
In this blog post, we will examine different concepts and best practices for building an Ansible inventory. We will explore basic functionality, managing variables, and combining multiple inventory sources and options for working with dynamic inventories.
If you are new to Ansible or interested in other Ansible concepts, these Ansible tutorials on Spacelift’s blog might be useful.
What we will cover:
What is an Ansible inventory file?
An Ansible inventory is a collection of managed hosts we want to manage with Ansible for various automation and configuration management tasks. Typically, when starting with Ansible, we define a static list of hosts known as the inventory. These hosts can be grouped into different categories, and then we can leverage various patterns to run our playbooks selectively against a subset of hosts.
By default, the inventory is stored in /etc/ansible/hosts, but you can specify a different location with the -i flag or the ansible.cfg configuration file.
Ansible inventory basics
Let’s take a look at a simple Ansible inventory. The most common formats are either INI or YAML.
[webservers]
host01.mycompany.com
host02.mycompany.com
[databases]
host03.mycompany.com
host04.mycompany.comIn this example, we use the INI format, define four managed hosts, and group them into two host groups: webservers and databases. The group names can be specified between brackets, as shown above.
Inventory groups are one of the handiest ways to control Ansible execution. Hosts can also be part of multiple groups.
[webservers]
host01.mycompany.com
host02.mycompany.com
[databases]
host03.mycompany.com
host04.mycompany.com
[europe]
host01.mycompany.com
host03.mycompany.com
[asia]
host02.mycompany.com
host04.mycompany.comNote: By default, two groups can be referenced without defining them. The all group targets all our hosts in the inventory, and the ungrouped contains any host that isn’t part of any user-defined group.
We can also create nested groups of hosts if necessary.
[paris]
host01.mycompany.com
host02.mycompany.com
[amsterdam]
host03.mycompany.com
host04.mycompany.com
[europe:children]
paris
amsterdamTo list a range of hosts with similar patterns, you can leverage the range functionality instead of defining them one by one. For example, to define ten hosts (host01, host02, …. host10):
databases
hosts[01:10].mycompany.com
Another useful function is the option to define aliases for hosts in the inventory. For example, we can run Ansible against the host alias host01 if we define it in the inventory as:
host01 ansible_host=host01.mycompany.comA typical pattern for inventory setups is separating inventory files per environment. Here is an example of separate staging and production inventories:
staging_inventory
[webservers]
host01.staging.mycompany.com
host02.staging.mycompany.comproduction_inventory
[webservers]
host01.production.mycompany.com
host02.production.mycompany.comWhen defining groups of hosts in the inventory, we categorize them based on application, function, location, department, and other shared characteristics between hosts, allowing us to target them in groups. Consider which groups make sense for your use case and automation needs.
Ansible-inventory command overview
The ansible-inventory command is very useful for understanding your inventory at a glance. You’ve seen how to use it to list all your inventory in the JSON format before, but let’s walk through some other options as well.
For all of the examples, we will use the following inventory.ini file:
[dev_web]
10.0.2.2
[prod_web]
10.0.2.3
[dev_database]
db ansible_host=10.0.2.4
[prod_database]
10.0.2.4Display your inventory in JSON format:
ansible-inventory -i inventory.ini --list
{
"_meta": {
"hostvars": {
"db": {
"ansible_host": "10.0.2.4"
}
}
},
"all": {
"children": [
"ungrouped",
"dev_web",
"prod_web",
"dev_database",
"prod_database"
]
},
"dev_database": {
"hosts": [
"db"
]
},
"dev_web": {
"hosts": [
"10.0.2.2"
]
},
"prod_database": {
"hosts": [
"10.0.2.4"
]
},
"prod_web": {
"hosts": [
"10.0.2.3"
]
}
}Display your inventory in YAML format:
ansible-inventory -i inventory.ini --list --yaml
all:
children:
dev_database:
hosts:
db:
ansible_host: 10.0.2.4
dev_web:
hosts:
10.0.2.2: {}
prod_database:
hosts:
10.0.2.4: {}
prod_web:
hosts:
10.0.2.3: {}Show variables assigned to a host:
ansible-inventory -i inventory.ini --host db
{
"ansible_host": "10.0.2.4"
}Show an inventory graph:
ansible-inventory -i inventory.ini --graph
@all:
|--@ungrouped:
|--@dev_web:
| |--10.0.2.2
|--@prod_web:
| |--10.0.2.3
|--@dev_database:
| |--db
|--@prod_database:
| |--10.0.2.4Ansible inventory variables
An important aspect of Ansible’s project setup is variable assignment and management. One of the many ways to set variables in Ansible is to define them in the inventory. (Check this blog post for detailed information about Ansible variables.)
For example, let’s define one variable for a different application version for every host in our dummy inventory from before.
[webservers]
host01.mycompany.com app_version=1.0.1
host02.mycompany.com app_version=1.0.2
[databases]
host03.mycompany.com app_version=1.0.3
host04.mycompany.com app_version=1.0.4Ansible-specific connection variables such as ansible_user or ansible_host are examples of host variables defined in the inventory. Check the Connecting to hosts: behavioral inventory parameters section of the docs for more options.
Similarly, variables can also be set at the group level in the inventory and offer a convenient way to apply variables to hosts with common characteristics.
[webservers]
host01.mycompany.com
host02.mycompany.com
[databases]
host03.mycompany.com
host04.mycompany.com
[webservers:vars]
app_version=1.0.1
[databases:vars]
app_version=1.0.2Although setting variables in the inventory is possible, it’s usually not the preferred way. Instead, store separate host and group variable files to enable better organization and clarity for your Ansible projects. Note that host and group variable files must use the YAML syntax.
In the directory where we keep our inventory file, we can create two folders named group_vars and host_vars containing our variable files. For example, we could have a file group_vars/webservers that contains all the variables for web servers:
group_vars/webservers
http_post: 80
ansible_user: automation_userA possible use case for having separate variable files instead of storing them in the inventory is to keep sensitive values without persisting them in playbooks or source control systems.
As mentioned, there are multiple options to set variables in Ansible, so if you plan to use different layers for your vars look at these sections of the official documentation: Understanding variable precedence and How variables are merged.
Multiple Ansible inventory sources
You can combine different inventories and sources, such as directories, dynamic inventory scripts, or inventory plugins during runtime or in the configuration. This becomes especially useful when you want to target multiple environments or otherwise isolated setups.
For example, to target the development, testing, staging, and production hosts all at the same time:
ansible-playbook apply_updates.yml -i development -i testing -i staging -i productionWe can combine multiple inventory sources in a directory and then manage them as one. This approach is useful when controlling static and dynamic hosts.
inventory/
static-inventory-1
static-inventory-2
dynamic-inventory-1
dynamic-inventory-1Then, we can run playbooks against all hosts in these inventories like this:
ansible-playbook apply_updates.yml -i inventoryExample: How to use an Ansible inventory file
Now that you know the basics of the Ansible inventory, let’s walk through building an inventory file:
Step 1: Create an Ansible inventory file
When you install Ansible, it creates a global inventory file by default, typically in /etc/ansible/hosts. As a best practice, you should create inventories for every project you are building.
As with all configuration management and infrastructure-as-code tools, Ansible works best with version control. It is generally a good idea to push your configuration to your VCS provider, but you shouldn’t push your inventory because it may contain sensitive information.
To create an Ansible inventory file you can use your terminal, the OS UI, or even your IDE’s interface. The typical name for an Ansible inventory is inventory.ini.
To create the inventory from your terminal, simply run the following command from your project configuration directory:
touch inventory.iniThen, you can use an editor such as Nano, VIM, or your IDE and add details inside this file:
vim inventory.ini
10.0.2.2
10.0.2.3The hosts can be grouped or ungrouped inside your inventory file. As you can see above, there is nothing to group them, so they will be ungrouped.
You can use the ansible-inventory command to validate your inventory and get information about your hosts:
ansible-inventory -i inventory.ini --list
{
"_meta": {
"hostvars": {}
},
"all": {
"children": [
"ungrouped"
]
},
"ungrouped": {
"hosts": [
"10.0.2.2",
"10.0.2.3"
]
}
}By default, Ansible creates two groups for your inventory: the all group, which contains all the hosts from your inventory, and the ungrouped one, which contains all your ungrouped hosts. These are currently the same, but this will change as we repeat the command throughout this part.
If you are using git, now is a good time to create the .gitignore file to ignore the inventory.ini file and some other files as well. Again, keep in mind that these files should be ignored only if they contain secrets:
.gitignore
inventory.ini
*.log
*.retry
*.swpStep 2: Define hosts and groups
As mentioned above, you can define your hosts and group them logically. You can also set common variables for all the hosts you are using with ease, and you can even define the SSH username for a particular host. Among the many other things you can do in the inventory file is setting aliases for a particular host.
Let’s look at an example:
[web]
10.0.2.2
10.0.2.3
[database]
db ansible_host=10.0.2.4 ansible_user=ubuntu
[all:vars]
ansible_ssh_private_key_file=~/.ssh/id_rsaBy listing the inventory as we’ve done in the previous steps, we can get more details:
ansible-inventory -i inventory.ini --list
{
"_meta": {
"hostvars": {
"10.0.2.2": {
"ansible_ssh_private_key_file": "~/.ssh/id_rsa"
},
"10.0.2.3": {
"ansible_ssh_private_key_file": "~/.ssh/id_rsa"
},
"db": {
"ansible_host": "10.0.2.4",
"ansible_ssh_private_key_file": "~/.ssh/id_rsa",
"ansible_user": "ubuntu"
}
}
},
"all": {
"children": [
"ungrouped",
"web",
"database"
]
},
"database": {
"hosts": [
"db"
]
},
"web": {
"hosts": [
"10.0.2.2",
"10.0.2.3"
]
}
}We have set up the same SSH key for all of our hosts, but for our DB one, we have set an IP and the user it will use to connect via SSH. As you can see, the hosts are now grouped into DB and web.
Many use cases involve the same host appearing multiple times in the inventory file, and this makes considerable sense. You can group your hosts by purpose, environment, and other criteria that make sense for your organization. Let’s modify the example further to leverage this functionality:
[dev_web]
10.0.2.2
[prod_web]
10.0.2.3
[dev_database]
db ansible_host=10.0.2.4 ansible_user=ubuntu
[prod_database]
10.0.2.4
[web]
10.0.2.2
10.0.2.3
[all:vars]
ansible_ssh_private_key_file=~/.ssh/id_rsaAs you can see, we have now defined a dev_web and a prod_web group in which we split our webservers. Our web group contains both of them.
You can add multiple groups as children under a parent group, obtaining thus a more granular way to manage your inventory:
[dev_web]
10.0.2.2
[prod_web]
10.0.2.3
[dev_database]
db ansible_host=10.0.2.4 ansible_user=ubuntu
[prod_database]
10.0.2.4
[web:children]
dev_web
prod_web
[all:vars]
ansible_ssh_private_key_file=~/.ssh/id_rsaansible-inventory -i inventory.ini --list
{
"_meta": {
"hostvars": {
"10.0.2.2": {
"ansible_ssh_private_key_file": "~/.ssh/id_rsa"
},
"10.0.2.3": {
"ansible_ssh_private_key_file": "~/.ssh/id_rsa"
},
"10.0.2.4": {
"ansible_ssh_private_key_file": "~/.ssh/id_rsa"
},
"db": {
"ansible_host": "10.0.2.4",
"ansible_ssh_private_key_file": "~/.ssh/id_rsa",
"ansible_user": "ubuntu"
}
}
},
"all": {
"children": [
"ungrouped",
"dev_database",
"prod_database",
"web"
]
},
"dev_database": {
"hosts": [
"db"
]
},
"dev_web": {
"hosts": [
"10.0.2.2"
]
},
"prod_database": {
"hosts": [
"10.0.2.4"
]
},
"prod_web": {
"hosts": [
"10.0.2.3"
]
},
"web": {
"children": [
"dev_web",
"prod_web"
]
}
}Step 3: Run Ansible commands using different hosts and groups
The easiest way to run a command against your inventory is to leverage the following command structure:
ansible host/group -i inventory.ini -m commandAll the hosts I’ve used are dummies, so no commands will work, but you can easily see the inventory is filtered:
ansible web -i inventory.ini -m ping
10.0.2.2 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.2 port 22: Operation timed out",
"unreachable": true
}
10.0.2.3 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.3 port 22: Operation timed out",
"unreachable": true
}ansible db -i inventory.ini -m ping
db | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.4 port 22: Operation timed out",
"unreachable": true
}ansible all -i inventory.ini -m ping
10.0.2.2 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.2 port 22: Operation timed out",
"unreachable": true
}
db | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.4 port 22: Operation timed out",
"unreachable": true
}
10.0.2.4 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.4 port 22: Operation timed out",
"unreachable": true
}
10.0.2.3 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh: ssh: connect to host 10.0.2.3 port 22: Operation timed out",
"unreachable": true
}Step 4: Use the inventory in a playbook
To leverage the inventory in a playbook, you will need to specify the host’s argument:
- name: Install Nginx on Web Servers
hosts: web
become: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: presentIf you name this playbook web.yaml, to run it successfully, you will need to use:
ansible-playbook -i inventory.yaml web.yamlWhat are Ansible dynamic inventories?
Many modern environments are dynamic, cloud-based, possibly spread across multiple providers, and constantly changing. In these cases, maintaining a static list of managed nodes is time-consuming, manual, and error-prone.
Ansible’s dynamic inventory feature allows Ansible to automatically generate the list of hosts or nodes in the infrastructure rather than relying on a static inventory file. This is especially useful in dynamic and cloud-based environments where servers may be created, modified, or removed frequently.
Ansible has two methods for tracking and targeting a dynamic set of hosts: inventory plugins and inventory scripts. The official suggestion is to prefer inventory plugins that benefit from the recent updates to Ansible core.
To see a list of available inventory plugins you can leverage to build dynamic inventories, you can execute ansible-doc -t inventory -l. We will look at one of them, the amazon.aws.aws_ec2, to get hosts from Amazon Web Services EC2.
For plugin-specific docs and examples, use the command ansible-doc -t inventory amazon.aws.aws_ec2. Install the Ansible Galaxy collection amazon.aws to work with the plugin by running ansible-galaxy collection install amazon.aws.
Ansible dynamic inventory AWS example
For this example, we have created four EC2 instances on AWS, and we would like to build an inventory file dynamically using the plugin.
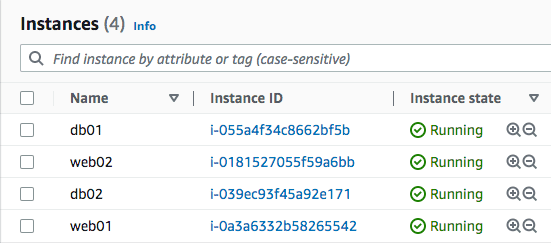
We added two tags, environment and role, on these EC2 instances, which we will use later to create inventory groups.
Let’s create a YAML file named dynamic_inventory_aws_ec2.yml with the plugin configuration required for our use case.
dynamic_inventory_aws_ec2.yml
plugin: amazon.aws.aws_ec2
regions:
- us-east-1
- us-east-2
- us-west-2
hostnames: tag:Name
keyed_groups:
- key: placement.region
prefix: aws_region
- key: tags['environment']
prefix: env
- key: tags['role']
prefix: role
groups:
# add hosts to the "private_only" group if the host doesn't have a public IP associated to it
private_only: "public_ip_address is not defined"
compose:
# use a private address where a public one isn't assigned
ansible_host: public_ip_address|default(private_ip_address)We declare the plugin we want to use and other options, including regions to consider fetching data from, setting hostnames from the tag Name, and creating inventory groups based on region, environment, and role.
Let’s view the generated inventory with the command:
ansible-inventory -i dynamic_inventory_aws_ec2.yml --graph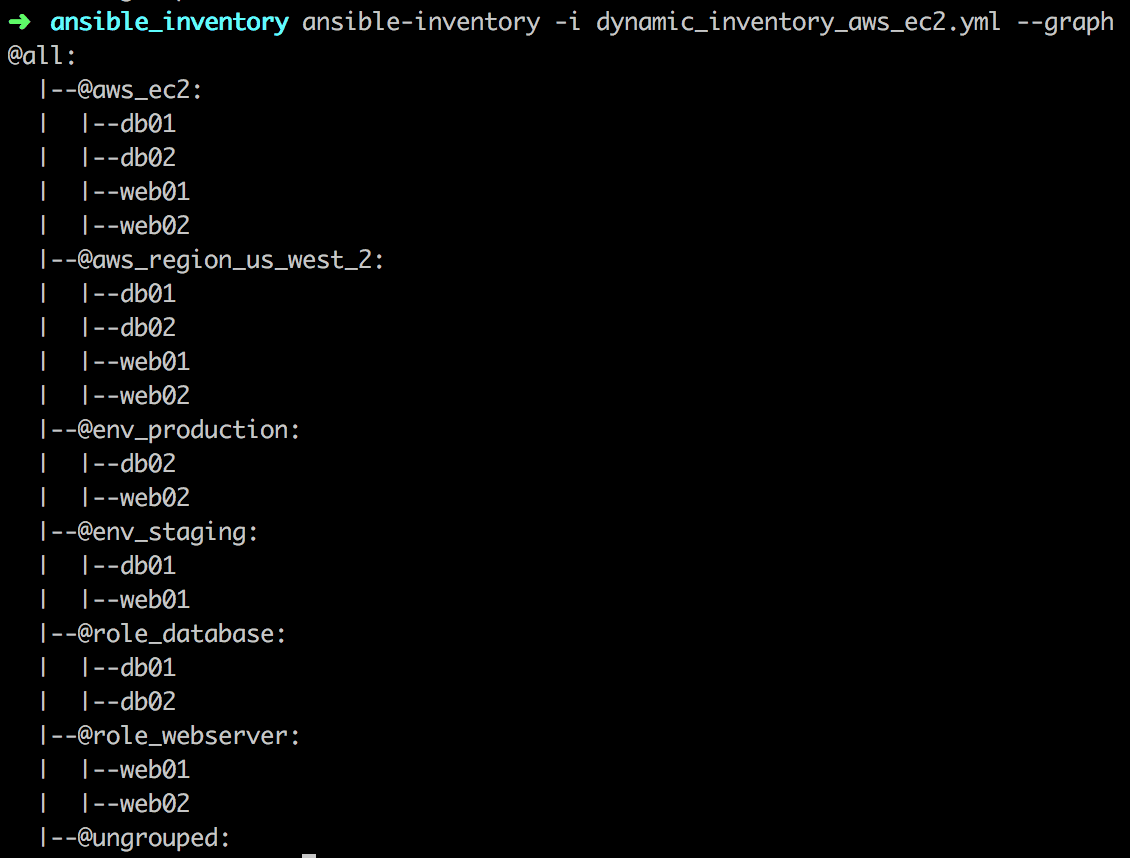
The plugin fetches information from our AWS account and creates several groups according to our configuration and options.
To persist the inventory to a file, you can use this command:
ansible-inventory -i dynamic_inventory_aws_ec2.yml --list --output inventory/dynamic_inventory_aws_ec2 -yIf you want to integrate a source that isn’t covered by the existing inventory plugins, you can develop your own custom inventory plugin.
How Spacelift can help you with Ansible projects
Spacelift’s vibrant ecosystem and excellent GitOps flow can greatly assist you in managing and orchestrating Ansible. By introducing Spacelift on top of Ansible, you can then easily create custom workflows based on pull requests and apply any necessary compliance checks for your organization.
Another great advantage of using Spacelift is that you can manage different infrastructure tools like Ansible, Terraform, Pulumi, AWS CloudFormation, and even Kubernetes from the same place and combine their Stacks with building workflows across tools.
Our latest Ansible enhancements solve three of the biggest challenges engineers face when they are using Ansible:
- Having a centralized place in which you can run your playbooks
- Combining IaC with configuration management to create a single workflow
- Getting insights into what ran and where
Provisioning, configuring, governing, and even orchestrating your containers can be performed with a single workflow, separating the elements into smaller chunks to identify issues more easily.
Would you like to see this in action – or just want a tl;dr? Check out this video showing you Spacelift’s new Ansible functionality:

If you want to learn more about using Spacelift with Ansible, check our documentation, read our Ansible guide, or book a demo with one of our engineers.
Key points
In this article, we explored Ansible inventory basics and various use cases for defining groups and variables in static inventories. We also learned how to combine multiple inventory sources and demonstrated how to fetch an inventory of hosts dynamically from AWS.
Manage Ansible Better with Spacelift
Managing large-scale playbook execution is hard. Spacelift enables you to automate Ansible playbook execution with visibility and control over resources, and seamlessly link provisioning and configuration workflows.
