
Way back in December 2021, I wrote a post explaining how to run Spacelift workers in Kubernetes using Docker-in-Docker. We took that initial approach because it was a relatively simple way to get something working in Kubernetes, and it was a very close match to how we run workers in non-containerized environments like EC2. You could almost think of it like performing a lift and shift.
Although the Docker-in-Docker approach worked, it had some problems:
- The Docker-in-Docker daemon needs to run as a privileged container, which is a potential security issue.
- Each worker in the pool has an always running Pod, which uses up resources in the cluster.
- Scaling down is not safe because we can’t ensure that workers are idle before Kubernetes removes their Pods.
- It’s not easy to make full use of Kubernetes functionality; for example, using the cluster credentials to pull a private runner image.
We were aware at the time that the Docker-in-Docker approach was only ever meant to be a temporary measure, and that eventually we would need to create a more Kubernetes-native approach that solved these problems. We also realized that by integrating more fully with Kubernetes, we could do some really exciting things like provide the ability to view status information about Spacelift workers and runs from within the Kubernetes cluster itself (more on that later!).
How do Spacelift Workers… erm… work?
Before going any further, it’s worth giving a quick overview of the architecture of Spacelift workers. The following diagram shows the basic architecture of a Spacelift launcher:
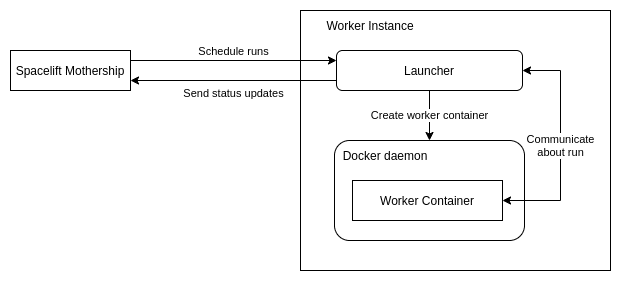
As you can see, there’s a “Worker Instance” that runs a “Launcher” process. This process is responsible for communicating with Spacelift (via MQTT and HTTPS, in case you’re interested), and for creating Docker containers when scheduling messages are received from the Spacelift Mothership.
The Docker-in-Docker approach basically mimics this by running Docker as a side-car container (the DinD containers in the following diagram):
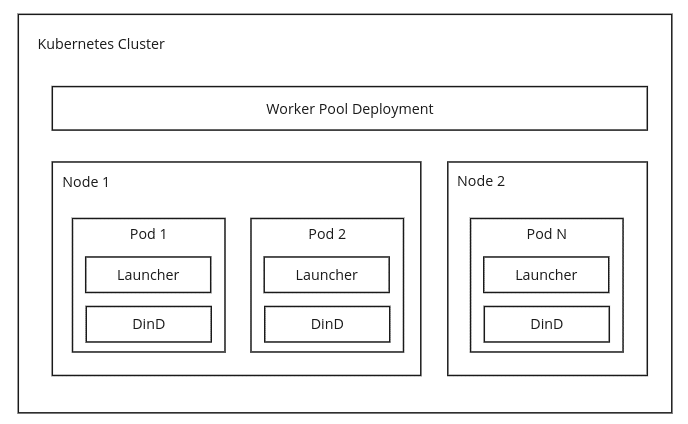
As I mentioned at the start of this post, in the Docker-in-Docker approach used above, a separate Pod is created for each Spacelift Worker in the pool, meaning that if you have a pool size of ten, you’ll have ten Pods sitting in your cluster using up resources, even when all of the Workers are idle.
Enter the operator
The approach we’ve taken to solving these problems is to create a Kubernetes operator. The operator pattern allows you to extend Kubernetes by introducing new types of resources into the Kubernetes API. You then build a controller that knows how to reconcile those custom resources, providing additional functionality.
In our case, we’ve defined two new types of resource:
- A WorkerPool resource that represents a set of Spacelift workers.
- A Worker resource, representing an individual worker.
When using the operator, you only define WorkerPool resources. The operator handles creating the Workers based on your WorkerPool definition and also handles all of the communication with the Spacelift Mothership; for example, registering workers and handling scheduling messages.
The following diagram provides a high-level overview of the WorkerPool operator:
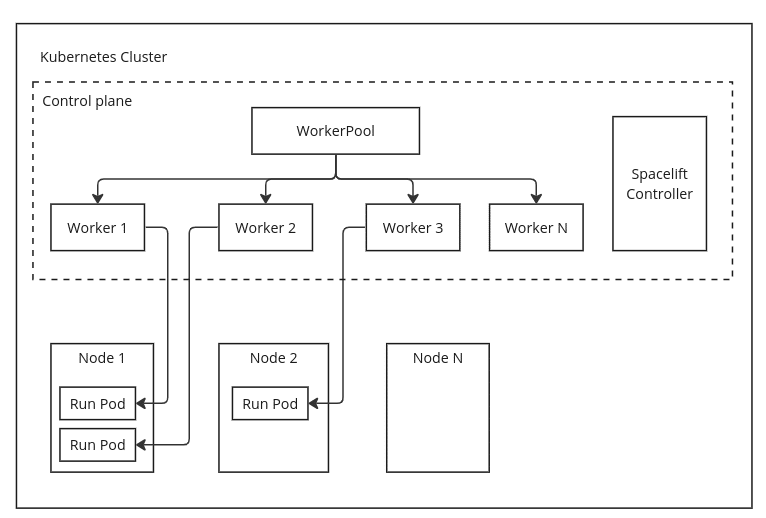
It’s worth noting here that the WorkerPool and Worker resources are only entries in the Kubernetes API. They don’t consume any compute resources themselves, and no Pods exist for workers, except when a run is in progress. The Run Pods in the diagram above are created as a result of Spacelift runs being assigned to a worker in the pool. They only exist for the lifetime of the run, and then they are removed.
The “Spacelift Controller” shown in the diagram is the part responsible for managing the workers and communicating with Spacelift. It runs as one or more Pods in your cluster and reacts to Kubernetes API events as well as messages from Spacelift. When a new run is scheduled onto a worker that the controller manages, it uses the Kubernetes API to create a Pod for that run, based on the configuration information contained in the WorkerPool resource for the worker.
This design means that we no longer need Docker-in-Docker (normal Kubernetes Pods are created for each Spacelift run), we avoid Pods running in the cluster for workers when no runs are in progress, and we can handle scaling gracefully, making sure we don’t remove a worker while a run is in progress. Also, by making virtually all of the Pod configuration options available via the WorkerPool resource, we allow customers to take advantage of standard Kubernetes features like service accounts, node affinity, custom volumes, etc.
So how do I use it?
Getting started with the operator is simple. We provide Kubernetes manifests that can be used with kubectl apply, as well as a Helm chart that can be used to install the Custom Resource Definitions (CRDs) and controller Deployment. For example, here’s how to install the operator using kubectl:
kubectl apply -f https://downloads.spacelift.io/kube-workerpool-controller/latest/manifests.yamlOnce the operator is installed, you need to create a Kubernetes Secret to store your worker pool credentials. These credentials can be created during the standard worker pool setup process on Spacelift.
SPACELIFT_WP_TOKEN=<enter-token>
SPACELIFT_WP_PRIVATE_KEY=<enter-base64-encoded-key>
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: test-workerpool
type: Opaque
stringData:
token: ${SPACELIFT_WP_TOKEN}
privateKey: ${SPACELIFT_WP_PRIVATE_KEY}
EOFAnd finally create your pool:
kubectl apply -f - <<EOF
apiVersion: workers.spacelift.io/v1beta1
kind: WorkerPool
metadata:
name: test-workerpool
spec:
poolSize: 2
token:
secretKeyRef:
name: test-workerpool
key: token
privateKey:
secretKeyRef:
name: test-workerpool
key: privateKey
EOFFor the full details of how to install the operator and configure your WorkerPools, please see the documentation here: https://docs.spacelift.io/concepts/worker-pools#installation.
Inside the cluster
WorkerPools and workers
If we take a look at the cluster (you can use kubectl get workerpools), we can see our new pool:
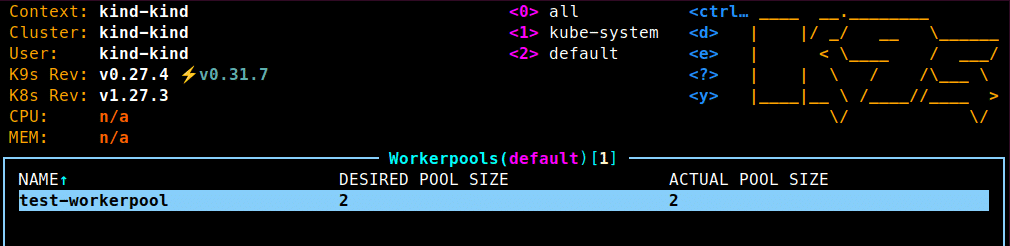
As well as the name of the pool, you can see a desired pool size, and an actual pool size. The desired pool size corresponds to the poolSize field in your WorkerPool definition, and defines how many workers you want to have in your pool. The actual pool size indicates the number of Worker resources that actually exist, connected to the pool. The operator is responsible for creating these workers and adding or removing workers as the poolSize is updated.
If we take a look at the workers in the pool (kubectl get workers), we can see that there are indeed two workers:

The name of each worker is made up of two items: the name of the WorkerPool resource and a unique ID for that worker. Registered indicates whether that worker has been registered with the Spacelift backend, and the status can be either “IDLE” or “BUSY”, indicating whether the worker is ready to process a run, or whether a run is already in progress on that worker.
Describing the worker shows a number of labels and annotations containing information about that worker and the pool it’s connected to:
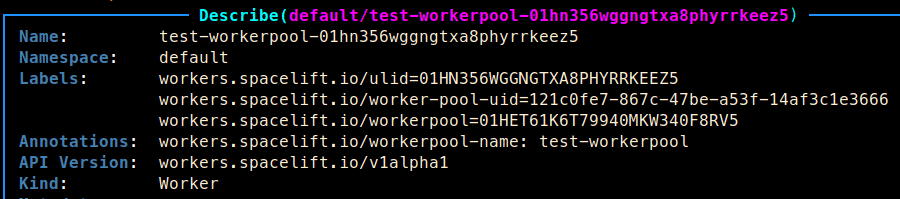
In the screenshot above, the workers.spacelift.io/ulid label contains the unique ID for that worker, and the workers.spacelift.io/workerpool label contains the unique ID for the pool it belongs to. If we take a look in Spacelift, we can see both workers connected to our pool:
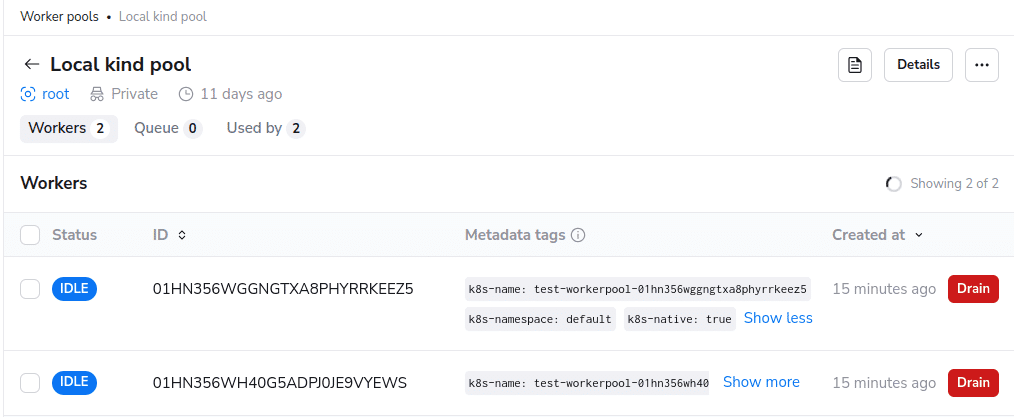
You can also see that we automatically include some information about each worker in the “Metadata tags” column. In this case, we can see a k8s-native tag indicating that this worker is from a native Kubernetes pool, a k8s-namespace tag telling us the Kubernetes namespace that the worker is in, as well as the k8s-name tag that contains the name of the Worker resource in Kubernetes.
Run scheduling
When a run is assigned to a worker in Spacelift, the Spacelift backend sends a message to that worker via MQTT with all the information required to process that run. In the case of the Kubernetes operator, the controller component receives that scheduling message, creates a new Pod via the Kubernetes API to process the run, and then marks the associated Worker resource in Kubernetes as busy.
When this happens, if you query for the workers in Kubernetes, you will see the updated status, as well as the ID of the run assigned to the worker:

If you take a look at your Pods, you will also see a Pod that’s been created for that run:

Once the run completes successfully, the Pod is deleted, and the worker status goes back to IDLE again:

Run Pods
The definition of the Pod created for each run is based on information in the WorkerPool resource. If you create the most basic WorkerPool definition possible, the Pods created will look something like this:
apiVersion: v1
kind: Pod
metadata:
labels:
workers.spacelift.io/run-id: 01HN37WC3MCNE3CY9HAHWRF06K
workers.spacelift.io/worker: 01HN356WGGNGTXA8PHYRRKEEZ5
name: 01hn37wc3mcne3cy9hahwrf06k-preparing-2
namespace: default
spec:
activeDeadlineSeconds: 4200
initContainers:
- name: init
args:
- init
command:
- /usr/bin/spacelift-launcher
env:
... # various env vars
image: public.ecr.aws/spacelift/launcher:<version>
volumeMounts:
- mountPath: /opt/spacelift/workspace
name: workspace
- mountPath: /opt/spacelift/binaries_cache
name: binaries-cache
volumes:
- emptyDir: {}
name: workspace
- emptyDir: {}
name: binaries-cache
containers:
- name: launcher-grpc
args:
- grpc-server
command:
- /usr/bin/spacelift-launcher
env:
... # various environment variables
image: public.ecr.aws/spacelift/launcher:<version>
volumeMounts:
- mountPath: /opt/spacelift/workspace
name: workspace
- name: worker
args:
... # various args
command:
- /opt/spacelift/binaries/spacelift-worker
image: public.ecr.aws/spacelift/runner-terraform:latest
volumeMounts:
- mountPath: /mnt/workspace
name: workspace
subPath: project
- mountPath: /var/spacelift/socket
name: workspace
subPath: socket
- mountPath: /opt/spacelift/binaries
name: workspace
readOnly: true
subPath: binariesThe Pod spec above has been simplified a bit to reduce some of the noise, but at its core are three separate containers used to process the Spacelift run:
- An init container called “init” that performs one-off tasks like downloading the source code for the run, performing role assumption, etc.
- The “worker” container that actually executes the run.
- A container called “launcher-grpc” that provides certain services to the worker container that would normally be provided by the launcher process.
The init and launcher-grpc containers both use the public.ecr.aws/spacelift/launcher container image. The version of the image to use is sent from the Spacelift backend as part of the run scheduling message, ensuring that the image used is compatible with the current version of the Spacelift backend.
The worker container uses the runner image defined in your Spacelift stack, falling back to a default image if none is specified (for example, public.ecr.aws/spacelift/runner-terraform:latest for Terraform stacks). The image to use is sent through from the Spacelift backend based on your stack settings.
Run Pod customization
When designing the operator, we wanted to keep things as flexible as possible and allow users to make use of as much standard Kubernetes functionality as possible. Because of that, we’ve taken the approach of exposing any Pod configuration options as long as there isn’t a good technical reason to avoid doing so.
For example, say you wanted to use a custom service account, you could define a WorkerPool like this:
apiVersion: workers.spacelift.io/v1beta1
kind: WorkerPool
metadata:
name: test-workerpool
spec:
poolSize: 2
token:
secretKeyRef:
name: test-workerpool
key: token
privateKey:
secretKeyRef:
name: test-workerpool
key: privateKey
pod:
serviceAccountName: "my-custom-service-account"The full set of configuration options can be found in our documentation: https://docs.spacelift.io/concepts/worker-pools#configuration.
Scaling WorkerPools
The size of your WorkerPool defines how many Worker resources are created. These workers are effectively virtual, and tell the Spacelift backend that there are resources available to schedule runs. This means the number of workers in your pool defines the maximum concurrent Spacelift runs you can execute at any given time (since each worker can only be assigned a single run at any point in time).
If you need to scale your pool out to allow you to process more concurrent runs, or if you have more workers than you currently need and want to scale down, you have two options: You can edit the poolSize in your WorkerPool resource, or you can use the kubectl scale command. There’s no difference between the two approaches, so feel free to use whichever option makes sense for your use case, but here’s an example of the kubectl scale command:
kubectl scale workerpool test-workerpool --replicas=5One of the major advantages of the operator over the previous Docker-in-Docker approach is when scaling down. Because the Docker-in-Docker approach used Deployments or StatefulSets, there wasn’t a great way to hook into the scale-down process to ensure that a Pod processing a run was not deleted while a run was in progress.
The operator solves this problem. When you attempt to scale down a WorkerPool, the operator only scales down idle workers. If there are currently no idle workers available to scale down, the operator waits until the run for a worker completes, and only then removes that worker from the pool.
Wrapping up
Hopefully, this post has been interesting and has provided some insight into the reasons we created the Spacelift worker Kubernetes operator, as well as shedding some light on some of the internals of how the operator works.
I’m really proud of what we’ve managed to achieve so far, and I’m excited to see customers using the operator to run their pools. If you decide to use the operator, please feel free to reach out to tell me and the rest of the team about your experience and to give us any feedback we can use to improve.
I want to give a huge thanks to everyone at Spacelift who’s contributed to this project. It’s been a multi-team effort, getting tons of help and input from colleagues from our customer success team, solutions engineering, data, and product teams, amongst others. I also want to thank our amazing customers who gave us feedback and participated in early testing of the operator.
And in particular, I want to give a huge shout out to my partner in crime on this project, Elie. It’s been amazing working with such a talented engineer who has such a great mix of pragmatism and attention to detail. There’s no way this project would have been as successful without him!
The Most Flexible CI/CD Automation Tool
Spacelift is an alternative to using homegrown solutions on top of a generic CI. It helps overcome common state management issues and adds several must-have capabilities s for infrastructure management.
