
Note: Terragrunt and OpenTofu/Terraform evolve rapidly. For the latest syntax and behavior, check the official Terragrunt and Spacelift docs.
As Terraform users utilize their code at scale, they typically find redundant variable declarations, complexity in deploying to multiple cloud providers, and a need to manage their growing number of dependencies across deployments. Terragrunt was built to address these use cases and others and has become quite popular amongst the Terraform community.
What is Terragrunt?
Terragrunt is an open-source wrapper for Terraform, created by Gruntwork, that provides a layer of extra features to help users manage their Terraform code at scale. The tool has become widely adopted, with over 9,000 stars and 1.1k forks on GitHub. Terragrunt has a laundry list of use cases for users to use. The Gruntwork team documents an official list of Terragrunt use cases here.
In this article, we will be walking through some of the most notable use cases of Terragrunt and how they relate to the problems Terraform users face daily.
Noteworthy Use Cases
In this section, we will be discussing a select group of notable use cases (in our own words) and the benefits they provide Terraform users.
Keep Your Terraform Configuration DRY
Arguably, the most popular feature of Terragrunt is its ability to help keep your Terraform configuration D.R.Y. – Don’t Repeat Yourself – this relates to the redundancy problem mentioned earlier. Terragrunt is able to achieve this through the use of built-in functions such as find_in_parent_folders() and read_terragrunt_config(). These functions allow you to dynamically load files upstream within “parent” folders, defining them only once in a hierarchical folder structure.
As a somewhat unintentional conflict of this DRY benefit, one could argue that fully leveraging the DRY features of Terragrunt forces users down a path of building large monorepositories. This typically occurs when users start a single repository in which they are organizing/managing all of their Terragrunt code.
This isn’t always the case, of course, as it truly depends on how users choose to organize their folder structure, but it can quickly become an issue if users are not mindful of this. Although monorepositories are not necessarily always a bad thing.
The typical mono-repository Terragrunt structure follows a top-down pattern such as <account>/<region>/<service>/<resourceName>. This allows users to define variables within any top-level folder and have those variables nest down within their respective child folders.
For example, one might define top-level account variables such as accountId or accountAlias within a top-level account.hcl file. You can define these variables only once and have them “loaded” into your lower-level folders at runtime. To do this, you will need to make use of the Terragrunt functions mentioned above. Users will find that using this feature at scale allows for cleaner code, especially when deploying many resources to consume redundant “top-level” values.
As an example, below you’ll find a code snippet of how easy it is to load in top-level variables from a file with a specific name:
include "account" {
path = "${dirname(find_in_parent_folders())}/account.hcl"
expose = true
}Working With Multiple Providers
Using Terragrunt’s generate block, users are able to dynamically generate Terraform code. This feature is most commonly used for dynamically generating Terraform providers to allow for a dynamic multi-account / multi-region Terraform implementation.
Provider Generation
Within the root-level terragrunt.hcl file, you will typically find the code looking something like this:
locals {
# Automatically load region-level variables
region_vars = read_terragrunt_config(find_in_parent_folders("region.hcl"))
aws_region = local.region_vars.locals.aws_region
}
generate "provider" {
path = "provider.tf"
if_exists = "overwrite_terragrunt"
contents = <<EOF
provider "aws" {
region = "${local.aws_region}"
}
EOF
}The code above will dynamically generate a provider.tf file containing dynamic provider contents depending upon where Terragrunt is being run. For example, if you were running terragrunt apply at the following path:
accountName/us-east-1/ec2/instances/exampleThe provider.tf file would be generated within the example folder.
The aws_region variable would be loaded from the region.hcl file which should live within the us-east-1 directory (assume that it exists here with that variable defined)
As a result, the contents of the provider.tf file would be:
provider "aws" {
region = "us-east-1"
}Pretty cool, right? As you can see, the provider was dynamically generated at runtime simply because we defined the region within a top-level folder. Users can take this approach a step further by using account/role information within their provider blocks and can ultimately achieve the ability to assume roles in multiple accounts dynamically using this method.
Keep in mind that technically the generate feature isn’t necessarily restricted to generating provider blocks, so you can always follow this same method to generate Terraform code for other use cases as well.
Dependency Management
With Terragrunt, two dependency-related features can easily be confused. The “dependency” block in Terragrunt allows users to define a dependency to load information from it, primarily used for loading Terraform outputs as inputs. The other dependency feature used by Terragrunt is dependencies. In the dependencies block, users specify a list of paths to folders/files, which Terragrunt should execute before executing on the current file.
Let’s walk through an example of each of these types!
The “Dependency” Block
In the code below, we specify VPC as a dependency and specify the config_path, a relative path to the dependency from which we need to load configuration. In this example, the VPC path lives back a directory in the VPC folder and produces the vpc_id output. Using this dependency block, we can load the vpc_id output and then use it as an input in our current configuration file (full example not shown, as we are focused on simply showing the usage of the dependency block here).
There are, of course, other ways you can pass configuration between your Terraform code, such as using AWS Parameter Store or accessing the configuration using the terraform_remote_state data source. Still, as you can see here, it’s rather convenient to load dependency values using this method. One limitation of this approach you’ll quickly find is that you’re understandably unable to reference dependency values deployed from other repositories. Using AWS Parameter Store or another configuration management solution is a great solution in these situations.
dependency "vpc" {
config_path = "../vpc"
mock_outputs_allowed_terraform_commands = ["validate"]
mock_outputs = {
vpc_id = "vpc-1234567"
}
}
inputs = {
vpc_id = dependency.vpc.outputs.vpc_id
}The “Dependencies” Block
The dependencies block is designed for enforcing the order of operations by Terragrunt. This block is meant for users who intend to eventually make use of the terragrunt run --all workflow, which allows you to execute Terraform against a group of deployments all at once or in a specified order.
Let’s walk through a basic example of what this looks like:
dependencies {
paths = ["../vpc", "../rds"]
}Not much to see here, but notice how you can specify a list of strings, allowing you to specify n number of dependencies that you want to ensure Terragrunt executes on before executing the current file. Similar to the dependency limitation, you are constrained by relative paths, meaning you won’t be able to build dependencies for code that lives in other repositories.
Once you have your dependencies defined, you can then make use of terragrunt run --all plan|apply to execute across the stack.
Terragrunt on Spacelift
Spacelift offers a native Terragrunt platform that supports Run-All, and managed state. To see it in action, check out this post. The older “label = terragrunt” path on the Terraform platform remains available but does not support Run-All.
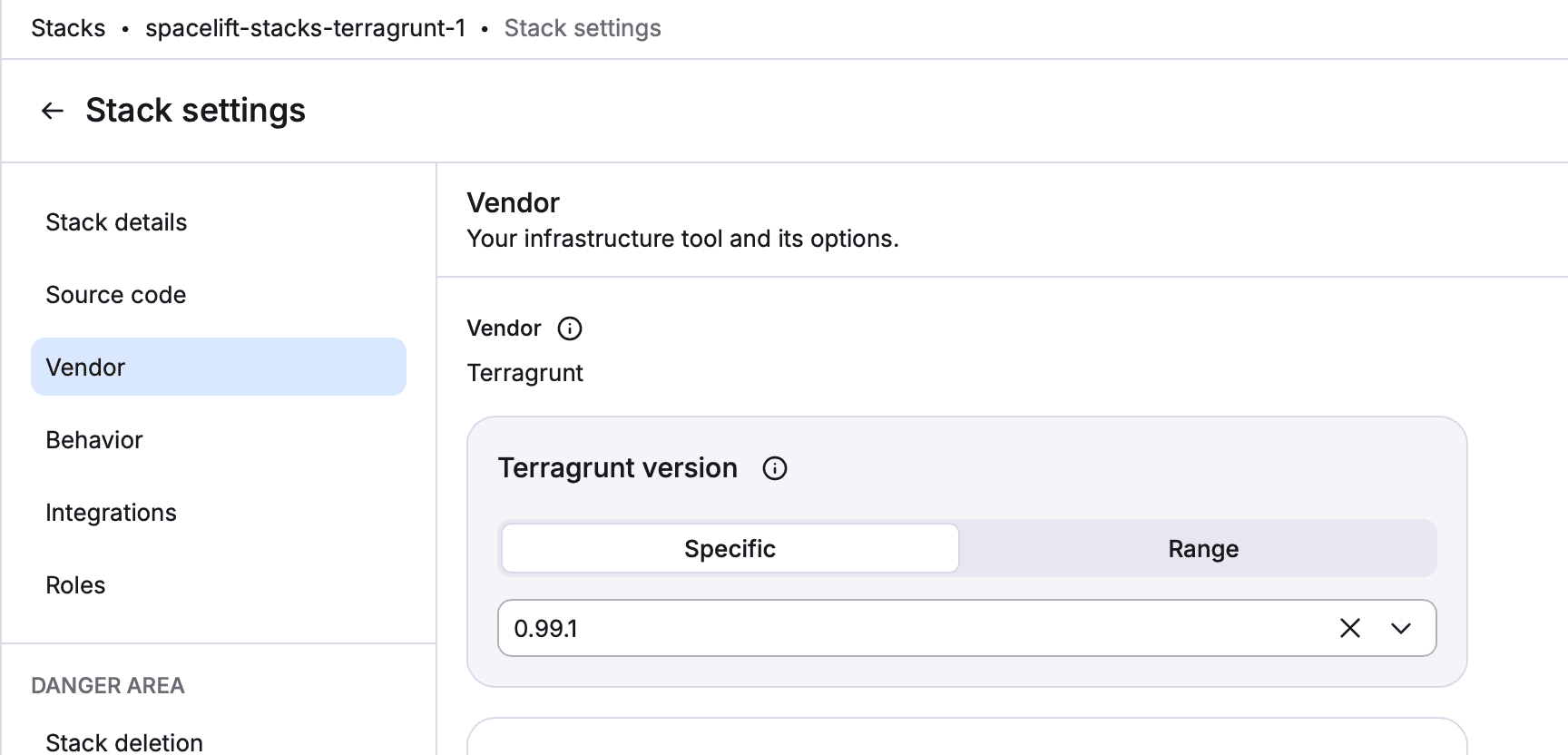
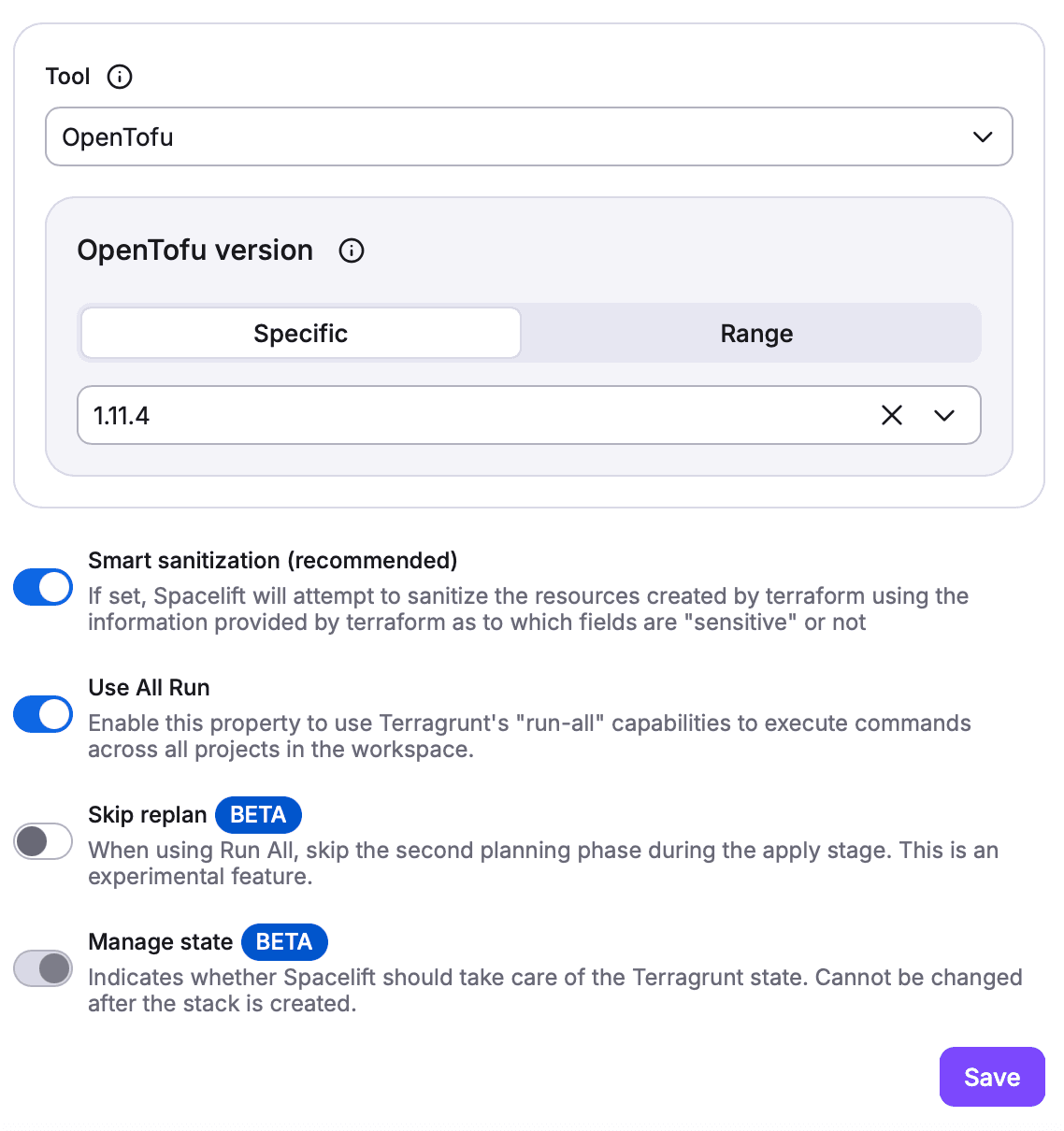
Old Way
Terragrunt can be easily enabled by simply adding the label terragrunt on any stack(s) you would like to enable. Once this label is present, Spacelift will then utilize terragrunt plan/apply commands instead of the typical terraform plan/apply commands.
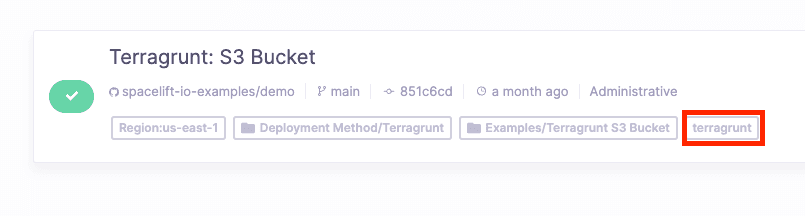
Check out this short video on how easy it is to enable Terragrunt on Spacelift:
Why Spacelift?
Spacelift is the most flexible management platform for infrastructure-as-code. It supports not only Terraform and OpenTofu, but AWS CloudFormation, Pulumi, and Kubernetes. Out of the box, you’ll have support for deploying to multiple cloud providers and multiple cloud accounts.
Furthermore, by running your Terragrunt commands on Spacelift, you can extend the powers of Terragrunt with the powers of Spacelift. Providing you access to other powerful features such as Spacelift Contexts and Policies. For example, using Spacelift Contexts, you can define a collection of variables and files and then attach these to Spacelift stack(s). By doing this, you then have access to those variables/files during runtime.
Remember that account.hcl file scenario we mentioned earlier, in which you would define all of your account-specific variables? This is a great example scenario. You could create a Spacelift Context for (an account-specific context) and then attach this context to all of your Spacelift Stacks that are deploying code for that specific account.
The same concept can be applied to any other grouping mechanism you’d like, whether creating a Context for a region, environment, application, etc. Contexts are a more scalable means of keeping your configuration DRY, without the side effect of creating a large monorepository.
With Spacelift Policies, we could easily have an entirely separate blog post on this topic. In summary, they allow you to build rules using the Open Policy Agent (OPA) to govern your infrastructure as code and its automation. For example, you may want to disallow a specific resource type or even a certain way of configuring that resource type – you can easily achieve such a thing using a Plan Policy.
Summary
In this article, we discussed some of the common issues that Terraform users face and how Terragrunt solves them. We discussed Spacelift’s support for Terragrunt and a few of the additional features. If you found any value in this article, please share it on your social media platform of choice. Wishing you the best of luck in your infrastructure as code journey!
Automation and Collaboration Layer for Infrastructure as Code
Spacelift is a flexible orchestration solution for IaC development. It delivers enhanced collaboration, automation, and controls to simplify and accelerate the provisioning of cloud based infrastructures.
