
Scaling infrastructure as code is not really about writing more HCL or YAML. It’s about keeping dozens of teams, hundreds of repositories, and thousands of resources moving in the same direction without losing control.
Most organizations already use one or more IaC tools — like Terraform, OpenTofu, Pulumi, CloudFormation, Terragrunt, Kubernetes, or Ansible — to define infrastructure in a repeatable way. But as more teams and environments come on board, you start seeing familiar issues: state conflicts, conflicting changes, ad-hoc approvals, and a long list of “please don’t do this” rules that are hard to enforce.
In this guide, we’ll look at what “scaling IaC” really means, why your IaC tool and CI/CD platform on their own aren’t enough, and the patterns successful teams use to build a secure, self-service infrastructure platform. We’ll also show how Spacelift can help you turn those patterns into a consistent experience for your organization.
Limitations of infrastructure as code platforms
Infrastructure as Code tools are excellent at describing what your infrastructure should look like. They’re much less opinionated about how teams should collaborate to get there.
When organizations rely only on their IaC engine plus a remote state backend, the same issues keep coming up:
- State management under pressure – As more people run changes, state quickly becomes a shared bottleneck. You start seeing long-running locks, awkward recovery from failed applies, and drift between what’s in state and what’s in the cloud. Fixing these problems usually involves ad-hoc scripts and heroics.
- Local runs and invisible changes – Letting everyone run plans and applies from their laptop is convenient, but it also bypasses standardized workflows, approvals, and audit trails. It becomes hard to answer simple questions like “who changed production last Tuesday?” or “what changed before this incident?”.
- Security and secrets at scale – State files and configuration often contain sensitive information. Granting broad access is risky. Locking it down too aggressively slows everybody down. Managing secrets, credentials, and least-privilege access across many teams and environments is non-trivial without a common orchestration layer.
- No first-class view of stacks and environments – Your IaC tool understands resources, but your organization thinks in terms of “production EU”, “shared services”, “team X’s sandbox”, or “customer Y”. Dependencies between these areas tend to live in people’s heads or in bespoke CI pipelines, which makes change impact analysis and incident response much harder.
At that point, the limiting factor isn’t your choice of IaC tool, but the lack of an orchestration layer that understands stacks, environments, policies, and people on top of it.
New to IaC? See: What Is Infrastructure as Code? Examples, Best Practices & Tools
Why generic CI/CD tools struggle with IaC at scale
Most teams start by integrating their infrastructure as code into their existing CI/CD system – GitHub Actions, GitLab CI, CircleCI, Jenkins, Azure DevOps, etc. You commit a change, the pipeline runs some checks, and if everything looks good, it applies the change.
That works well for a while. Then the system grows. CI/CD brings consistency, testing, and automation to infrastructure workflows, but it was never designed with infrastructure stacks, environments, and dependencies as first-class concepts.
You add more repos, more environments, more teams, and more policies. At that point, generic CI/CD starts to show its limits:
- Pipelines don’t understand infrastructure – CI/CD tools are built to run arbitrary jobs, not to model infrastructure stacks. They don’t have a native concept of “this stack depends on that one” or “these ten workspaces form the production environment”. That logic ends up hard-coded in YAML files, custom scripts, or tribal knowledge.
- YAML sprawl and duplicated logic – Every team adds its own tweaks: different jobs, naming conventions, approval steps, and notification rules. Over time, you get dozens of similar but slightly different pipelines. Changing a simple policy (for example, “all production changes need two approvals”) turns into a tedious, error-prone search-and-edit exercise.
- Limited policy and governance controls – You can bolt checks into the pipeline, static analysis, security scans, custom scripts, but the CI system itself doesn’t know much about your infrastructure. Enforcing organization-wide rules like “no direct applies to production from feature branches” or “all resources must be tagged a certain way” is possible, but usually fragile.
- Poor visibility for platform and security teams – CI/CD is very good at showing the status of individual pipeline runs. It’s not great at answering infrastructure questions such as:
- Which stacks changed this week?
- Where are we out of date?
- Which environments are currently drifting from their desired state?
To answer these, you end up stitching together logs, dashboards, spreadsheets, and Slack messages. A specialized IaC platform will typically give you stack- and resource-level inventories, state, and history in one place instead.
- Self-service is bolted on, not designed in – If you want developers or other internal teams to request and manage infrastructure themselves, you often need to wrap your CI/CD pipelines in additional tooling – custom CLIs, portals, or ticket flows. Each of those has to be built and maintained on top of already complex pipelines.
None of this means you should throw away your CI/CD system. It’s still the right place for a lot of application build and test work. What it does mean is that scaling infrastructure as code usually requires an IaC-aware platform that can:
- Model stacks, environments, and dependencies as first-class concepts
- Centralize policies and approvals rather than duplicating them across pipelines
- Provide clear visibility into runs, drift, and changes across all your infrastructure
- Integrate cleanly with your existing CI/CD so you keep what works and add what’s missing
In the next section, we’ll look at a few concrete patterns teams use to build that kind of platform and make IaC truly self-service at scale.
Four patterns for managing IaC at scale
When you look at organizations that are successful with infrastructure as code, you see the same patterns show up again and again. The tools differ, but the operating model is surprisingly similar.
Below are four patterns you can apply regardless of which IaC engine you use. We’ll use Spacelift as the example platform, but the principles are general.
1. Standardize on reusable building blocks
Instead of every team reinventing the wheel, you create a small set of well-designed building blocks and encourage everyone to build on top of them.
That usually means:
- A catalog of modules and templates for common components (networks, apps, data stores, monitoring, etc.).
- Clear versioning and ownership for each building block.
- Guardrails built in: secure defaults, logging, tagging, and cost controls baked into the templates rather than added later.
The practical goal is simple: the “right way” should also be the easiest way. A developer starting a new service shouldn’t have to copy-paste from four different repos and a wiki page. They should be able to pick a template, answer a few questions, and get a secure, compliant baseline in minutes.
In Spacelift, this shows up as the Spacelift module registry and Blueprints. You define once how a typical stack should look (which modules it uses, which policies apply, which inputs are configurable), and developers instantiate that blueprint instead of hand-rolling their own stack from scratch.
For non-Terraform tooling, the same principle still applies: define golden paths as reusable repositories plus a blueprint that wires in the right policies, contexts, and integrations.
2. Model environments and ownership explicitly
As IaC spreads, you quickly move beyond “one production account and one staging account”. You end up with multiple clouds, regions, business units, and customer tenants.
To keep that manageable, you need a clear model for:
- Environments – production, staging, dev, sandboxes, demos, etc.
- Tenants or business units – teams, departments, or customers who own those environments.
- Boundaries and blast radius – which changes are allowed where, and by whom.
In practice, that often means separate accounts or projects, consistent naming for stacks and resources, and role-based access so teams can see and change what they own and nothing more.
An IaC orchestration platform can make those concepts first-class. In Spacelift, stacks are grouped into Spaces that map neatly to teams, business units, or customers. RBAC happens at the same level, so you can say “this team can manage everything in this space, but only see read-only information in production,” instead of encoding that logic in dozens of pipelines and documents.
Because Spaces are hierarchical, you can also centralize some capabilities (like admin stacks or shared modules) at the top of the tree and delegate day-to-day ownership farther down.
3. Encode governance as code
Checklists and hand-written runbooks don’t scale. Sooner or later, something important gets skipped. Organizations that scale IaC well treat governance the same way they treat infrastructure: as code.
That usually includes policies for:
- Who can approve changes in which environments
- Which branches can deploy where
- What tags, labels, or annotations resources must have
- Which services, regions, or instance types are allowed
- How cost, security, and compliance checks are enforced
Rather than scattering those rules across wiki pages and pipeline snippets, you define them centrally and apply them consistently to your stacks.
In Spacelift, this is handled through policy-as-code based on Open Policy Agent. Policies live alongside the rest of your code, are versioned, and can be attached at different scopes (organization, space, stack). That allows you to roll out global guardrails while still leaving room for team- or environment-specific rules. For example, “all production changes require at least two approvals.”
Configuration and secrets that those policies depend on (tokens, IDs, common hooks) can be centralized into Contexts, Spacelift’s way of sharing environment variables, mounted files, and hooks safely across stacks. Treating governance this way also makes overall accountability and auditability much easier, because approvals and checks live in code and logs rather than in tribal knowledge.
4. Automate feedback loops: drift, health, and cost
Once you have a lot of infrastructure defined as code, the problem is no longer “can we change things?” but “can we keep everything healthy and up to date?”.
Three feedback loops matter most:
- Drift – spotting when reality no longer matches the code, whether because of manual hotfixes, failed applies, or emergency changes.
- Health and compliance – checking that security baselines, policies, and best practices are still applied over time, not just at creation.
- Cost and usage – understanding how infrastructure changes affect spend, and catching anomalies early.
Without automation, you rely on ad-hoc scripts, manual audits, and incident retrospectives.
An IaC-aware platform can take on a lot of that work. For example, Spacelift can regularly re-run plans to detect drift on your stacks, surface differences in a single place, and optionally trigger reconciliation runs to bring reality back in line with code. The same policy engine you use for approvals can also enforce security and tagging rules on every run, and integrate with scanning tools like tfsec or Checkov.
Cost feedback can be wired into the same loop using the native Infracost integration, letting you see cost impact on pull requests and even enforce cost-based policies.
Over time, this turns into a continuous loop: code changes propose infrastructure changes, policies validate them, the platform applies them, and automated checks keep everything aligned with your standards.
A complex infrastructure example
Imagine a fintech SaaS platform that helps banks manage asset-based lending. Dozens of banks use it in different countries, each with its own regulatory and security constraints. The platform runs on the cloud, with separate accounts, VPCs, databases, queues, Kubernetes clusters, and monitoring for each customer.
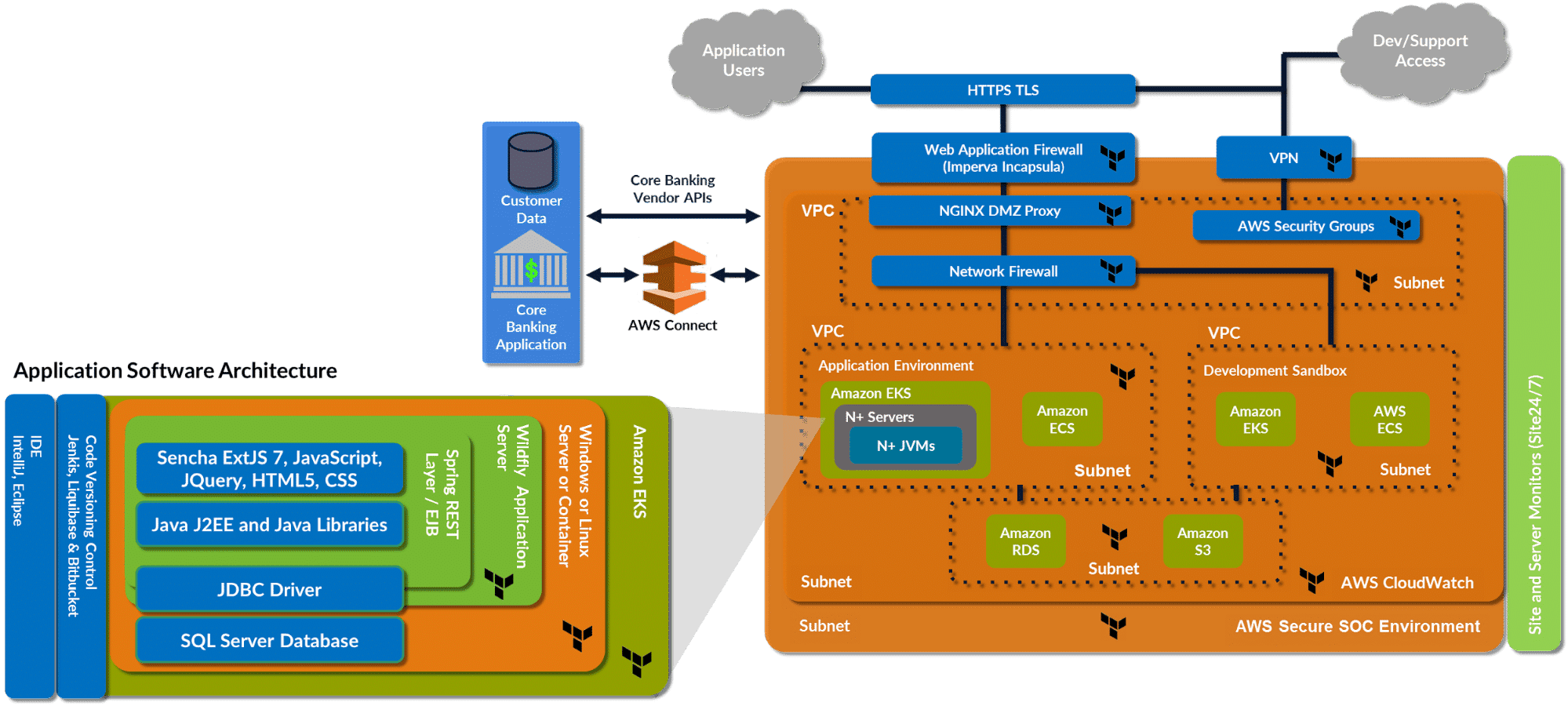
On paper, this is all “solved” with IaC. There are Terraform/OpenTofu modules or Pulumi programs for almost everything: networking, app runtimes, data services, and shared platform components. Spinning up a new bank should just mean plugging in some inputs and letting the pipelines run.
In practice, onboarding a new customer still feels fragile and slow:
- Every bank wants something slightly different: a specific region, stricter encryption rules, a different retention period for logs.
- Each customer exists in multiple environments – development, UAT, production – each with its own blast radius and access model.
- Several teams touch the same tenant: platform, security, data, customer success, sometimes even the customer’s own engineers.
Without an IaC-aware orchestration layer, most of the complexity leaks into ad-hoc conventions. You copy a folder from the last customer, tweak some variables, and duplicate a CI pipeline. Relationships between stacks – “network first, then databases, then app”, “shared services before tenant services” – are wired into YAML and shell scripts. Guardrails live in separate documents: “don’t ever run applies from this branch”, “security must approve cross-region data flows”, “never share this account between customers”.
This works for the first two or three tenants. By the time you have ten banks, three environments each, and multiple teams shipping changes in parallel, you’re juggling:
- Conflicting changes against shared stacks.
- Manually enforced rules about who can touch production.
- Drift between what’s in the code, what’s in state, and what actually runs in the cloud.
At that point, the problem isn’t that Terraform or Pulumi can’t describe the infrastructure. It’s that you’re missing a consistent way to model stacks, environments, and policies across all of those customers and teams.
We’ll come back to this fintech example when we talk about reusable building blocks, explicit environment modeling, governance as code, and automated feedback loops.
Fintech example: security and compliance overlay
Now zoom in on just one slice of that fintech platform: security and compliance.
Each bank expects strong isolation and clear evidence of control. In practice, that means separate accounts or projects, dedicated VPCs, strict network boundaries, customer-specific keys, centralized logging, and often integrations with external systems like core banking or fraud detection.
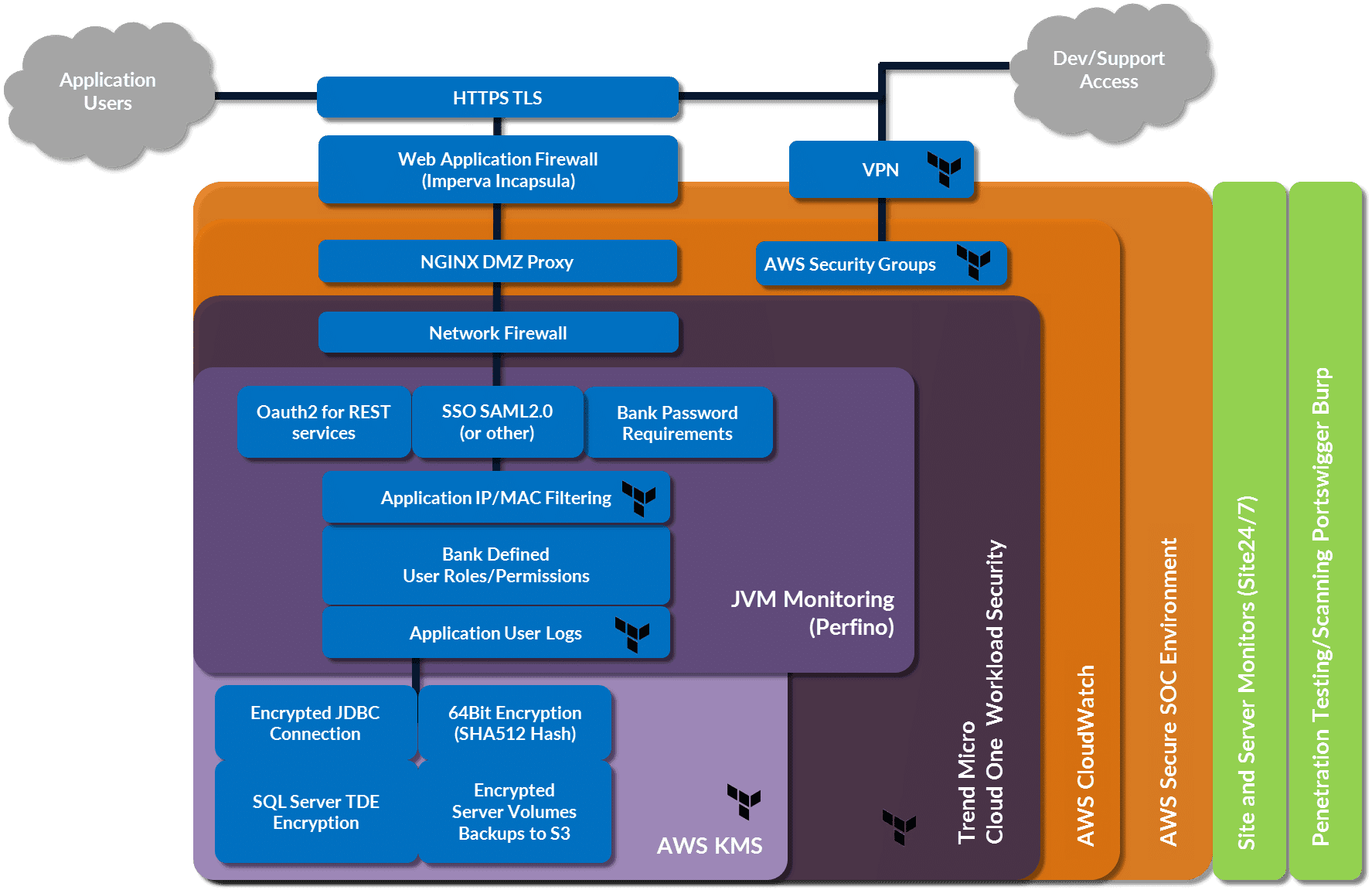
On a diagram, it’s just another layer: more boxes for firewalls, gateways, key managers, SIEM pipelines, and monitoring tools. In day-to-day work, it’s where things tend to get messy.
Different customers insist on different providers or security add-ons. Some require all data to stay in a single region; others demand cross-region backups. One regulator cares deeply about log retention; another focuses on fine-grained access control. Over time, those requirements turn into a patchwork of “special cases” scattered across modules and pipelines.
Without governance encoded as code, security shows up as:
- Long checklists in Confluence that someone is supposed to follow when creating or updating an environment.
- Manual steps in CI pipelines that rely on people remembering how things are “normally done”.
- Emergency hotfixes in the cloud console that never find their way back into Git.
Audits become painful. You can probably prove what the current setup looks like, but explaining how it got there – and showing that every change followed the right process – takes weeks of digging through logs, tickets, and Git history.
An IaC-aware platform gives you a way to treat this “security overlay” like any other part of the system:
- Baseline controls – isolation, encryption, logging, tagging, approved regions and services – are captured as reusable infrastructure modules and policies, not as tribal knowledge.
- Approval flows and separation of duties are defined once and applied consistently to the stacks that represent customer environments.
- Drift detection and regular plan-only runs highlight when someone has changed a security-sensitive resource out of band, so you can reconcile or investigate.
Instead of asking “did we remember to follow the security checklist for this customer?”, you can ask more useful questions: “which policies apply to this stack?”, “when did they last run?”, and “where do we see drift across our tenant environments?”.
In the next section, you can use this fintech story as a running example to illustrate the four patterns: starting from reusable building blocks, through explicit environments and ownership, all the way to governance-as-code and automated feedback loops.
Putting the patterns together with Spacelift
Spacelift’s role in this story is to make those four patterns (building blocks, explicit environments, governance as code, feedback loops) something you can actually run every day, on top of the IaC tools you already use.
Spacelift is an infrastructure orchestration platform that supports Terraform, OpenTofu, Pulumi, CloudFormation, Terragrunt, Ansible, Kubernetes, and more, acting as a single control plane for multi-IaC environments.
Here’s how the patterns map:
- Blueprints for golden paths – You wrap your existing modules or templates into Blueprints – opinionated recipes for stacks like “standard production environment” or “developer sandbox”. A Blueprint defines which modules are used, which inputs are required, and which policies apply, so teams instantiate it instead of copy-pasting from old repos.
- Spaces for environments and ownership – Stacks live inside Spaces that mirror how your organization is structured: by team, business unit, region, or customer. Spaces give you a natural place to scope access (manage your own space, see production read-only) without encoding all of that in CI pipelines and docs.
- Dependencies and governance as code – You can model dependencies between stacks directly – networking before clusters, shared services before tenants – and have outputs flow between them. On top of that, policy-as-code (via OPA/Rego) expresses rules like who can approve what, which branches can deploy where, or which regions and tags are allowed.
- Continuous feedback and drift detection – Scheduled plans and drift detection highlight when reality diverges from what’s in Git, while policies keep enforcing security and tagging rules on every change. Cost estimation and security checks can run in the same workflows via integrations like Infracost and common scanning tools. Your existing CI/CD system keeps handling app builds and tests; Spacelift becomes the place where infrastructure as code is orchestrated, governed, and kept aligned over time.
Check out this video where we explore the issues related to managing IaC at scale:

Key points
When you zoom out, scaling infrastructure as code is about coordinating many teams and environments without losing control. Your IaC engine and CI/CD pipelines remain essential, but they don’t model stacks, environments, dependencies, governance, or ownership.
The teams that succeed tend to do the same four things: they standardize on reusable building blocks, define environments and ownership clearly, turn governance into code, and automate feedback loops around drift, health, and cost.
Spacelift’s job is to make that operating model practical by giving you opinionated building blocks (stacks, spaces, blueprints), policy-as-code, contexts, and automated drift detection and reconciliation on top of the tools you already use.
If you’re wrestling with these problems today, the easiest way to explore this model is to pick one service or environment and wrap it in Spacelift. You can create a free account today or book a demo with one of our engineers and see how Stacks, Spaces, and policies feel with your own code.
Solve your infrastructure challenges
Spacelift is a flexible orchestration solution for IaC development. It delivers enhanced collaboration, automation, and controls to simplify and accelerate the provisioning of cloud-based infrastructures.
