
When you need to create multiple instances of the same resource in Terraform, you have two options: count and for_each. Both are meta-arguments that let you avoid writing repetitive resource blocks, but they behave differently, and picking the wrong one can cause unexpected infrastructure changes.
Use count when your resources are identical and a simple number is all you need. Use for_each when resources differ between instances or when stable identity matters, because removing one item from a for_each map won’t trigger the recreation of every other resource.
In this article, we will explain the Terraform count and for_each meta-arguments. We will provide examples of how to use each one, when to use them, and when not to use them. Let’s jump in!
What we will cover:
Meta-arguments in Terraform
By default, defining a resource block in Terraform specifies one resource that will be created. To manage several of the same resources, you can use either count or for_each, so you don’t have to write a separate block of code for each one. Using these options reduces overhead and makes your code neater.
Five meta-arguments can be used within resource blocks:
depends_oncountfor_eachproviderlifecycle
Meta-arguments can also be used within modules, which differ slightly from the resource meta-arguments:
depends_oncountfor_eachproviders
Note count, for_each, depends_on are the same between resource blocks and modules, lifecycle is omitted and provider becomes providers.
What is count in Terraform?
count is a meta-argument built into the Terraform language that lets you create multiple instances of a resource from a single resource block.
For example, instead of defining three virtual machines all with their own separate resource blocks, you could define one and add the count = 3 ‘meta-argument’ into the resource block.
How to use Terraform count
The count meta-argument accepts a whole number and creates the specified number of resource instances.
Each instance is created with its own distinct associated infrastructure object, so each can be managed separately. When the configuration is applied, each object can be created, destroyed, or updated as appropriate.
What is for_each in Terraform?
for_each is another loop in Terraform that lets you create multiple resources of the same kind. To use it, you will need to either leverage a map or a set expression. These expressions can be defined either as a variable, a local, or even directly as an expression at the resource level inside the for_each parameter.
for_each exposes one attribute called each. This attribute contains a key and value (if you are using a map), and a value (if you are using a set). These can be used with each.key and each.value.
How to use Terraform for_each
Let’s look at an example that uses a map(object) local expression:
locals {
instances = {
dev1 = {
instance_type = "t2.micro"
ami_id = "dev1ami"
}
dev2 = {
instance_type = "t3.micro"
ami_id = "dev2ami"
}
dev3 = {
instance_type = "t3.micro"
ami_id = "dev3ami"
}
}
}
resource "aws_instance" "this" {
for_each = local.instances
instance_type = each.value.instance_type
ami = each.value.ami_id
tags = {
Name = each.key
}
}In this example, we will create three instances:
- The first one will have a “t2.micro” instance type, a “dev1ami” ami, and a “dev1” Name tag.
- The second one will have a “t3.micro” instance type, a “dev2ami” ami, and a “dev2” Name tag.
- The third one will have a “t3.micro” instance type, a “dev3ami” ami, and a “dev3” Name tag.
When to use for_each instead of count?
Choosing between count and for_each depends on how similar or different the resources in your configuration are.
If the resources you are provisioning are identical or nearly identical, then count is a safe bet. It works well when you need multiple copies of the same resource with no meaningful differences between them.
However, if elements of the resources change between the different instances, for_each is the way to go. Using for_each gives you more control, better stability, and safer plan outputs when your resources have unique attributes.
To understand why this matters, let’s look at an example that highlights the core problem with using count for non-identical resources:
locals {
instances = [
{
instance_type = "t2.micro"
ami_id = "dev1ami"
},
{
instance_type = "t3.micro"
ami_id = "dev2ami"
},
{
instance_type = "t3.micro"
ami_id = "dev3ami"
}
]
}
resource "aws_instance" "this" {
count = length(local.instances)
instance_type = local.instances[count.index].instance_type
ami = local.instances[count.index].ami_id
}In this example, if you create these instances and want to remove the second one and reapply the code, this will recreate your third instance because of the index change — the third instance initially has an index 2, but after the second instance is removed, the third instance will have an index 1.
Now imagine having 50 instances in your configuration and needing to remove one from the beginning of the list. Almost all the instances will be recreated, which can cause serious downtime, data loss, or unintended disruption in production environments.
This is exactly where for_each shines. Because each element is identified by a unique key (a name) instead of a numeric index, removing one element from the map or set will not affect the other elements. Terraform can accurately track each resource by its key, making additions and removals safe and predictable.
On the other hand, count has a notable advantage when it comes to conditionally creating resources. Using count with a ternary expression is simpler and more readable than achieving the same result with for_each:
locals {
enable_instance = true
}
resource "aws_instance" "this" {
count = local.enable_instance ? 1 : 0
…
}In the above example, an instance will be created only if local.enable_instance is true.
Terraform count vs. for_each table summary
Below you can find a detailed comparison of the Terraform count and for_each meta-arguments to help you decide which one fits your use case.
| Feature | count |
for_each |
| Type | Meta-argument | Meta-argument |
| Input | A whole number (integer) | A map or set of strings |
| Resource identification | Numeric index (e.g. aws_instance.this[0]) |
String key (e.g. aws_instance.this["dev1"]) |
| Best use case | Identical resources or conditional creation | Resources with unique attributes per instance |
| Conditional creation | Simple using a ternary (condition ? 1 : 0) |
Possible but less straightforward |
| Behavior on item removal | Index shift can cause unintended resource recreation | Only the removed resource is affected |
| Order sensitivity | Yes, changing order can trigger replacements | No, resources are tracked by key, not position |
| Referencing current item | count.index | each.key and each.value |
| Suitable for scaling identical copies | Yes | Possible but unnecessarily complex |
| Suitable for varied configurations | Risky due to index dependency | Yes, designed for this purpose |
Terraform count example: Deploying multiple resources
Let’s look at an example.
The code below sets up the remote backend for the Terraform state file in Azure Storage and then creates a single group in Azure AD called Group1.
provider "azurerm" {
features {}
}
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = ">=2.95.0"
}
azuread = {
source = "hashicorp/azuread"
version = ">=2.17.0"
}
}
backend "azurerm" {
resource_group_name = "tf-rg"
storage_account_name = "jacktfstatesa"
container_name = "terraform"
key = "adgroups.tfstate"
}
}
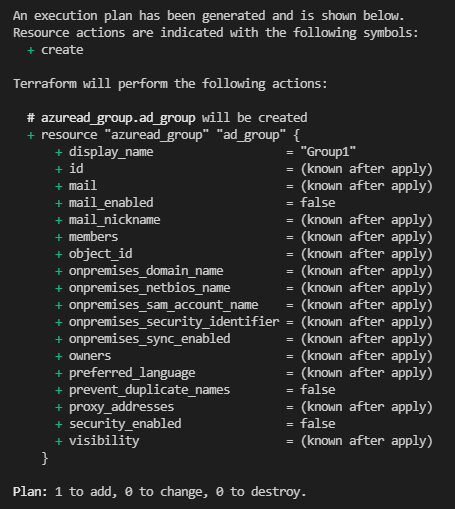
resource "azuread_group" "ad_group" {
display_name = "Group1"
security_enabled = false
mail_enabled = false
}
Let’s now add three groups.
We could simply duplicate the azuread_group three times, like so:
resource "azuread_group" "ad_group" {
display_name = "Group1"
security_enabled = false
mail_enabled = false
}
resource "azuread_group" "ad_group" {
display_name = "Group2"
security_enabled = false
mail_enabled = false
}
resource "azuread_group" "ad_group" {
display_name = "Group3"
security_enabled = false
mail_enabled = false
}count.As a best practice, we will split the code into three files, main.tf, variables.tf and terraform.tfvars.
main.tf
provider "azurerm" {
features {}
}
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = ">=2.95.0"
}
azuread = {
source = "hashicorp/azuread"
version = ">=2.17.0"
}
}
backend "azurerm" {
resource_group_name = "tf-rg"
storage_account_name = "jacktfstatesa"
container_name = "terraform"
key = "adgroups.tfstate"
}
}
resource "azuread_group" "ad_group" {
count = 3
display_name = var.ad_group_names[count.index]
security_enabled = false
mail_enabled = false
}variables.tf
variable ad_group_names {
type = list(string)
description = "List of all the AD Group names"
}terraform.tfvars
ad_group_names = ["Group1", "Group2", "Group3"]Three groups — Group1, Group2, and Group3 — are created when you run this code. This code neatly creates as many groups as required with a single resource block. More can be added by increasing the count value and adding a group name to the terraform.tfvars file.
The count.index variable is used on line 26 on the main.tf file. This represents the index number of the current count loop. The count index starts at 0 and increments by 1 for each resource. You include the count index variable in strings using interpolation. If you don’t want to start the count at 0 you can start at another value by incrementing the value, e.g. to Increment the count by three:
count.index + 3
This approach is also handy for adding numbers to the names of resources. For example, when you are creating multiple VMs using count, the count.index variable can be appended to the name to make it unique.
But we can make the code better…
How to use expressions in count?
The count meta-argument also accepts numeric expressions. The values of these expressions must be known at runtime, before Terraform performs any remote resource actions. Terraform must know the values of the expression and can’t refer to any resources that values are known for only after the configuration is applied.
For example, consider we have a simple module to create a group in Azure Active Directory. This consists of three files, main.tf, output.tf, and variables.tf contained in a folder.
main.tf
resource "azuread_group" "ad_group" {
count = length(var.ad_group_names)
display_name = var.ad_group_names[count.index]
owners = var.group_owners_list
prevent_duplicate_names = true
security_enabled = true
}output.tf
output "ad_group_names" {
value = azuread_group.ad_group.*.display_name
}
output "ad_group_id" {
value = azuread_group.ad_group.*.idvariables.tf
variable "ad_group_names" {
type = list(string)
description = "list of all the AD groups that were created"
}
variable "group_owners_list" {
type = list(string)
description = "The name of the of the owner to be added to the groups"
}On line two main.tf uses the ‘collection function’ length to inspect how many items are being passed in the variable var.ad_group_names , and creates a new Azure Active Directory group for each one. length determines the length of a given list, map, or string.
To call the module, we need the main.tf, variables.tf and terraform.tfvars files.
main.tf
module "azure_ad_groups" {
source = "../../modules/azure_ad_group"
ad_group_names = var.groups_list
group_owners_list = var.group_owners_list
}variables.tf
variable "group_owners_list" {
type = list(string)
description = "The name of the of the owner to be added to the groups"
}
variable "groups_list" {
type = list(string)
description = "The name of the of the groups"
}terraform.tfvars
group_owners_list = ["jack.roper@madeup.com"]
groups_list = ["Group1", "Group2", "Group3"]On running terraform apply, this configuration would again create three Azure AD groups, as we have specified three in the groups_list variable in the terraform.tfvars file (Group1, Group2 and Group3).
As we saw in the previous example, the benefit of this is that we don’t have to update the count value manually, as this is calculated depending on how many group names are specified in the terraform.tfvars file.
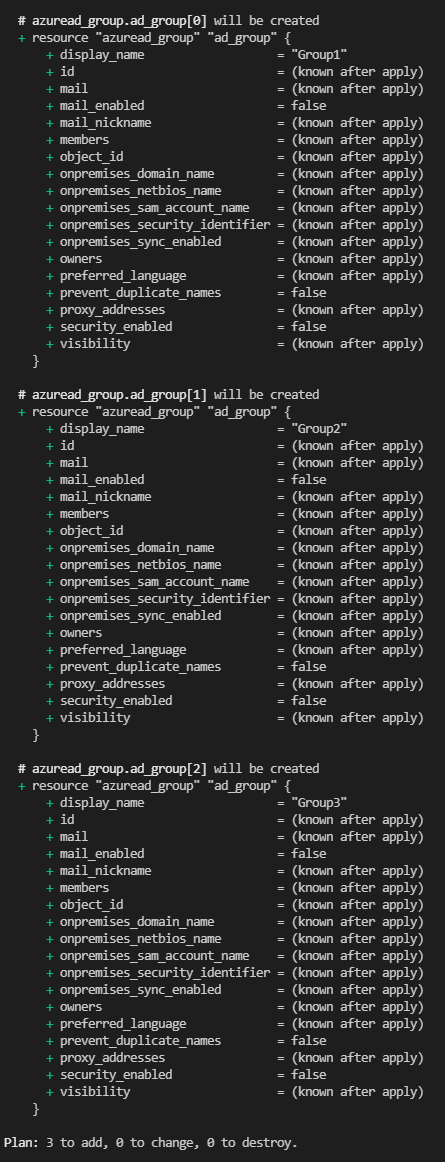
Terraform for_each example: Deploying multiple resources
Because this post focuses on using the count meta-argument, it is also good to know when and how to use for_each.
Like the count argument, the for_each meta-argument creates multiple instances of a module or resource block. However, instead of specifying the number of resources, the for_each meta-argument accepts a map or a set of strings. This is useful when multiple resources with different values are required. Consider our Active directory groups example, with each group requiring a different owner.
A map is defined like this:
for_each = {
"Group1" = "jack.roper@madeup.com",
"Group2" = "bob@madeup.com",
"Group3" = "john@madeup.com"
}A set of strings would be defined like this (used with the toset function to convert a list of strings to a set):
for_each = toset( ["Group1", "jack.roper@madeup.com"] ["Group2", "bob@madeup.com"] ["Group3", "john@madeup.com"])When providing a set, you must use an expression that explicitly returns a set value, like the toset function.
To reference these definitions, the each object is used.
If a map is defined, each.key will correspond to the map key, and each.value will correspond to the map value.
In the example above, each.key will show the group name (Group1, Group2, or Group3), and each.value will show the emails (“jack.roper@madeup.com”, “bob@madeup.com”, or “john@madeup.com”).
If a set of strings is defined, each.key or each.value can be used and will correspond to the same thing.
Deploying Terraform resources with Spacelift
Terraform is really powerful, but to achieve an end-to-end secure GitOps approach, you need a product that can run your Terraform workflows. Spacelift takes managing Terraform to the next level by giving you access to a powerful CI/CD workflow and unlocking features such as:
- Policy as code (based on Open Policy Agent) — You can control how many approvals you need for runs, the kind of resources you can create, and the kind of parameters these resources can have, and you can also control the behavior when a pull request is open or merged.
- Multi-IaC workflows — Combine Terraform with Kubernetes, Ansible, and other infrastructure as code tools such as OpenTofu, Pulumi, and CloudFormation, create dependencies among them, and share outputs.
- Build self-service infrastructure — You can use Blueprints and Templates to build self-service infrastructure; simply complete a form to provision infrastructure based on Terraform and other supported tools.
- Spacelift Intelligence — An AI-powered layer that adds natural language provisioning, diagnostics, and operational insight to your Terraform workflows, helping you move faster without sacrificing governance.
- Integrations with any third-party tools — You can integrate with your favorite third-party tools and even build policies for them. For example, you can integrate security tools in your workflows using Custom Inputs.
- Drift detection and remediation — Spacelift continuously monitors your environments for discrepancies between your live infrastructure and your declared infrastructure as code, and lets you trigger automatic reconciliation to resolve detected drift.
Spacelift also enables you to create private workers inside your infrastructure, which helps you execute Spacelift-related workflows on your end. The documentation provides more information on configuring private workers.
To learn more about Spacelift, create a free account today or book a demo with one of our engineers.
Summing up
count and for_each are powerful meta-arguments that can be used to make your code simpler and more efficient, saving you valuable time and effort.
Terraform count is used when you want to create a specific number of resources based on a fixed or conditional count, producing a single resource list indexed numerically. You use for_each to create resources based on a map or set of strings, enabling more granular control by associating each resource with a unique key from the collection.
Note: New versions of Terraform are placed under the BUSL license, but everything created before version 1.5.x stays open-source. OpenTofu is an open-source version of Terraform that expands on Terraform’s existing concepts and offerings. It is a viable alternative to HashiCorp’s Terraform, being forked from Terraform version 1.5.6.
Discover a better way to manage Terraform
Spacelift helps manage Terraform state, build more complex workflows, and supports policy as code, programmatic configuration, context sharing, drift detection, resource visibility, and many more.
Frequently asked questions
What happens to Terraform state when I switch from count to for_each?
Terraform treats count-managed and for_each-managed resources as different addresses in state, so swapping one for the other will cause Terraform to plan a destroy-and-recreate of all affected resources. To avoid this, use terraform state mv to rename each resource instance to its new key before applying any configuration changes.
Can I use count and for_each in the same resource block?
No. Terraform doesn’t allow both meta-arguments on the same resource or module block.
Is for_each more performant than count?
In practice, performance differences are negligible for most configurations. The more important consideration is plan-time safety: for_each produces more predictable plans when your resource set changes, which matters far more than raw speed.
HashiCorp Developer | Terraform Docs. Meta-arguments. Accessed: 21 October 2025
HashiCorp Developer | Terraform Docs. Manage similar resources with count. Accessed: 21 October 2025
