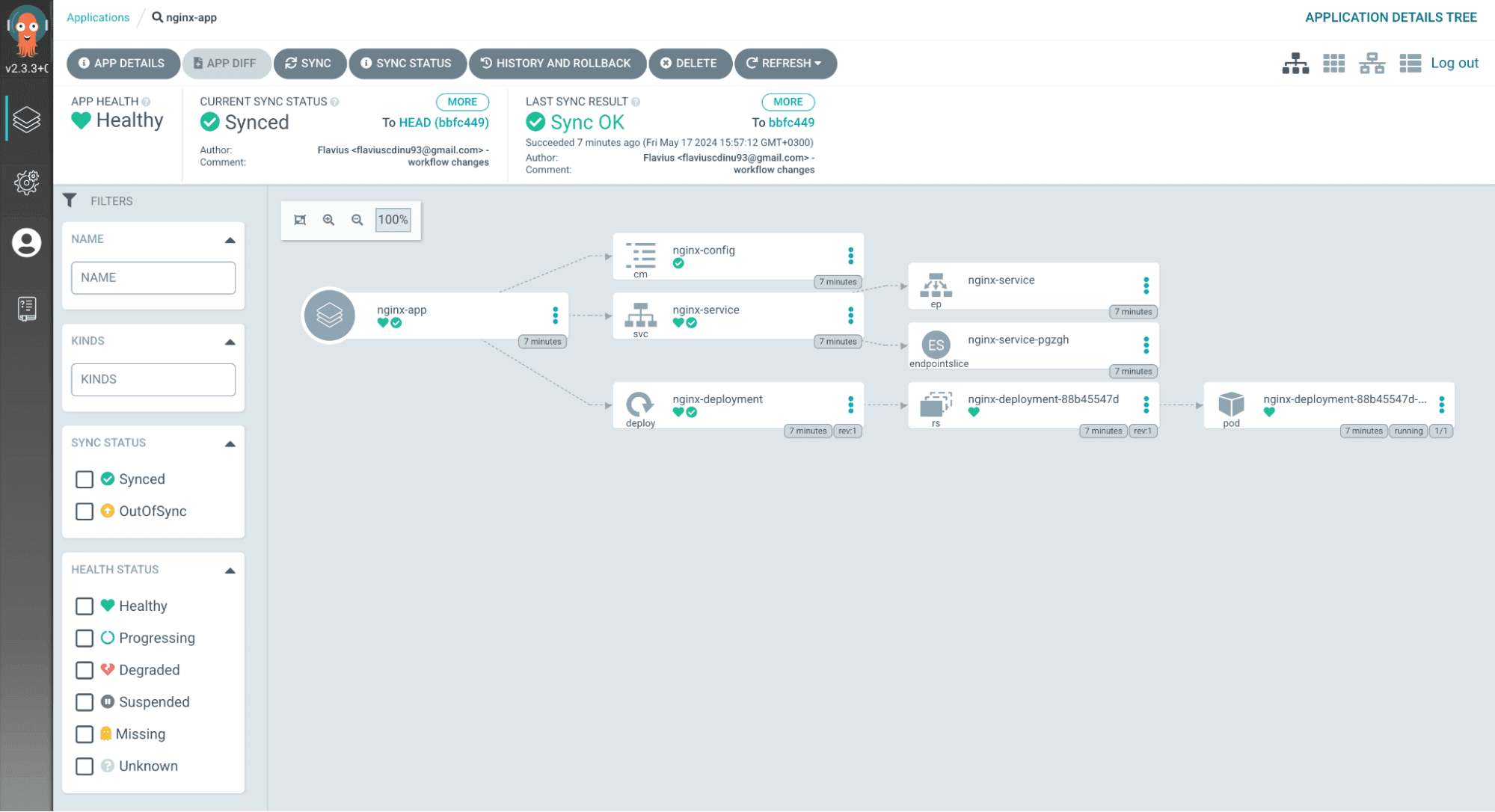
If you want to access the application itself, select the nginx-service, go to the last line of the manifest, select the hostname, and paste it into your browser:

Download the Build vs. Buy Guide to Scaling Infrastructure as Code

Managing Kubernetes cluster with ArgoCD, Terraform, and GitHub Actions
Let’s take the above automation to the next step and deploy it through a GitHub Actions pipeline to enable collaboration and ensure that you won’t need to do anything manually.
We will build three different workflows:
- Terraform deployment
- ArgoCD application deployment
- Tearing down the infrastructure and application
Step 1 – Prerequisites
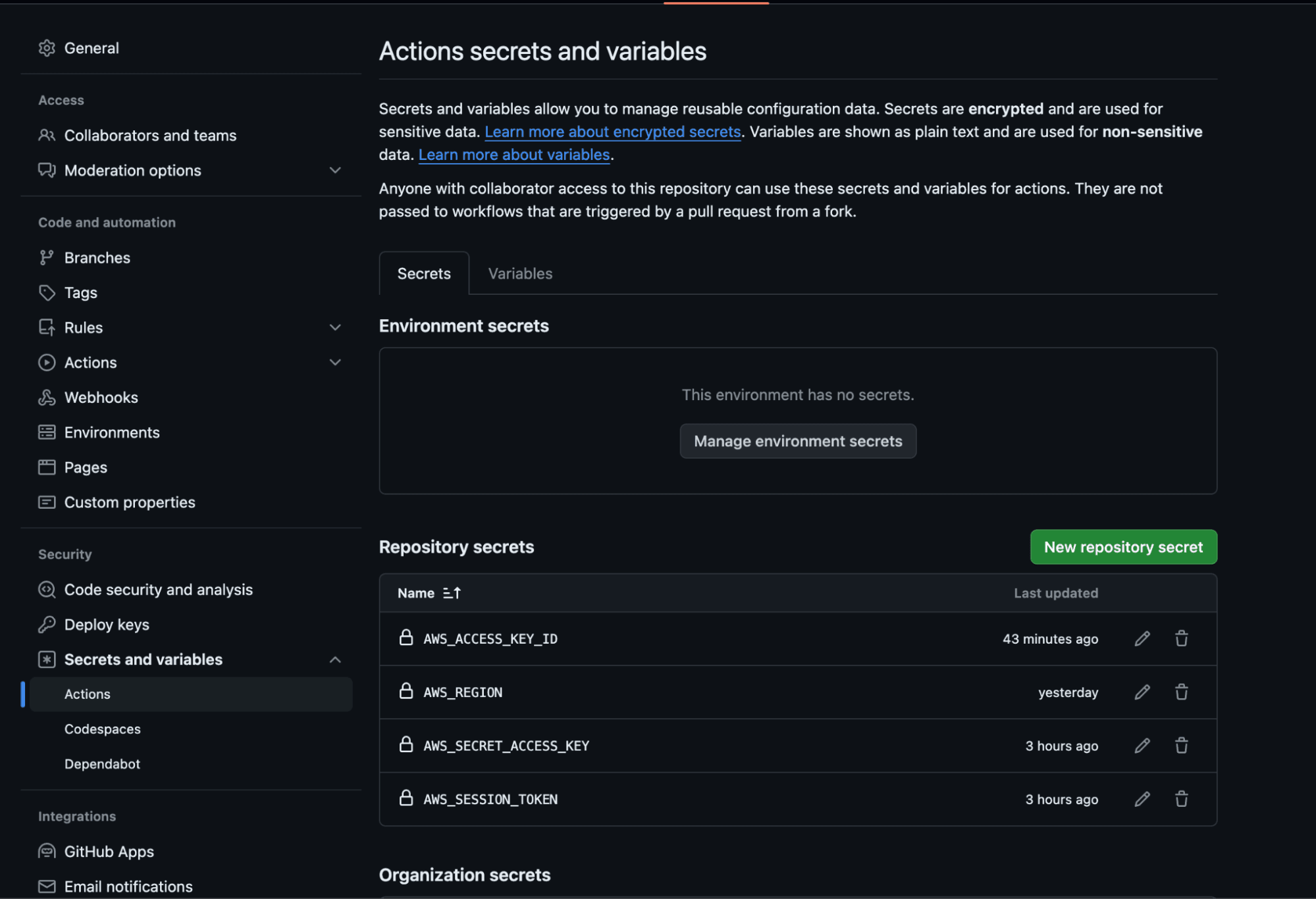
For all of these deployments, we need to define some GitHub Actions secrets for the AWS credentials. We need to use:
AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY
AWS_REGION
AWS_SESSION_TOKENTo add a secret to your repository, navigate to the repository’s settings, select Secrets and Variables, and click on Actions.
Step 2 – Prepare the Terraform creation workflow
You can find the workflow file here.
This workflow will run on pull requests, and main branch merges whenever there are changes to the Terraform directory in the repository. For pull requests, it will also show the plan as a PR comment.
The workflow does the following:
- Checks out the code
- Sets up Terraform
- Sets up the AWS credentials
- Runs
terraform init - Runs
terraform validateto ensure the configuration is valid - Runs
terraform fmtto check if the code is formatted correctly - Runs a
terraform planand comments on the plan on a PR only on pull requests - Runs a
terraform applyon a master branch push
Step 3 – Prepare the Argo creation workflow
The workflow file can be found here.
This workflow will run whenever the ArgoCD folder changes or when the Terraform workflow finishes successfully from the main branch.
It goes through the following steps:
- Checks out the code
- Verifies if the workflow was triggered from the main branch
- Configures AWS credentials
- Installs kubectl
- Updates the kubeconfig
- Deploys the application
Step 4 – Prepare the destruction workflow [Optional]
The workflow file can be found here.
It only runs manually and goes through the following steps:
- Checks out the code
- Sets up Terraform
- Sets up the AWS credentials
- Installs kubectl
- Deletes the argocd application
- Runs
terraform init - Runs
terraform destroy
Step 5 – Trigger a run
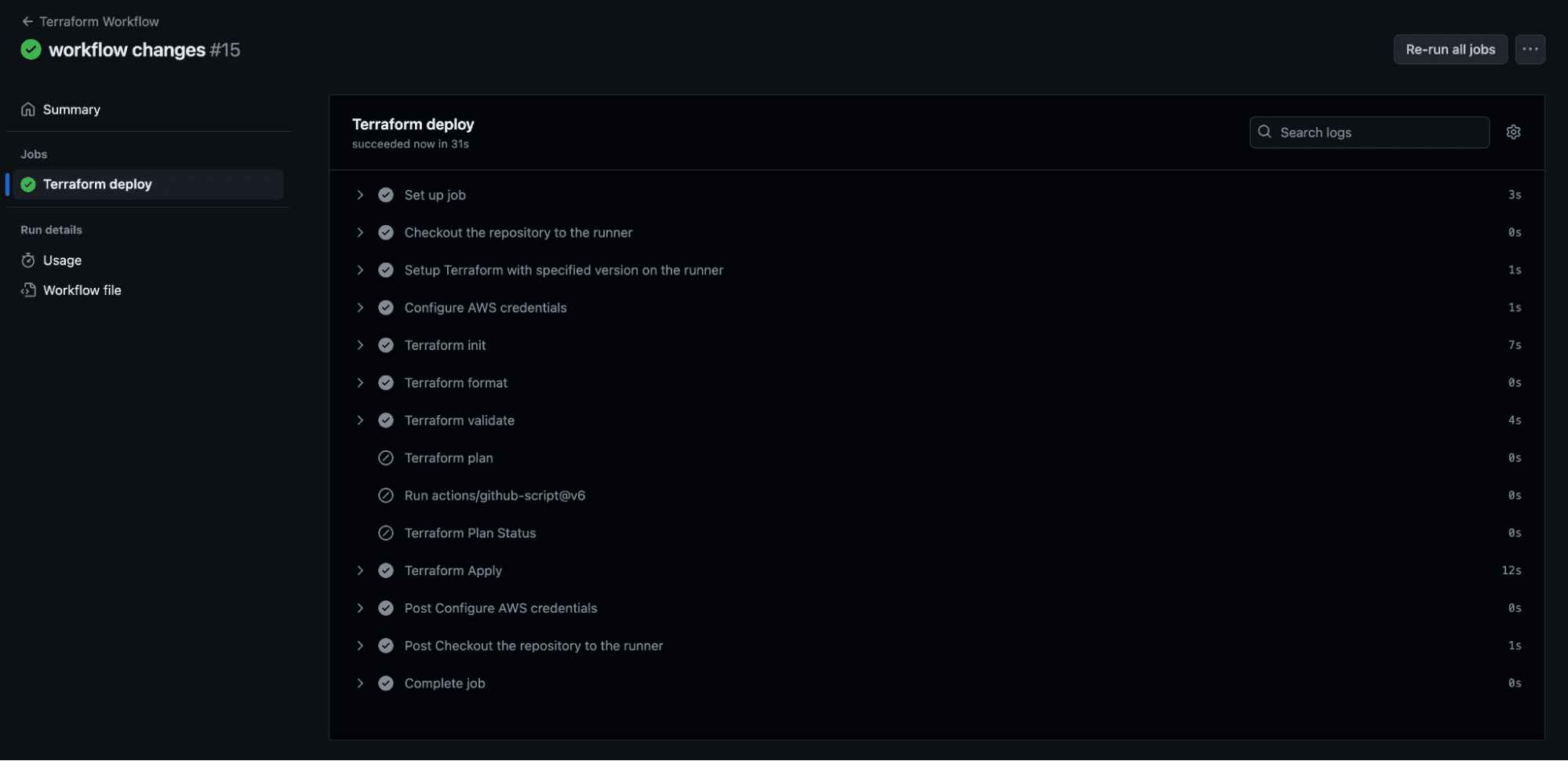
Make a dummy change to your Terraform code and see the pipelines get triggered (I just added a new line).
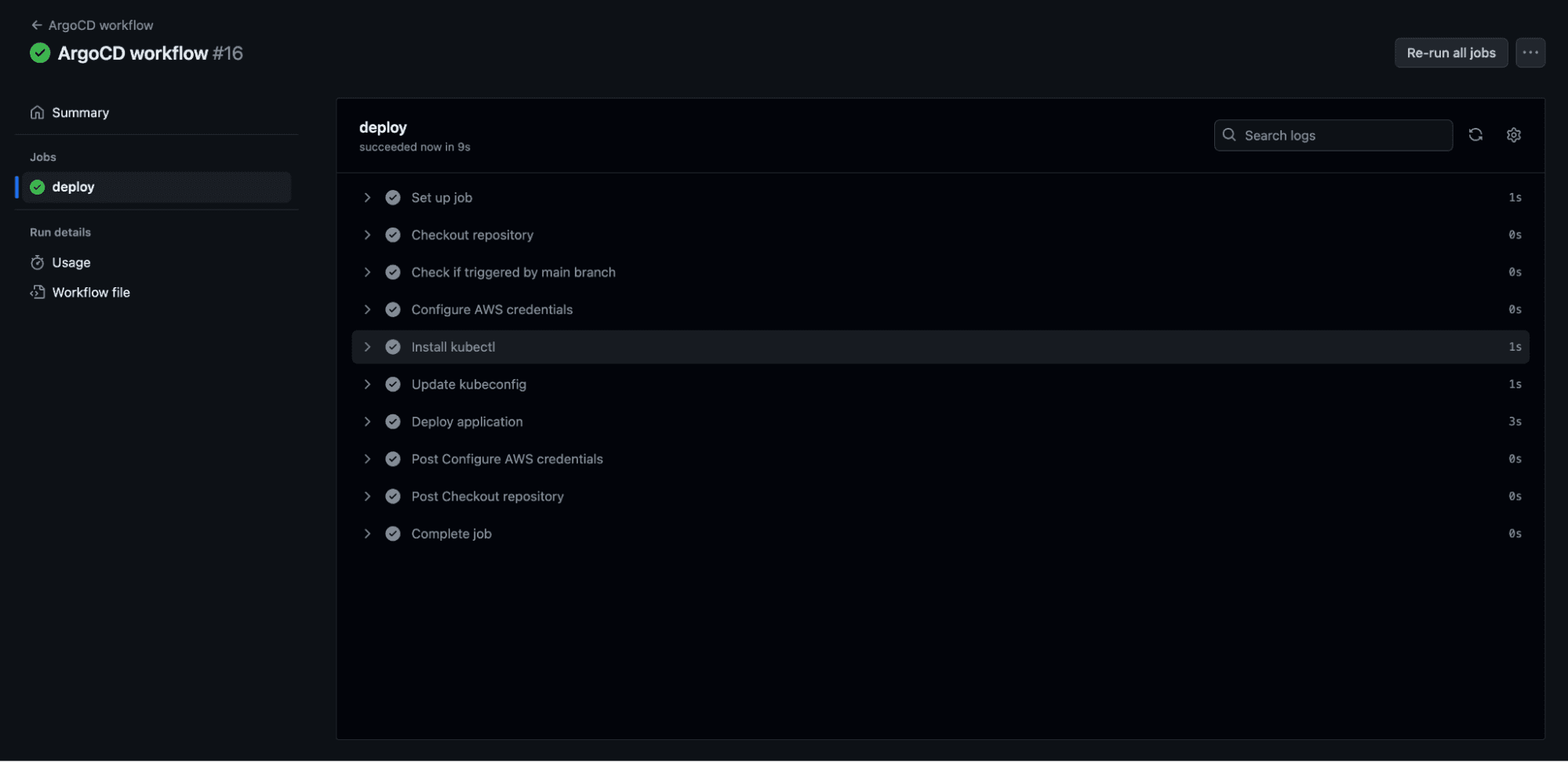
Managing Terraform & Kubernetes with Spacelift
To take your infrastructure orchestration to the next level, you can leverage Spacelift. Spacelift is the infrastructure orchestration platform built for the AI-accelerated software era. It manages the full lifecycle for both traditional infrastructure as code (IaC) and AI-provisioned infrastructure.
Spacelift supports both Terraform and Kubernetes and enables users to create stacks based on them. With stack dependencies, you can build end-to-end workflows that combine Terraform provisioning with Kubernetes configuration, getting the best of each tool.
You manage your Terraform and Kubernetes resource lifecycles from a single platform, with policies for governance and access control, drift detection to catch out-of-band changes, and self-service Blueprints and Templates so your teams can collaborate without sacrificing security.

"IaC and immutable infrastructure are really important concepts to Kin. They chose Terraform as their platform and very quickly adopted a full-blown GitOps workflow. When you shift to treating infrastructure like a software project, you need all of the same components that a software project would have. That means having a CI/CD platform in place, and most aren’t suited to the demands of IaC. Kin discovered that Spacelift was purpose-built to fill that gap."
Step 1 – Build the stack automation
Let’s build the same integration we built for GitHub actions. To automate as much as possible, I will create the deployment stacks using OpenTofu:
provider "spacelift" {}
terraform {
required_providers {
spacelift = {
source = "spacelift-io/spacelift"
}
}
}
resource "spacelift_stack" "K8s-cluster" {
branch = "main"
description = "Provisions a Kubernetes cluster"
name = "Terraform Kubernetes Cluster"
project_root = "terraform"
repository = "eks-argo-terraform"
terraform_version = "1.5.7"
labels = ["terraform-argocd"]
}
resource "spacelift_stack" "argocd" {
kubernetes {
namespace = "argocd"
}
branch = "main"
description = "Deploys an ArgoCD application"
name = "ArgoCD application"
project_root = "argocd/config"
repository = "eks-argo-terraform"
labels = ["terraform-argocd"]
before_init = ["$AWS_LOGIN"]
}
resource "spacelift_aws_integration_attachment" "K8s-cluster" {
integration_id = var.integration_id
stack_id = spacelift_stack.K8s-cluster.id
read = true
write = true
}
resource "spacelift_aws_integration_attachment" "argocd" {
integration_id = var.integration_id
stack_id = spacelift_stack.argocd.id
read = true
write = true
}
resource "spacelift_stack_dependency" "cluster-argo" {
stack_id = spacelift_stack.argocd.id
depends_on_stack_id = spacelift_stack.K8s-cluster.id
}
resource "spacelift_stack_dependency_reference" "output" {
stack_dependency_id = spacelift_stack_dependency.cluster-argo.id
output_name = "eks_connect"
input_name = "AWS_LOGIN"
}We are creating two stacks that will leverage an existing cloud integration for AWS (this will generate dynamic credentials), and we will build a stack dependency between them. The Terraform stack will deploy the Kubernetes cluster and ArgoCD as before, and the K8s stack will depend on it and receive the kubeconfig login command as an output. The stacks will leverage the same code as before.
You can check out how to configure your own cloud integration here.
Step 2 – Create the stack inside Spacelift
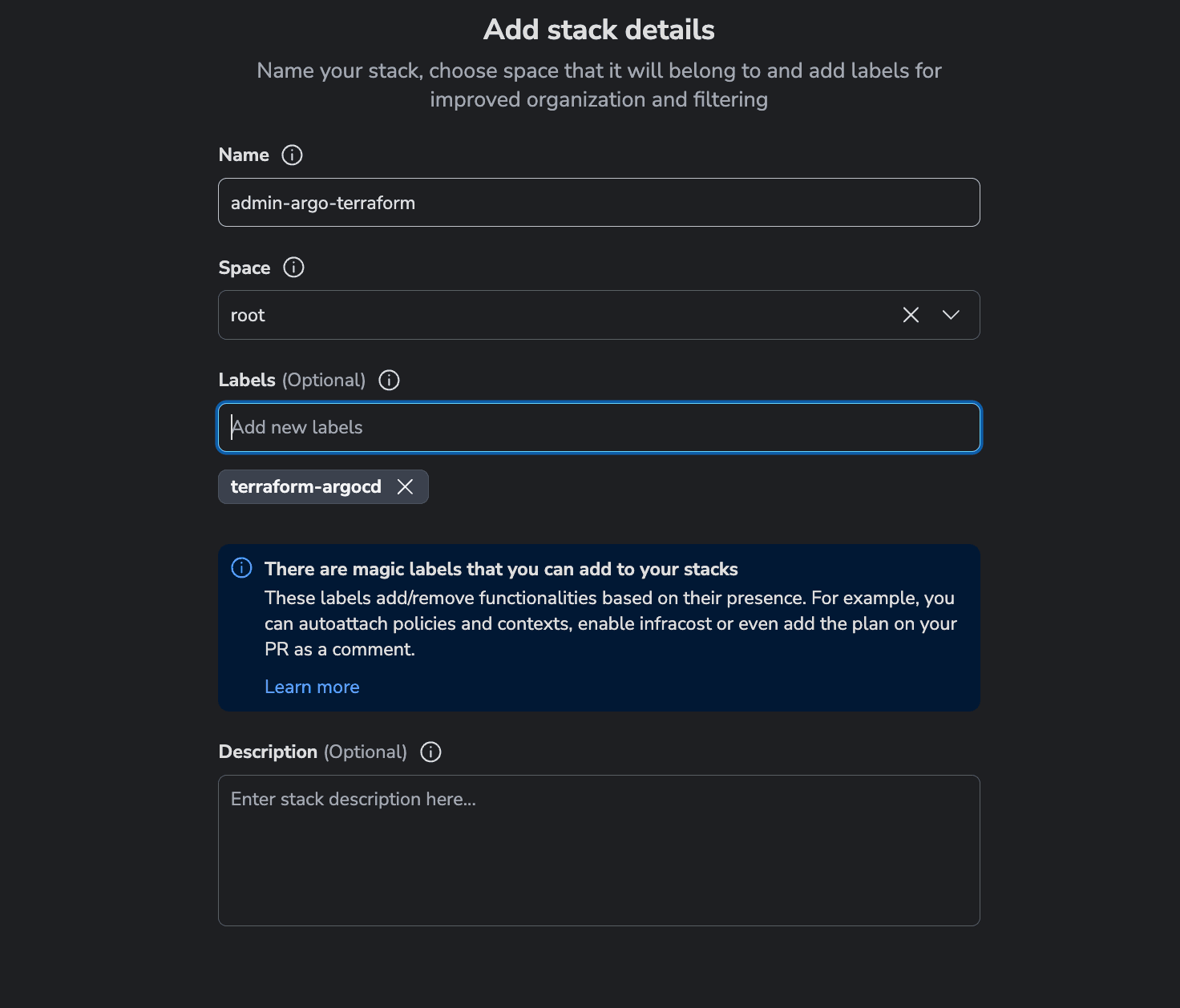
Let’s create this stack inside Spacelift. First, go to Stacks and select Create Stack:
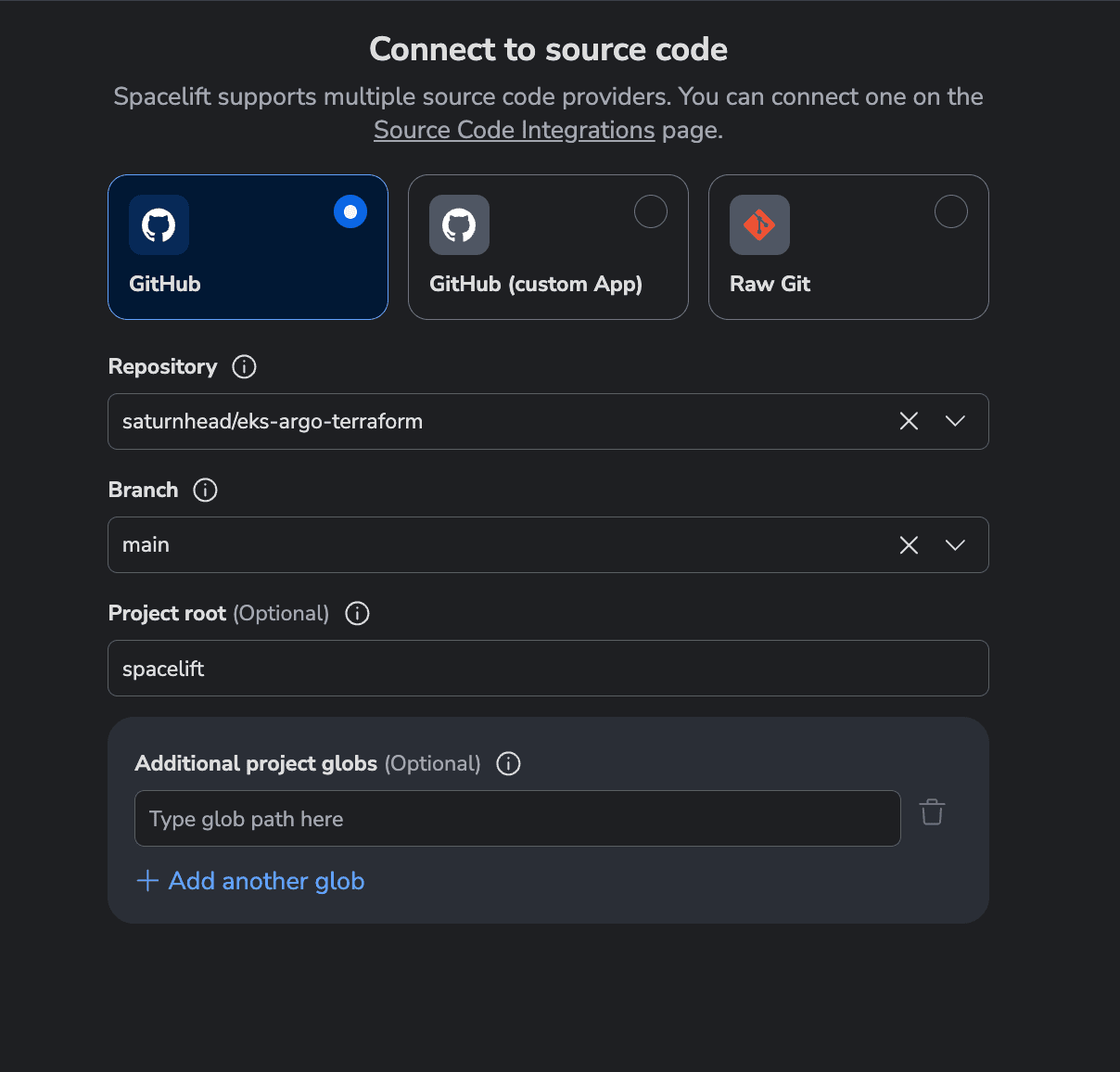
Then, select the repository and the path to the Spacelift configuration:
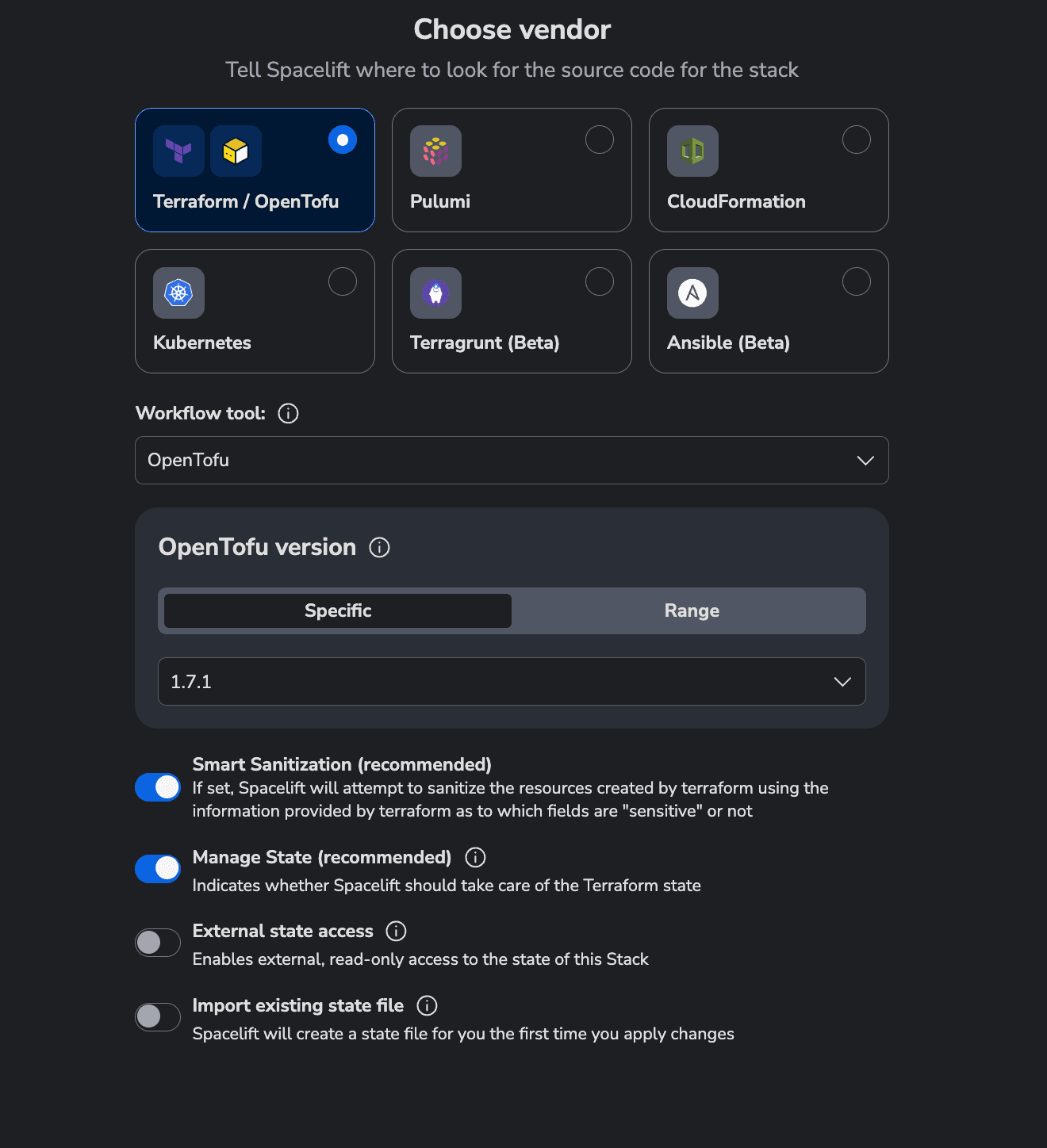
Next, select the tool you want to use to provision the resources. We will use OpenTofu, but you can use Terraform instead:
Next, in the Define Behavior tab check the Administrative option. This will let you provision Spacelift resources inside your account:
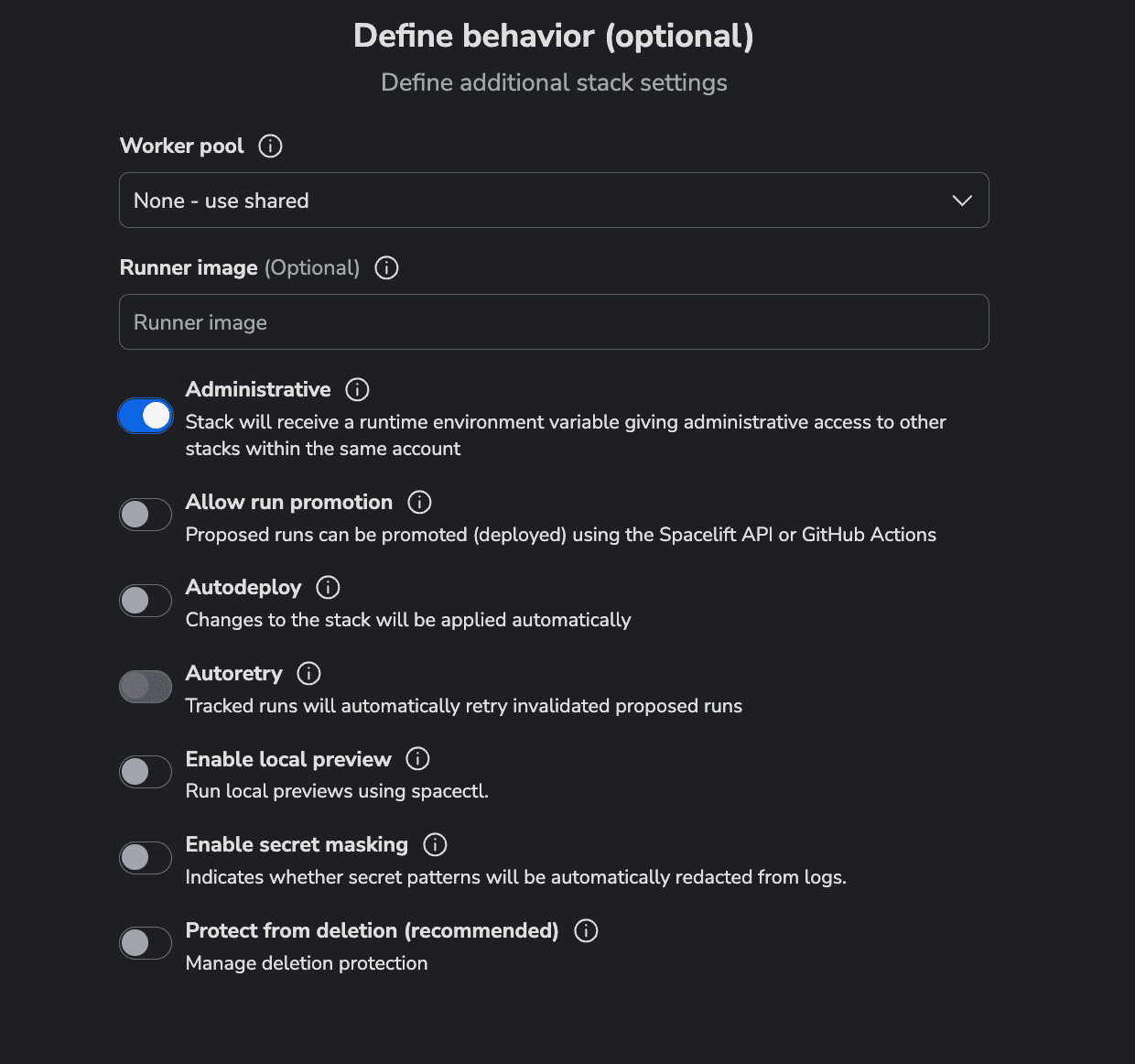
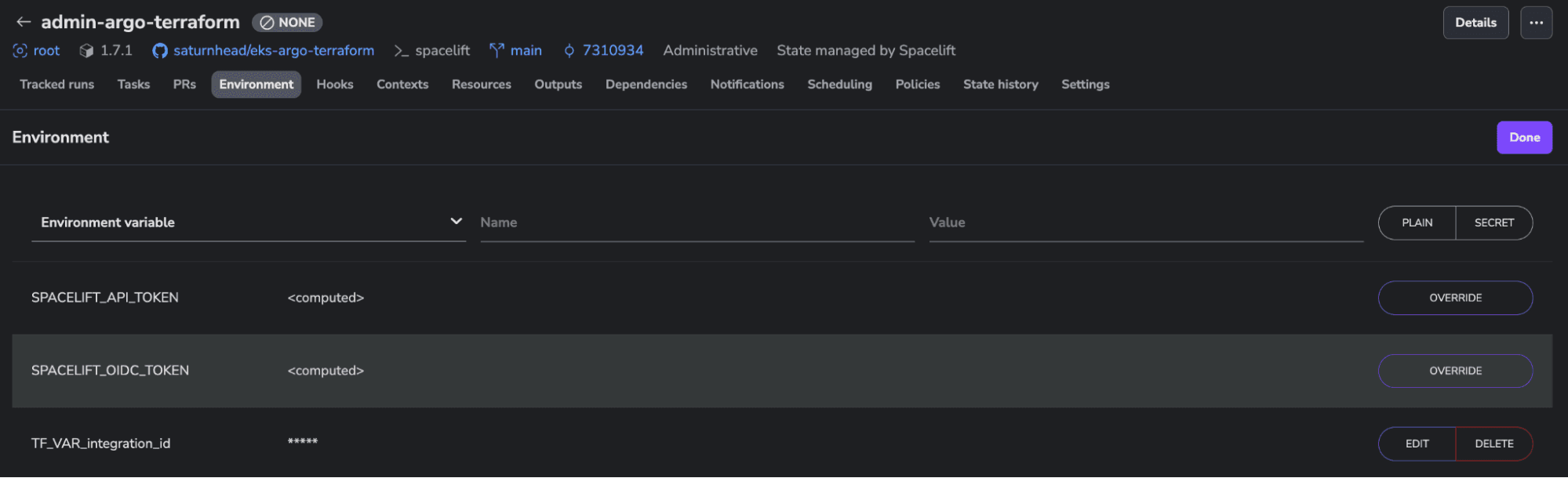
Skip to Summary and finish the stack creation wizard. Before running the code, we need to add the environment variable for the cloud integration ID that will be passed to both configurations (Terraform and K8s). This can be done from the Environment tab. Ensure the variable name is prefixed with “TF_VAR”. The integration_id is the id of the integration that you’ve previously built by following the documentation.
Step 3 – Create the Terraform and K8s stacks using the admin stack
Now, we are ready to run the code. Return to the Tracked runs tab and trigger a run.
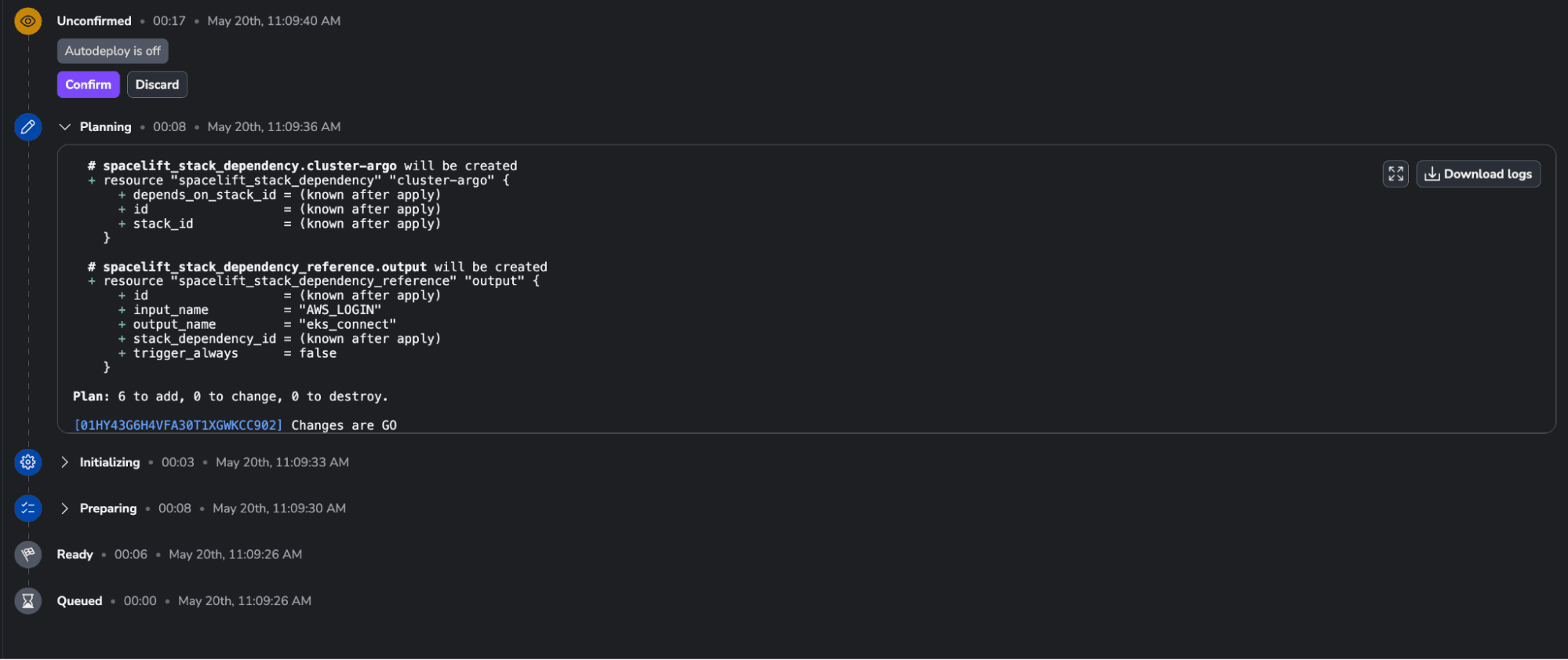
Confirm the run and wait for the resources to be created. The apply should take less than ten seconds:
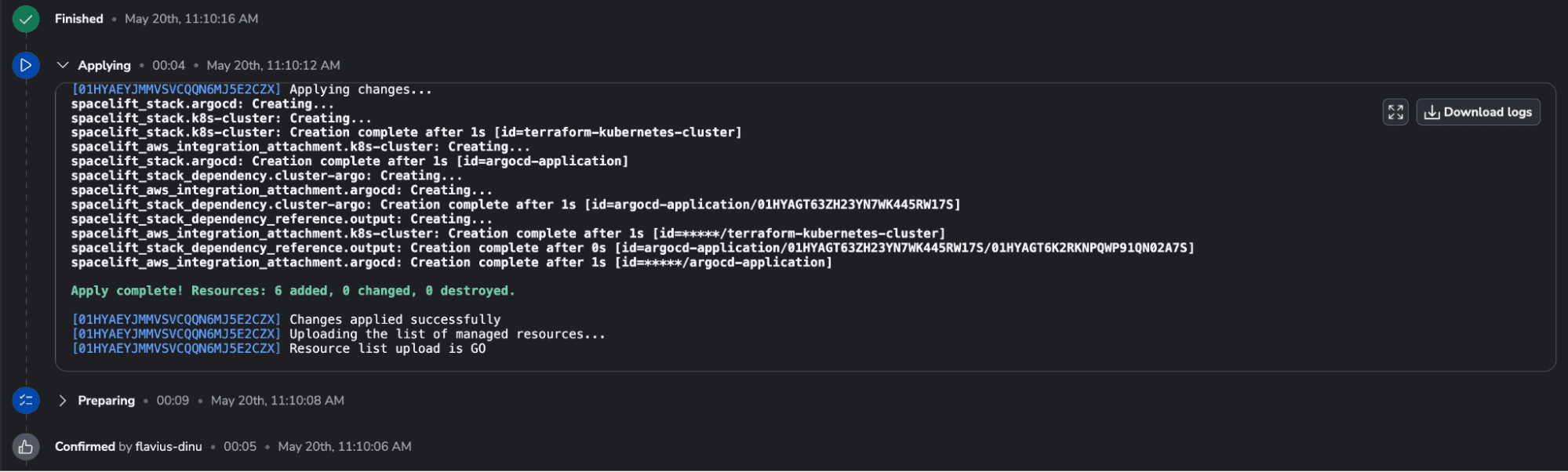
Next, if you go to your stacks, you should see two new stacks created:
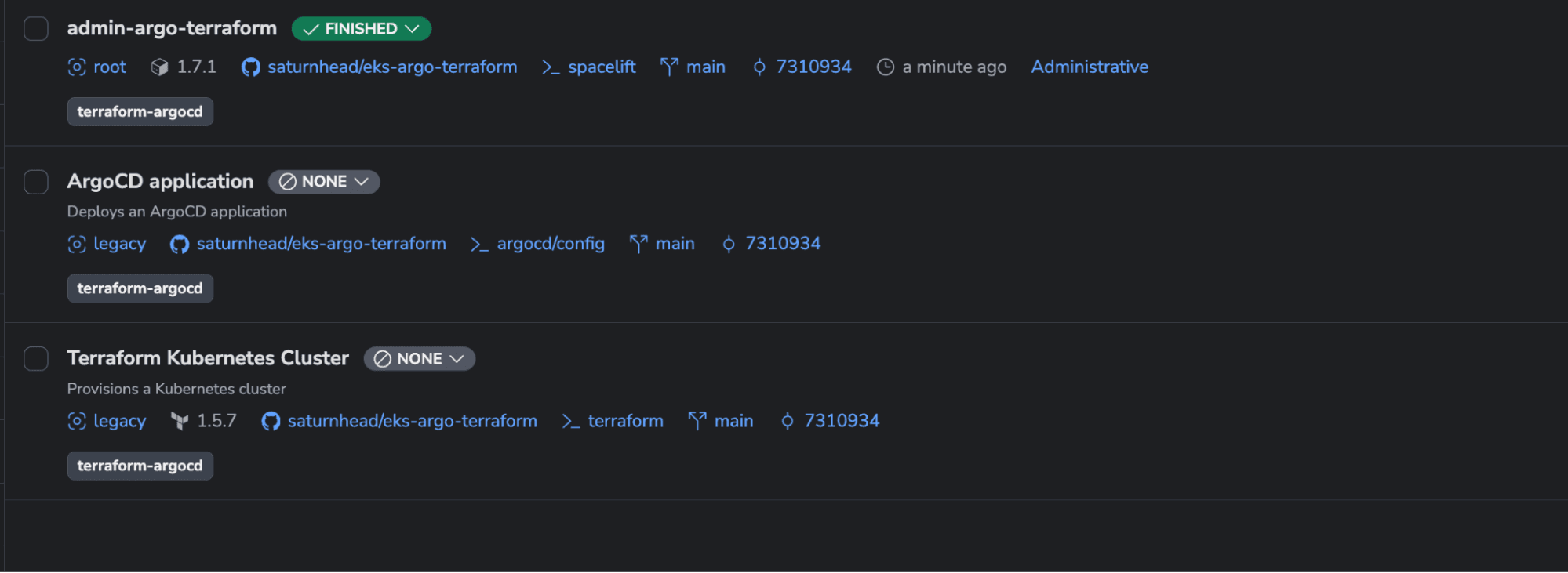
Step 4 – Run the Terraform Kubernetes cluster stack and wait for its dependencies to be triggered
Now, you can either trigger a run directly on the Terraform Kubernetes cluster stack, or change the Terraform code. For simplicity, let’s just trigger a run as we did before:
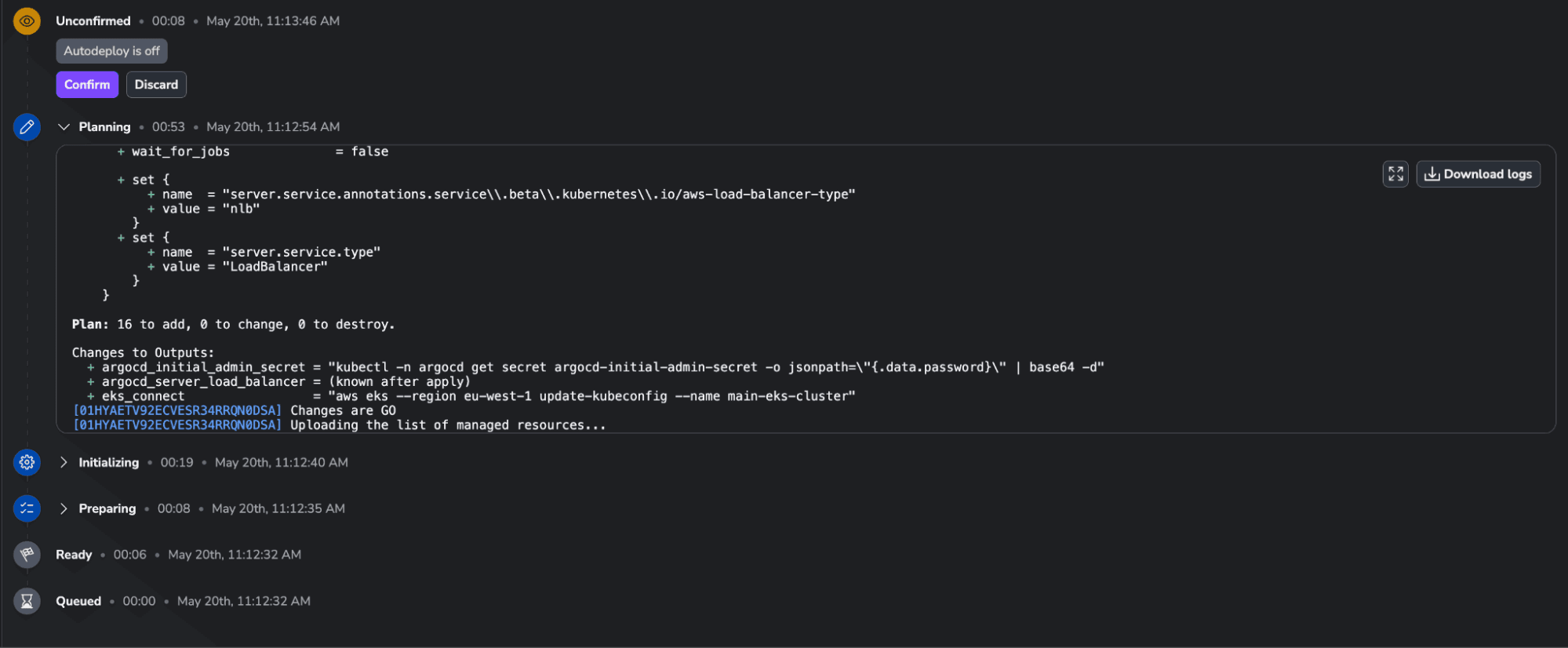
We can see all the resources that will be created in our infrastructure. Let’s confirm the run and let’s check the K8s stack until the apply finishes and see what is happening with it:
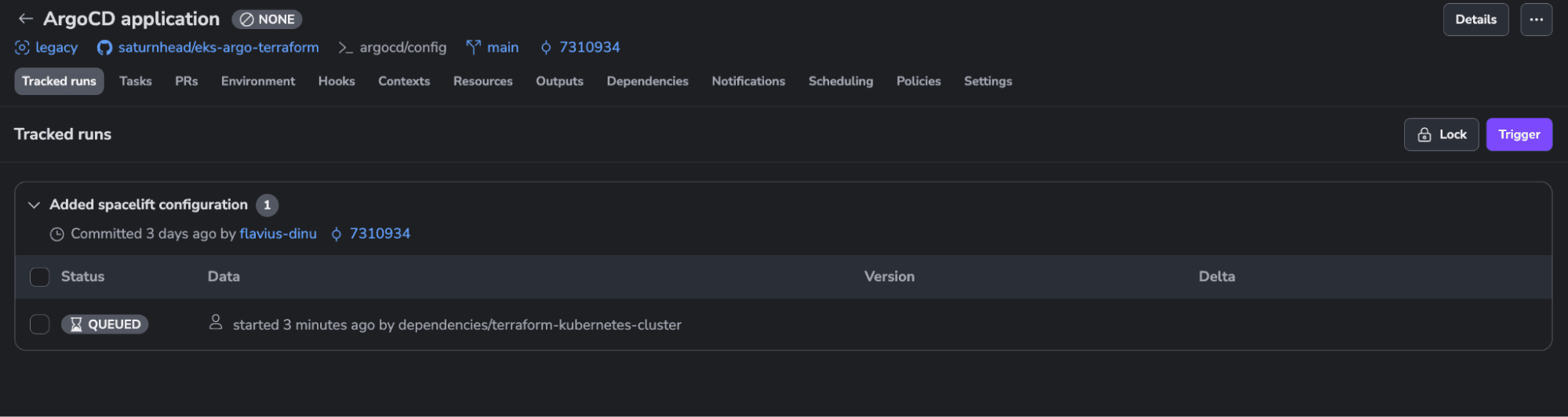
As you can see, this one has a run queued and is waiting for the Terraform stack to finish before applying.
The Terraform stack finished running, and the run on the K8s one was triggered:
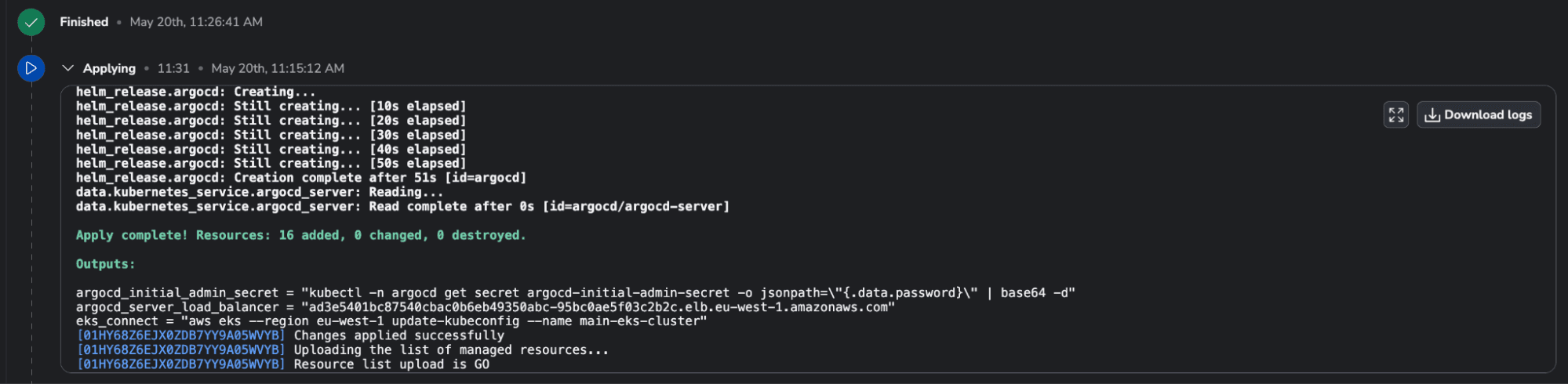
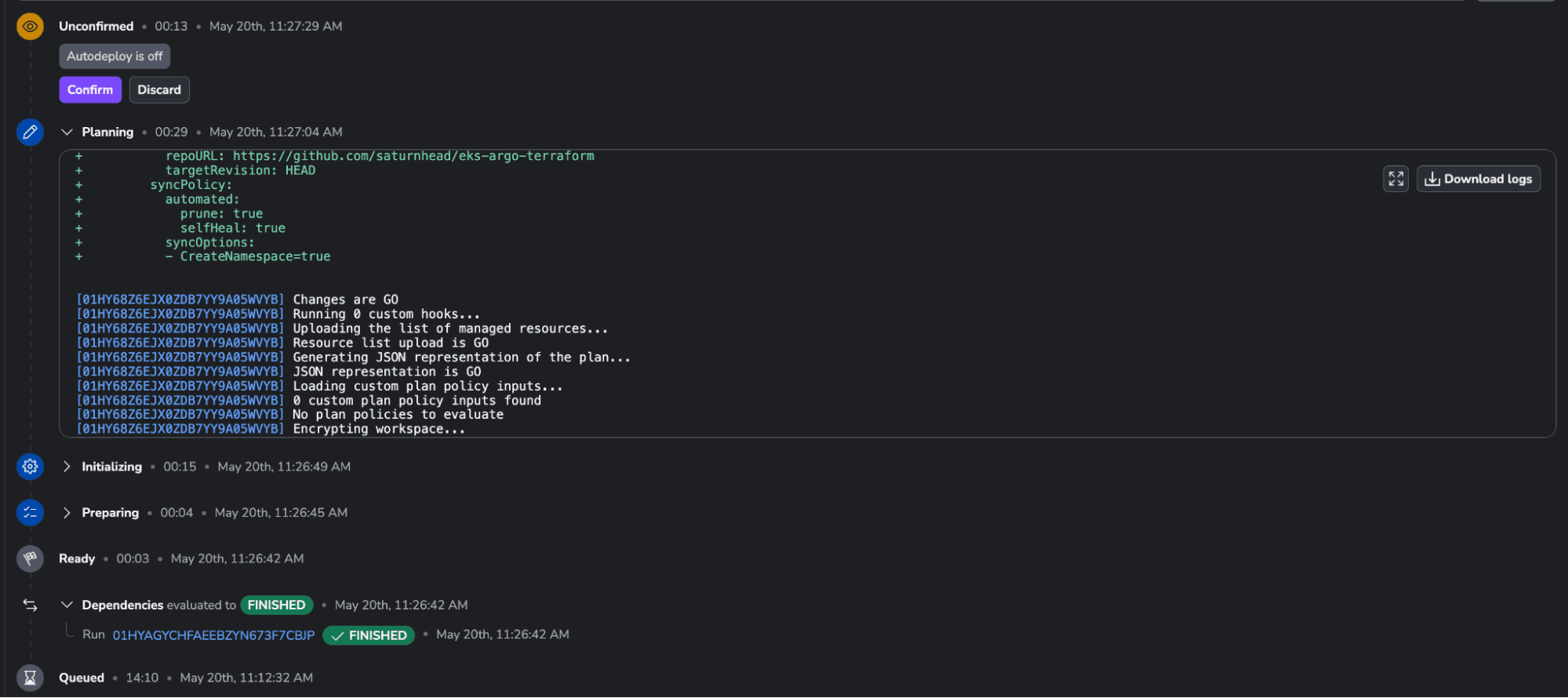
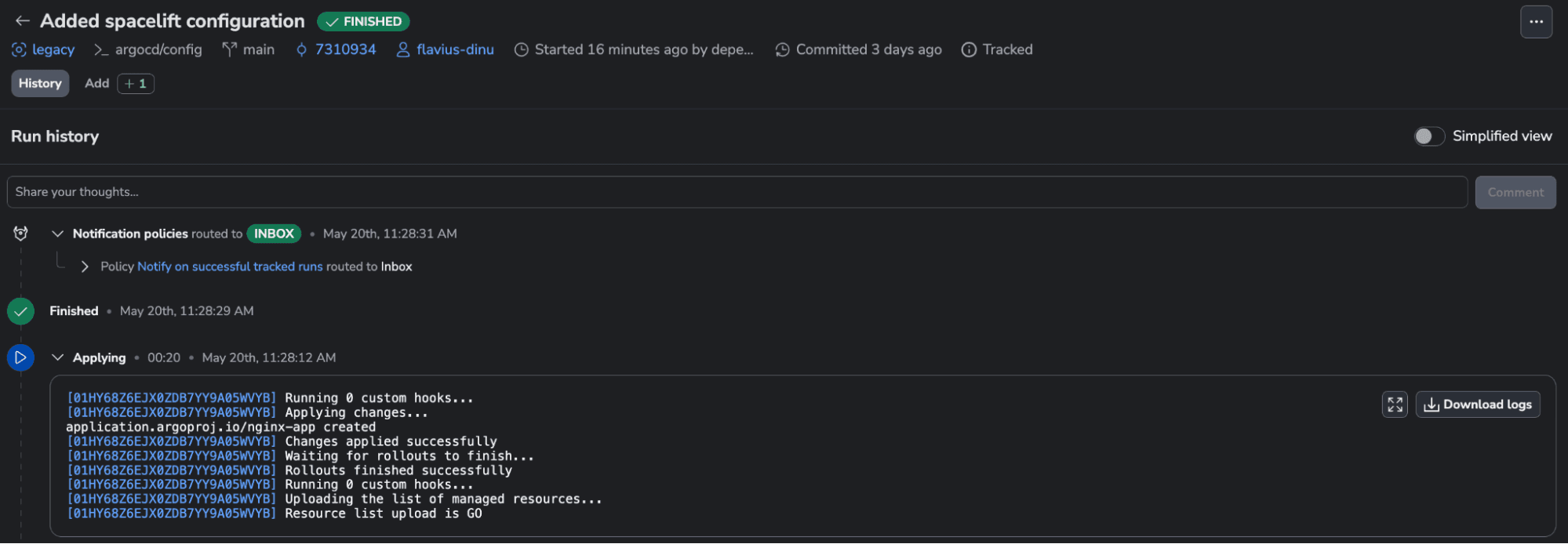
A few seconds after confirming the run, the resource is created:
To see the outputs from the Terraform stack, we can navigate back to the Terraform stack and select the Outputs tab:
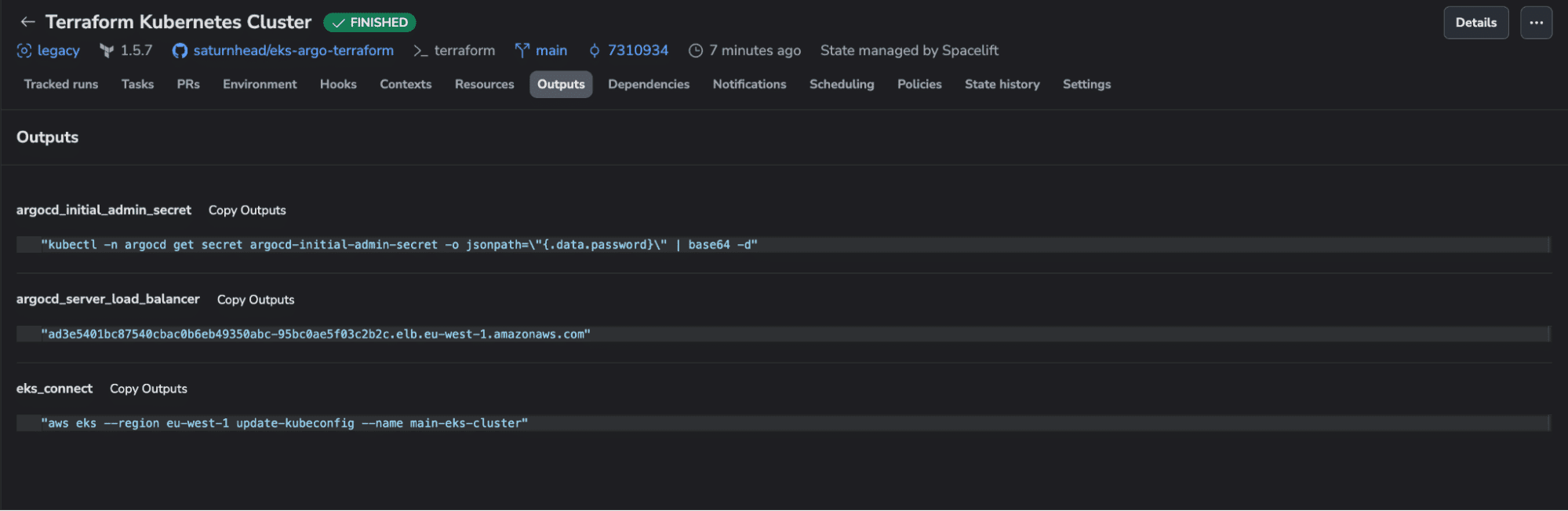
We can log in to the Argo instance by repeating the process we’ve done before, logging in to the K8s cluster, getting the initial admin secret, and navigating to the argocd server load balancer:
Key points
In this post, we’ve covered how to use Terraform with ArgoCD and shown how the deployment can be configured.
Deploying from a local environment will not work if you are collaborating with multiple engineers, and using GitHub Actions can prove complicated — especially when configuring the pipeline itself. Using Spacelift, you benefit from out-of-the-box workflows for your favorite infrastructure tools, and you can easily build dependable workflows.
If you want to learn more about Spacelift, create a free account today, or book a demo with one of our engineers.
Manage your infrastructure lifecycle with Spacelift
Spacelift is the infrastructure orchestration platform built for the AI-accelerated software era. It helps you automate, govern, and continuously deliver your infrastructure across Terraform, OpenTofu, Kubernetes, and more.
Frequently asked questions
Can ArgoCD work with Terraform?
ArgoCD does not natively support Terraform, as it is built for GitOps-based Kubernetes deployments using manifests (YAML, Helm, or Kustomize). However, you can integrate Terraform by running it as a pre-sync or post-sync hook in an ArgoCD Application. This lets you manage infrastructure changes alongside application deployments. Alternatively, use tools like ArgoCD-Terraform or wrap Terraform in Kubernetes Custom Resources to fit GitOps workflows.
What are the disadvantages of ArgoCD?
ArgoCD has several limitations that can affect complex or large-scale environments:
- Limited support for complex dependency management between applications compared to tools like Helmfile or Terraform
- RBAC and multi-tenancy features are functional but can be complex to configure securely at scale
- Lacks built-in secrets management, often requiring integration with tools like HashiCorp Vault or SOPS
- Resource drift outside Git isn’t automatically reconciled unless auto-sync is enabled, which can cause unexpected state changes
- UI can become slow or cluttered with many applications or deeply nested directories
Can Argo CD replace Terraform?
Argo CD cannot replace Terraform because they serve distinct purposes. Terraform provisions infrastructure (like VMs, networks, databases) using code, while Argo CD continuously deploys applications by syncing Kubernetes manifests from Git. Argo CD assumes infrastructure already exists, whereas Terraform creates and manages it across providers like AWS or GCP.
What is the difference between ArgoCD and Terraform?
ArgoCD is a GitOps continuous delivery tool that automatically syncs Kubernetes manifests from a Git repository to a cluster, while Terraform is an infrastructure-as-code tool that provisions cloud resources like VMs, networks, and databases across providers.
How does ArgoCD handle Terraform state?
ArgoCD does not natively handle Terraform state. It is a GitOps controller built for Kubernetes manifests, so managing Terraform state files, locking, or backends falls outside its scope. To reconcile Terraform through ArgoCD, teams typically use an operator like Crossplane or the Argo CD Terraform controller, which stores state in a remote backend such as S3 or Terraform Cloud.
