
Policy as code allows you to codify your rules and decision-making to automate their execution. This lets products expose a programmatic, composable language for policies instead of having to build very complex purpose-specific UIs offering all options.
Possibly the most popular policy-as-code engine is Open Policy Agent. It’s open source and uses the Rego language for policy authoring. It’s used in many projects, including Kubernetes and Envoy, and it’s also used extensively in Spacelift.
This article guides you through some of Rego’s fundamental constructs and mechanisms, especially those that are common in the wild, giving you a better understanding of how it all fits together and how to author larger, more advanced policies.
- What is Rego?
- How does Rego work
- How to write a Rego policy
- Testing Rego rules
- Best practices for writing effective Rego policies
The Open Policy Agent playground is the best place to find examples.
What is Rego?
Rego is a declarative query language designed specifically for writing policies in the Open Policy Agent (OPA). It allows users to define rules and policies that can be evaluated to make decisions about authorization, configuration validation, and data filtering. Rego is versatile, providing a powerful way to express policies over complex, hierarchical data structures typically represented in JSON or YAML formats.
It is designed to be flexible and is particularly useful in environments where policies need to be decoupled from the services they govern, such as Kubernetes admission control, API authorization, and infrastructure-as-code validation.
Key features of Rego
The key features of Rego include:
- Declarative configuration: Define what a policy should enforce rather than how to enforce it.
- Human-readable: Rego’s syntax is designed to be easy to understand for developers, security professionals, and administrators.
- JSON-friendly: Policies operate over JSON data structures, aligning with modern APIs and cloud-native environments.
- Logic-based: Rego is built on the principles of Datalog, a well-established logic programming language, and allows for expressive and powerful rule definitions.
Would you prefer this in video format? Watch the video below to learn more about the Rego policy language:

Rego vs. traditional programming languages
Unlike imperative languages that require step-by-step instructions, Rego operates declaratively — focusing on the desired outcome rather than how to achieve it. Each rule in Rego is structured so that all specified conditions must be met for the rule to apply. Open Policy Agent (OPA) handles the evaluation details, making it one of the most important aspects of Rego, which can initially be confusing for engineers accustomed to imperative programming.
Rego has powerful query capabilities, making it easy to express rules about permissions and constraints. It also works seamlessly with JSON data structures.
How does Rego work?
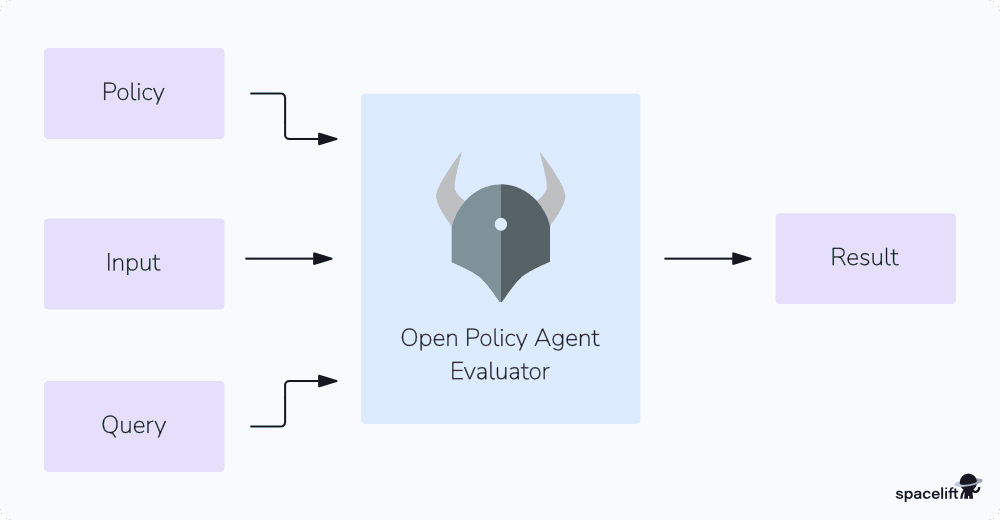
Rego evaluates input data against defined policies and returns decisions based on logical expressions. It queries data structures like JSON, and its rule-based syntax allows users to specify what needs to be enforced rather than how to enforce it, making it highly adaptable for cloud-native applications, APIs, and infrastructure.
1. Input
Rego uses data-driven evaluation and will require input data. This data is usually in a JSON format and will be used by all the rules and queries to make policy decisions. The data can be a configuration, a change plan, or any other information relevant to your policy.
2. Rules
Each rule in Rego defines a logical assertion about your data. Rules can reference other rules, letting you create complex policies. When a policy is evaluated, Rego checks the rules against the provided input and decides the outcome based on the rule’s conditions.
3. Queries
Queries effectively run your rules against the input data. Depending on how you configure your rules, the queries can return a simple true/false response or even complex data structures. They can be used interactively in development environments, or programmatically via APIs.
How to write a Rego policy
To write a Rego policy, define rules and expressions that enforce specific constraints or conditions. Rego policies typically consist of rules that evaluate to true or false based on input data, using queries to filter or validate information.
1. Decisions
When talking about Rego, it’s best to start with decisions.
Decisions in Rego are used as the output of policies but also as temporary variables anywhere. A common misconception is that they have to be true/false. Decisions can be strings, arrays, objects, sets, etc., and you can have as many of them in your policy as you want.
For example, you can have a simple boolean decision with a constant,
allow = trueor reference a different variable.
allow = accessible_by_admin and is_adminBasically, this is normal variable (decision) assignment.
Rego also allows you to use block notation for assignments:
allow {
accessible_by_admin := startswith(path, “/admin/”)
accessible_by_admin
is_admin
}Each line can be an assignment or true/false expression. The result of the whole block will be true only if the expression in each line evaluates to “true,” letting you build complex rules that use many other decisions and variables inside them. We can check multiple predicates, but the decision will be “true” only if all checks succeed.
We can also have a decision that’s an OR of two other decisions, like here:
is_admin {
input.user.admin
}
is_endpoint_public {
startswith(path, “/public/”)
}
allow {
is_admin
}
allow {
is_endpoint_public
}As you can see, a block for a decision can be repeated multiple times, and the decision will be true if any of the blocks evaluate to “true.”
2. Some
The above block is very simple and linear, but we can also do something slightly more complicated. Let’s say we have a request path and an array allowed_path_prefixes and want to check if the path matches any prefix. In that case, we can specify an additional variable for the index:
allow {
some i
startswith(request.path, allowed_path_prefixes[i])
}This will intuitively work by Rego choosing an i, moving to the second line, and if it fails, going back, trying another i, and so on until it finds an i that leads to all lines being true. If no such i is found, then allow will be null (technically speaking, it will be undefined).
In human terms, you can read this as “set allow to true if, for some value of i, the request path starts with the i’th allowed path prefix,” or, in even more human terms, “set allow to true if the request path starts with any of the allowed path prefixes.”
If you have more such variables, you can add them separated by commas next to the i:
some i, j, k, l, m, n, o, pAdditionally, if this i is only needed in a single place, like in the above example, you can substitute it with an underscore instead:
allow {
startswith(request.path, allowed_path_prefixes[_])
}We can also look at an example closer to Spacelift, where we may want to decide if a commit is worth a Terraform execution or whether it should just be ignored. We get a list of files changed by the commit, and we also have a couple of paths that are of interest to Terraform.
Here we’ll check if any of the paths changed starting with one of the interesting paths:
interesting_path_prefixes := [
“/src/terraform”,
“/src/modules”
]
track {
startswith(input.affected_files[_], interesting_path_prefixes[_])
}We’re using two underscores in a single line to mean “is there any pair of (affected file, interesting path prefix) such that the file starts with the prefix.”
But wait, there’s no allow rule here? Is that a valid policy? Yes, it is! Policies can have arbitrary sets of decisions, with those decision being of arbitrary types. It’s just that allow based policies are one of the most obvious use cases, but the power of the Rego language extends much further and can be used for all kinds of decisions, as exemplified by the rich selection of policies available in Spacelift.
3. Sets
Rego decisions can also be specified as sets:
allowed_users := [“papaya”, “potato”]
allow[“papaya”] {
“papaya” == allowed_users[_]
}This means “Papaya should be in the allow set if it belongs to the allowed_users list.”
Moreover, with this block notation, you can specify the element as a variable reference from the block itself:
allow[user] {
user := input.user
user == allowed_users[_]
}Using just a single block, you can even specify multiple elements of the set, by having multiple evaluation paths that successfully reach the end of the block and each path having a different user variable.
allow[user] {
user := input.users[_]
user == allowed_users[_]
}The value in the square brackets can actually be an arbitrary expression referencing the block’s variables, so if we have a policy whose decisions are warnings based on resources changed, we could do the following:
forbidden := {“expensive_resource”, “expensive_resource2”}
warn[sprintf(“You shall not use %s”, resource_name)] {
resource_name := input.resources_changed[_].name
forbidden[resource_name]
}
This checks for forbidden resources and displays a pretty warning message if one of them is changed. In this example, you can also see the usage of a set containment check in the last line of the block.
4. Functions
A more advanced feature of Rego is letting you define custom functions you can use as helpers in your policy. Writing functions is very similar to writing block decisions, but with some minor differences:
plus_custom(a, b) := c {
c := a + b
}
out := plus_custom(42, 43)You can see we’re specifying a list of arguments, the variable that should be used as the output, and then have a normal block body. The output of the function will be c as long as the function successfully reaches the end of its body.
However, instead of that output variable, we could also, again, have an arbitrary expression, a constant, for instance:
bucket_is_secure(bucket) := true {
not bucket.public
bucket.encrypted
}
bucket := {"public": false, "encrypted": false}
out := bucket_is_secure(bucket)In this case, the function will evaluate to true if the bucket is not public and is encrypted.
Testing Rego rules
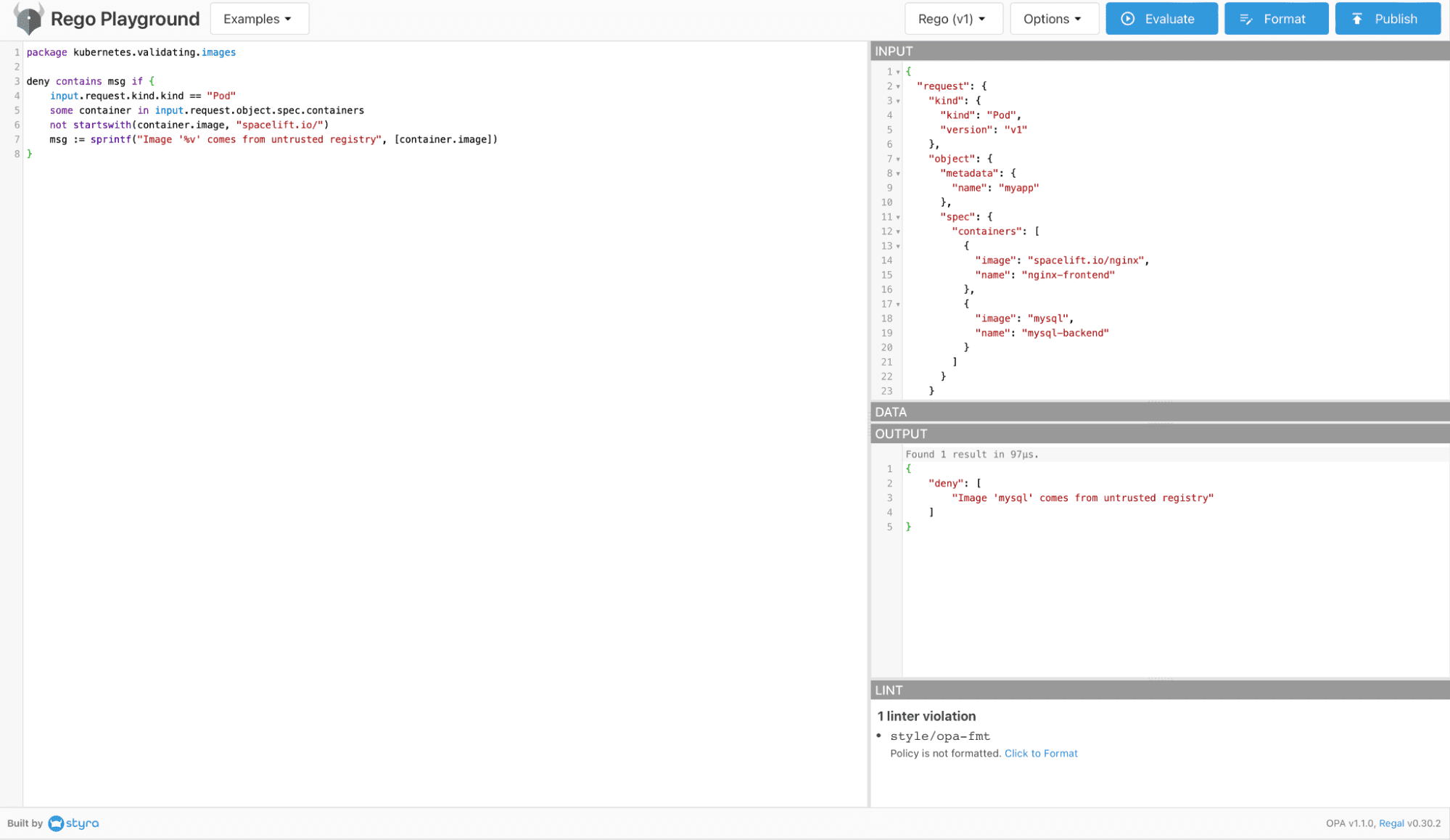
Testing your Rego policies is crucial, as they can be very tricky to get right. To test your policies, you can use the Rego playground or even the OPA CLI. Let’s look at an example input and an example policy:
package kubernetes.validating.images
deny contains msg if {
input.request.kind.kind == "Pod"
some container in input.request.object.spec.containers
not startswith(container.image, "spacelift.io/")
msg := sprintf("Image '%v' comes from untrusted registry", [container.image])
}The policy above checks if the containers created in a pod come from a trusted registry.
This is the JSON input we will use:
{
"request": {
"kind": {
"kind": "Pod",
"version": "v1"
},
"object": {
"metadata": {
"name": "myapp"
},
"spec": {
"containers": [
{
"image": "spacelift.io/nginx",
"name": "nginx-frontend"
},
{
"image": "mysql",
"name": "mysql-backend"
}
]
}
}
}
}Using the Rego Playground
In the Rego Playground, add the policy on the left-hand side of the screen, and add the input on the right-hand side. Next, click on Evaluate and check the output. Because we have an image in our output that does not come from our trusted registry (spacelift.io), our policy will result in a deny:
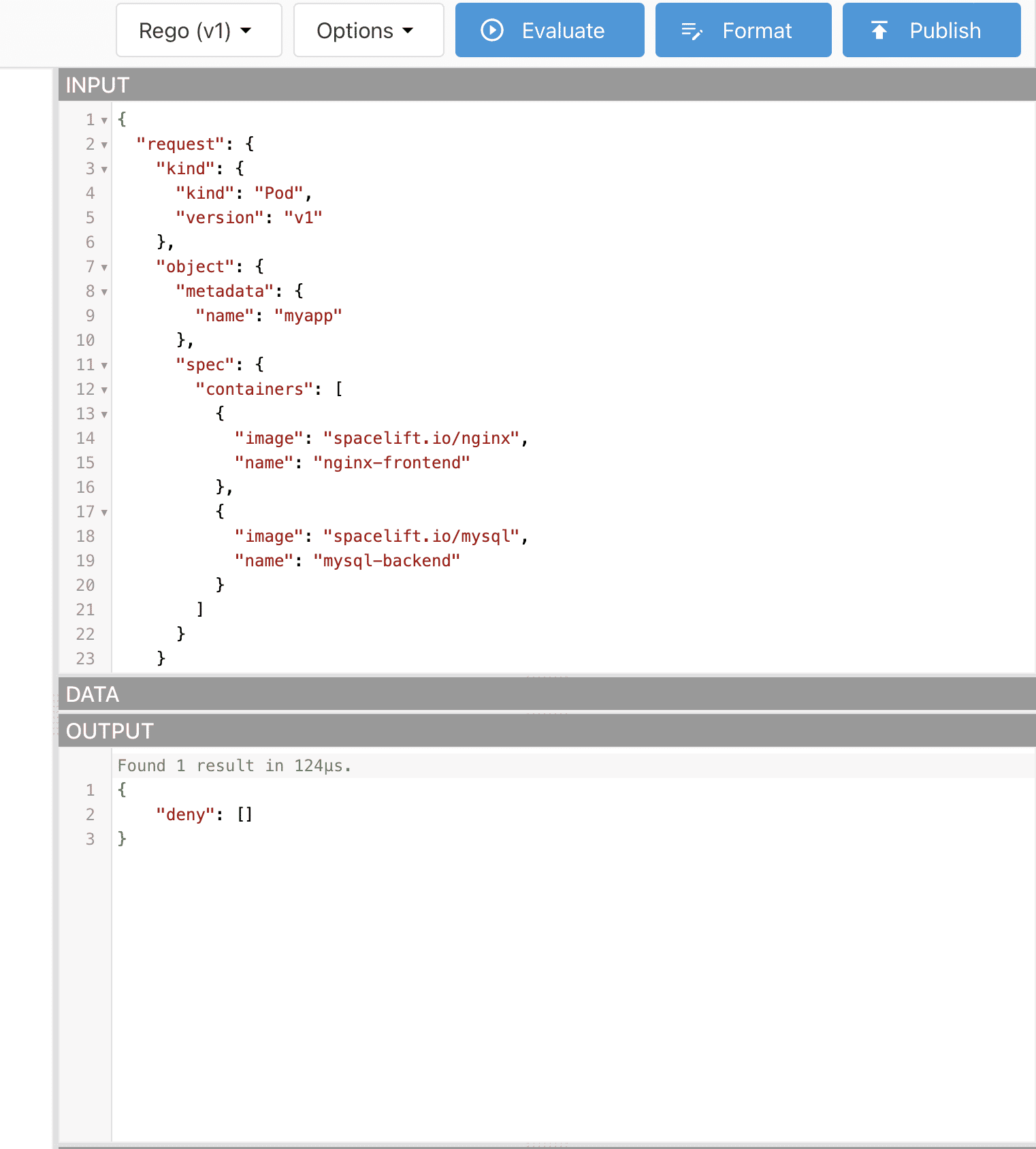
By changing the input for the MySQL image and prefixing it with our trusted registry, we will see that our policy will have an empty list as a response in the deny output:
Using OPA’s command line tool
We will test the same policy from the CLI having OPA installed. We have saved the policy in a file called k8s.rego and the input in a file called input.json, and the input initially has the mysql image without the trusted registry:
opa eval -i input.json -d k8s.rego 'data.kubernetes.validating.images.deny'
{
"result": [
{
"expressions": [
{
"value": [
"Image 'mysql' comes from untrusted registry"
],
"text": "data.kubernetes.validating.images.deny",
"location": {
"row": 1,
"col": 1
}
}
]
}
]
}Now, we’ve modified the input mysql image to use the prefix, and here is the result:
opa eval -i input.json -d k8s.rego 'data.kubernetes.validating.images.deny'
{
"result": [
{
"expressions": [
{
"value": [],
"text": "data.kubernetes.validating.images.deny",
"location": {
"row": 1,
"col": 1
}
}
]
}
]
}Best practices for writing effective Rego policies
Here are some of the best practices when writing effective Rego policies:
- Restrict resources to respect the principle of least privilege – if you are working with compute resources, there are big cost differences between using 1CPU and 50CPUs, so ensure that your compute resources are allowed to have a maximum number of CPUs and RAM that can accommodate your workflows.
- Use clear namings – OPA can be really hard to follow and understand, so don’t complicate it even further by naming your variables a, b, or x. Use descriptive names for your rules and your variables.
- Document your policies – Add comments whenever necessary to make it easy for other team members to understand your policies.
- Test your policies – Use the Rego playground and the OPA CLI to test your policies. If you are using a CI/CD pipeline, you can easily perform integrated tests for your policies using the OPA CLI.
- Separate concerns – Policy logic should be separated from your infrastructure and application code, as in this way it will be easier to identify and solve issues
Defining policies with Spacelift
If you like the sound of Rego and would like to play with a product that puts it front and center, take Spacelift for a spin!
Spacelift policies provide a way to express rules as code, rules that manage your infrastructure–as-code (IaC) environment, and help make common decisions such as login, access, and execution. Policies are based on the OPA project and can be defined using Rego. You can learn more about policies here.
You can define policies for different purposes:
- Use login policies to control who can log in to your Spacelift account and what role they should have once inside.
- Use approval policies to control who can approve or reject runs of your stacks, or to allow or reject runs automatically based on some other condition.
- Use plan policies to control what changes can be applied to your infrastructure. We defined this type of policy in HCP Terraform with Sentinel.
You can find the schema for the input for each type of policy in the Spacelift documentation.
Spacelift also provides a Terraform provider for managing your Spacelift account. This means that you can manage the policies available within your account, along with the Stacks they apply to in code.
If you want to learn more about Spacelift, create a free account today, or book a demo with one of our engineers.
Key points
All of this has just been a quick overview of the parts of Rego we’ve seen most commonly used. With these building blocks, you should be much better equipped to begin authoring your own policies, whichever project you’re using them with.
If you want to learn more, the whole Rego policy language is much bigger, and the best place to dive in is the Official Open Policy Agent Policy Language documentation.
Solve your infrastructure challenges
Spacelift is a flexible orchestration solution for IaC development. It delivers enhanced collaboration, automation, and controls to simplify and accelerate the provisioning of cloud-based infrastructures.
