
Developed by Red Hat and written in Python, Ansible is an open-source, battle-tested automation tool that has become the de facto standard for configuration management of IT resources. Configuration management ensures that systems and infrastructure are configured consistently and according to best practices. IT professionals leverage Ansible to simplify management and proper configuration of such systems at scale due to its simplicity and powerful automation capabilities. This blog explores Ansible’s natural fit for configuration management, along with its basic concept and use cases.
What we will cover:
What is Ansible?
Ansible is a configuration management tool that automates the configuration and management of systems, applications, servers, storage, and networking. With Ansible, manual tasks become repeatable and less prone to error, making it a popular choice for managing large-scale and complex environments.
Ansible is targeted primarily at IT operators, administrators, and decision-makers, helping them achieve operational excellence across their entire infrastructure ecosystem. Its automation opportunities are endless across hybrid clouds, on-prem infrastructure, and IoT, and it’s an engine that can significantly improve the efficiency and consistency of your IT environments.
Why use Ansible for configuration management?
Ansible simplifies configuration management with its user-friendly YAML language, making it accessible for both developers and system administrators. Its agentless architecture reduces operational overhead by eliminating the need for extra software on managed nodes.
Moreover, Ansible ensures consistency through idempotent modules and offers flexibility with its modular design, supporting a wide range of operating systems, cloud providers, and network devices.
Let’s look at these benefits in more detail.
1. Simplicity and ease of use
Ansible uses a simple, declarative language (YAML) to describe automation jobs, making it accessible to developers and system administrators. The simplicity of using YAML to define Ansible playbooks that orchestrate tasks makes it easy for anyone to get up to speed quickly.
2. Reduced operational overhead with agentless operations
Another benefit of Ansible is that it doesn’t require any agent to be installed on the target nodes. Ansible is executed from a control node — for example, a user running a playbook from their local machine — and targets managed nodes, pushing at them a series of commands to execute to achieve the desired system state. Because no additional software needs to be maintained at the managed nodes, operational overhead is simplified for operators.

3. Idempotency offers consistency
Ansible’s modules are designed to be idempotent when possible, so the state of each task in a playbook is considered and executed only if necessary. This improves the reliability and consistency of configurations by ensuring that the result is the same, regardless of how many times the operation is repeated.
4. Extensibility offers flexibility
Ansible offers a modular architecture, allowing users to extend its capabilities through customizing modules, writing plugins, and composing roles. This flexibility ensures that Ansible can adapt to various use cases. Ansible supports multiple operating systems, cloud providers, and network devices, enabling integration and automation capabilities in any system. Lastly, with the Ansible Galaxy Community, users can access pre-built roles and share best practices and templates, accelerating the development process.
How does Ansible differ from other configuration management tools?
Ansible differs from other configuration management tools primarily through its agentless architecture, which eliminates the need for special software on target nodes, simplifying deployment and maintenance. However, it stands out from other tools and traditional configuration systems in several other ways:
1. Agentless architecture
Unlike tools like Puppet, Chef, or SaltStack, Ansible does not require software agents installed on the managed nodes. It uses SSH (for Linux/Unix) or WinRM (for Windows) to communicate with the target systems, making it more secure and easier to set up.
In addition to the agentless architecture, Ansible follows a push-based model, in which the control node pushes the desired state and configurations to the managed nodes.
2. Simple and human-readable syntax
Ansible uses YAML for its playbooks and other manifests. These data formats are more human-readable than XML or JSON and easy to write and understand. Furthermore, no special coding skills in a specific programming language are required to get started. This simplicity makes Ansible more accessible, especially for those new to configuration management, or automation.
3. Efficient and fast
Ansible is lightweight and efficient, making it suitable for managing large-scale infrastructure. It’s also designed for multi-tier deployments and models the whole IT landscape of your infrastructure and all the interdependencies of various subsystems.
4. Extensive module library
Ansible has a vast library of built-in modules covering a wide range of tasks, from software deployment and configuration management to cloud provisioning and network automation.
Ansible basic concepts & architecture
In this section, let’s look at all the Ansible pieces and how they work together.
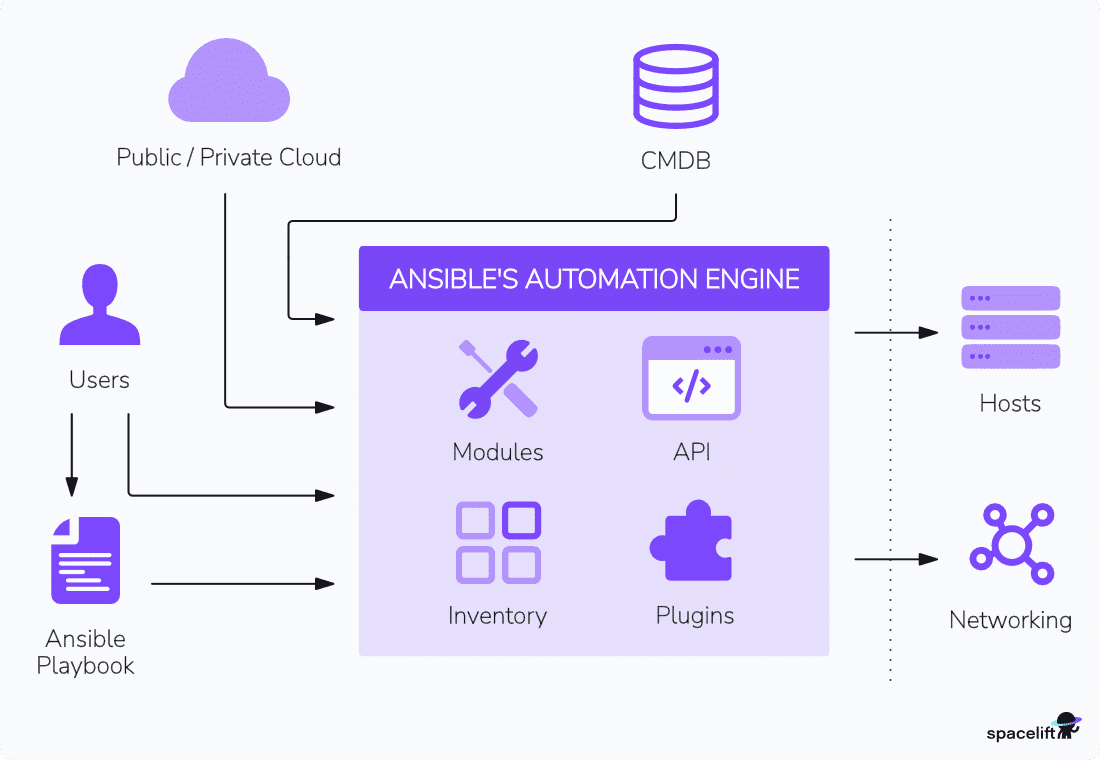
Inventory
In Ansible, an inventory is a file (or a collection of files) that lists the hosts or nodes that Ansible will manage and configure. It defines the target systems and allows you to organize them into groups or collections based on various criteria, such as functionality, environment, or location.
The inventory file is typically in INI-like format. It contains the target systems’ IP addresses, hostnames, or other identifiers, along with optional variables or parameters specific to each host or group.
Here’s an example of a simple Ansible inventory file:
[web]
web1.example.com
web2.example.com
[db]
db1.example.com
db2.example.com
[dev]
dev1.example.com
[prod]
web[1:2]
db[1:2]In this example:
[web]and[db]are group names; the hosts listed under them belong to those respective groups.web1.example.com,web2.example.com,db1.example.com, anddb2.example.comare individual host entries.[dev]and[prod]are environment-based groups.web[1:2]anddb[1:2]are patterns that expand toweb1.example.comandweb2.example.com, anddb1.example.comanddb2.example.com, respectively.
Ansible uses this inventory file to determine which hosts or groups to target for various tasks and playbooks. Within the inventory file, you can also define variables at the host or group level, allowing you to customize configurations for different systems or environments.
In addition to static inventory files, Ansible supports dynamic inventories, which can pull host information from external sources like cloud providers, databases, or scripts. Dynamic inventories make it easier to manage large and dynamic infrastructures. To learn more about Ansible Inventory, check out the Working with Ansible Inventory—Basics and Use Cases guide.
Playbooks
An Ansible playbook is a file that defines the tasks and configurations that Ansible should apply to the target systems specified in the inventory. Playbooks are written in YAML format and are the primary way to express the desired state and automation workflows in Ansible.
A playbook consists of one or more plays. Each play maps a group of hosts from the inventory to a set of roles or tasks to be executed on those hosts. A play is essentially a mapping between a group of hosts and the tasks that should be applied to those hosts.
Here’s a basic structure of an Ansible playbook:
--- # This is a playbook
- hosts: webservers # The group of hosts from the inventory
vars:
# Define variables here
tasks:
- name: Install Apache # A task with a name
yum:
name: httpd
state: present
- name: Start Apache service
service:
name: httpd
state: startedIn this example:
hosts: webserversspecifies that the tasks in this play should be executed on the hosts in thewebserversgroup from the inventory.vars:allows you to define variables that can be used in the tasks.tasks:is a list of tasks to be executed on the target hosts. Each task typically calls an Ansible module (e.g.,yum,service) with the desired parameters.
Ansible runs the plays and tasks in a playbook sequentially, applying the specified configurations and ensuring the target systems reach the desired state. Playbooks are idempotent, meaning running the same playbook multiple times will result in the same state without making unintended changes.
To learn more about Ansible Playbooks, check out the Ansible Playbooks: Complete Guide with Examples.
Modules
Ansible modules define the actions or resources to manage and configure on the target systems. Modules are reusable units of code that perform specific tasks, such as installing a package, managing files and directories, managing services, or interacting with APIs and cloud resources.
Ansible ships with many built-in modules that cover a wide range of tasks and use cases. These modules are written in Python and can be used directly in Ansible playbooks or roles. Some examples of built-in Ansible modules include:
– yum: Manages packages on RedHat-based Linux distributions
– apt: Manages packages on Debian-based Linux distributions
– service: Manages services (start, stop, restart, etc.)
– copy: Copies files from the control node to the target hosts (Read more: How to use Ansible copy module.)
– template: Renders Jinja2 templates to the target hosts
– file: Sets attributes of files, symlinks, and directories
– git: Deploys software from Git repositories
– docker_container: Manages Docker containers
– aws_ec2: Creates, terminates, or manages EC2 instances on AWS
– azure_rm_virtualmachine: Manages virtual machines in Azure
In addition to the built-in modules, Ansible also supports custom modules that users can write to extend Ansible’s functionality or interact with proprietary systems or APIs. Custom modules can be written in Python or other programming languages Ansible supports.
Modules are typically used within tasks in Ansible playbooks. Each task calls a specific module and passes the required parameters to achieve the desired state or perform the intended action on the target systems. For example:
- name: Install Apache
yum:
name: httpd
state: present
- name: Start Apache service
service:
name: httpd
state: startedIn this example, the yum module installs the Apache package, and the service module starts the Apache service.
Ansible’s modular architecture makes it highly extensible and adaptable to different environments and use cases for configuration management. Learn more about the Ansible Modules – How to Use Them Efficiently (Examples).
Variables
Ansible variables are used to store and pass values that can be used throughout Ansible playbooks, roles, and templates. Variables allow you to dynamically customize and configure systems based on specific values, environments, or conditions.
There are several ways to define and use variables in Ansible:
- Inventory variables: Variables can be defined in the Ansible inventory file at the group or host level. These variables are specific to the groups or hosts they are associated with.
- Playbook variables: Variables can be defined directly in Ansible playbooks, within the `vars` section or using the `vars_files` directive to load variables from external files.
- Role variables: Variables can be defined within Ansible roles, typically in the `defaults/main.yml` file (for default values) or `vars/main.yml` file (for role-specific variables).
- Host facts: Ansible automatically gathers system information (known as facts) from the target hosts, which can be accessed and used as variables.
- Environment variables: Variables can be defined as environment variables on the Ansible control node and accessed in playbooks and roles.
- Command line variables: Variables can be passed to Ansible playbooks from the command line using the
--extra-varsor-eoption.
Variables in Ansible use the Jinja2 templating syntax and can be accessed and used within playbooks, tasks, templates, and other Ansible constructs. For example, you can use variables to configure package names, file paths, service names, or any other configuration values that may vary across different systems or environments.
Here’s an example of using variables in an Ansible playbook:
- hosts: webservers
vars:
app_version: 1.2.3
http_port: 8080
tasks:
- name: Install application
package:
name: myapp-{{ app_version }}
state: present
- name: Configure application
template:
src: app.conf.j2
dest: /etc/myapp/app.conf
vars:
listen_port: "{{ http_port }}"In this example, the app_version and http_port variables are defined in the playbook’s vars section. The `app_version` variable specifies the package name for the package module task, and the http_port variable is passed to the template module task using the Jinja2 templating syntax.
Check out the How to Use Different Types of Ansible Variables (Examples) to learn more.
Roles
Ansible roles organize and package Ansible tasks, variables, files, and other configurations into reusable units. They provide a structured and modular approach to managing complex configurations and promoting code reuse across different Ansible playbooks and projects.
An Ansible role typically consists of the following directories and files:
role_name/
├── tasks/
│ └── main.yml # Tasks to be executed by this role
├── handlers/
│ └── main.yml # Handlers for tasks that need to trigger service restarts
├── defaults/
│ └── main.yml # Default variables for the role
├── vars/
│ └── main.yml # Other variables for the role
├── files/
│ └── ... # Files to be copied to the target hosts
├── templates/
│ └── ... # Jinja2 templates to be rendered on the target hosts
├── meta/
│ └── main.yml # Role metadata and dependencies
└── README.md # Documentation for the roleHere’s a brief explanation of each directory:
tasks/: This directory contains the main list of tasks that the role will execute. The `main.yml` file in this directory defines the tasks to be run.handlers/: This directory contains handlers, which are tasks that are triggered by other tasks to perform actions like restarting services.defaults/: This directory contains the role’s default variable values, which can be overridden by other variables or in the playbook.vars/: This directory can contain additional variables specific to the role.files/: This directory contains files that can be copied to the target hosts by the role.templates/: This directory contains Jinja2 templates with variable values that can be rendered on the target hosts.meta/: This directory contains metadata about the role, such as dependencies on other roles or information about the role’s author.
Roles can be included and used in Ansible playbooks using the roles keyword:
- hosts: webservers
roles:
- apache
- php
- myappIn this example, the apache, php, and myapp roles will be executed on the webservers group of hosts.
Check out the Ansible Roles: Basics, Creating & Using to learn more.
Configuration management use cases with Ansible
Configuration management with Ansible involves automating the setup, maintenance, and updating of system configurations across a large number of servers. The main use cases for Ansible in configuration management include managing and configuring remote servers, user management and access control, and ensuring servers comply with security policies.
1. Managing and configuring remote servers
Managing and maintaining consistent configurations across multiple remote servers and environments can be daunting. Manual configuration processes are time-consuming and prone to human error, leading to potential inconsistencies and increased security risks.
The example below leverages an Ansible playbook to install and configure the Nginx web server to a series of hosts consistently:
deploy_web_server.yml
- name: Install and Configure Nginx
hosts: all
become: yes
pre_tasks:
- name: Set SSH user for Ubuntu systems
set_fact:
ansible_user: ubuntu
when: ansible_os_family == "Debian"
tasks:
- name: Install Nginx
ansible.builtin.apt:
update_cache: yes
name: nginx
state: present
- name: Create index.html
ansible.builtin.copy:
dest: /var/www/html/index.html
content: |
<!DOCTYPE html>
<html>
<head><title>Server Details</title></head>
<body>
<h1>Served from {{ ansible_hostname }}</h1>
</body>
</html>
mode: '0644'
- name: Ensure Nginx is running and enabled
ansible.builtin.service:
name: nginx
state: started
enabled: yes2. User management and access control
Ansible can efficiently manage user accounts and access permissions across a network of computers or virtual servers. Below is an example Ansible playbook for managing user accounts, setting passwords, setting file and directory permissions, and managing user groups. It can also ensure that only authorized users have sudo access and that former employees’ accounts are deactivated across all servers.
user_management_acl.yml
- name: Manage users and access control
hosts: all
become: true
gather_facts: no
vars:
username: demo_user
encrypted_pass: "$6$rounds=656000$JND8Zv2dH/FN3bB$6r0T.zLxo1Bw5TukIHUIk8csaWXF1U0QHvB/gEp8qFk/zMS76.6NFnD/bkAB7xsg9bN4cmuOXRew.4OkfxaZO0"
tasks:
- name: Create a new user with some permissions
user:
name: "{{ username }}"
password: "{{ encrypted_pass }}"
state: present
shell: /bin/bash
create_home: yes
home: /home/{{ username }}
groups: sudo
append: yes
- name: create test directory
file:
path: /home/test
state: directory
- name: Ensure acl package is installed
apt:
name: acl
state: present
- name: grant user read access to test directory
acl:
path: /home/test
entity: "{{ username }}"
etype: user
permissions: r
state: present
- name: Create a new group
group:
name: "devops"
state: present
- name: Set ownership of a directory
file:
path: /home/test
owner: "{{ username }}"
group: devops
state: directory
- name: add user to devops group
user:
name: "{{ username }}"
groups: devops
append: yes3. Ensuring servers comply with security policies
One of the most common use cases for Ansible is to ensure a fleet of servers complies with security policies and is up to date. Let’s look at an example of a playbook that upgrades all system packages of Ubuntu servers and reboots them if necessary to apply the latest patches and security updates.
- hosts: aws_ec2
become: true
become_user: root
tasks:
- name: Update apt repo and cache for Ubuntu servers
apt: update_cache=yes force_apt_get=yes cache_valid_time=3600
- name: Upgrade all packages on servers
apt: upgrade=dist force_apt_get=yes
- name: Check if a reboot is needed on all servers
register: reboot_required_file
stat: path=/var/run/reboot-required
- name: Reboot the box if kernel updated
reboot:
msg: "Reboot initiated by Ansible for kernel updates"
connect_timeout: 5
reboot_timeout: 300
pre_reboot_delay: 0
post_reboot_delay: 30
test_command: uptime
when: reboot_required_file.stat.existsIn this example, we are targeting all our EC2 servers on AWS. We update the cache of available packages, run the upgrades on all packages, and reboot the servers if an update is needed. That’s a common, repetitive task that we can automate with Ansible to ensure our systems are up to date with the latest patches and security updates.
Best practices for using Ansible for configuration management
This section lists best practices that can be applied when performing configuration management tasks with Ansible.
| Use a consistent tagging strategy | Tagging is a powerful concept in Ansible because it allows us to group and manage tasks more granularly. Tags also allow us to add fine-grained controls to task execution. |
| Use a consistent naming strategy | Before setting up your Ansible projects, consider applying a consistent naming convention for your tasks (always name them), plays, variables, roles, and modules. |
| Store your projects in a Version Control System (VCS) | Keep your Ansible files in a code repository and commit any new changes regularly. |
| Don’t store sensitive values in plain text | Encrypt variables and files and protect sensitive information with Ansible Vault for secrets and sensitive values. |
| Dynamic inventory | Maintaining static inventories might quickly become complex when working with cloud providers and ephemeral or fast-changing environments. Instead, set up a mechanism to synchronize the inventory dynamically with your cloud providers. |
| Use top-level playbooks to orchestrate other lower-level playbooks | You can logically group tasks, plays, and roles into low-level playbooks, import them from other top-level playbooks, and set up an orchestration layer according to your needs. Have a look at this example for inspiration. |
| Modularize your playbooks | Use roles to encapsulate and modularize your playbooks. This makes them reusable across different projects and environments. |
| Centralize configuration with variables | Use variables to manage configuration settings across different environments (e.g., development, staging, production). Define variables in group_vars and host_vars directories. |
| Ensure repeatability | Write idempotent playbooks, meaning running them multiple times does not change the system’s state after the first application. This ensures consistent and predictable results. |
| Document your playbooks | Write clear and concise comments within your playbooks and roles to explain the purpose and function of each task. This aids in understanding and maintaining the code. |
| Automate testing and deployment with CI/CD | Integrate Ansible with CI/CD pipelines to automate configuration testing and deployment. Check out how Spacelift integrates with Ansible. |
If you want more tips on using Ansible according to best practices, check out my 44 Ansible Best Practices to Follow [Tips & Tricks] blog post.
Why use Spacelift to elevate your Ansible automation?
Spacelift’s vibrant ecosystem and excellent GitOps flow can greatly assist you in managing and orchestrating Ansible. By introducing Spacelift on top of Ansible, you can easily create custom workflows based on pull requests and apply any necessary compliance checks for your organization.
With Spacelift, you get:
- Better playbook automation – Manage the execution of Ansible playbooks from one central location.
- Inventory observability – View all Ansible-managed hosts and related playbooks, with clear visual indicators showing the success or failure of recent runs.
- Playbook run insights – Audit Ansible playbook run results with detailed insights to pinpoint problems and simplify troubleshooting.
- Policies – Control what kind of resources engineers can create, what parameters they can have, how many approvals you need for a run, what kind of task you execute, what happens when a pull request is open, and where to send your notifications
- Stack dependencies – Build multi-infrastructure automation workflows with dependencies, having the ability to build a workflow that, for example, generates your EC2 instances using Terraform and combines it with Ansible to configure them
- Self-service infrastructure via Blueprints – Enable your developers to do what matters – developing application code while not sacrificing control
- Creature comforts such as contexts (reusable containers for your environment variables, files, and hooks), and the ability to run arbitrary code
- Drift detection and optional remediation
If you want to learn more about using Spacelift with Ansible, check our documentation, read our Ansible guide, or book a demo with one of our engineers.
Would you like to see this in action – or just want a tl;dr? Check out this video I put together showing you Spacelift’s new Ansible functionality:

Key points
Ansible configuration management simplifies the process of automating software deployment, managing configurations, and ensuring consistency across multiple servers. In this blog post, we analyzed why Ansible is a great configuration management system for different purposes and tasks. We explored the main architecture components that make Ansible suitable for the job and discussed various practical examples for configuration management. Finally, we listed best practices to consider when structuring Ansible projects.
Manage Ansible better with Spacelift
Managing large-scale playbook execution is hard. Spacelift enables you to automate Ansible playbook execution with visibility and control over resources, and seamlessly link provisioning and configuration workflows.
