Going to AWS Summit London? 🇬🇧🇬🇧
The Most Flexible
IaC Management Platform
Spacelift is a sophisticated CI/CD platform for OpenTofu, Terraform, Terragrunt, CloudFormation, Pulumi, Kubernetes, and Ansible
Spacelift is a sophisticated CI/CD platform for OpenTofu, Terraform, Terragrunt, CloudFormation, Pulumi, Kubernetes, and Ansible
Book a demo













Trusted by the world’s best DevOps teams. Meet our customers
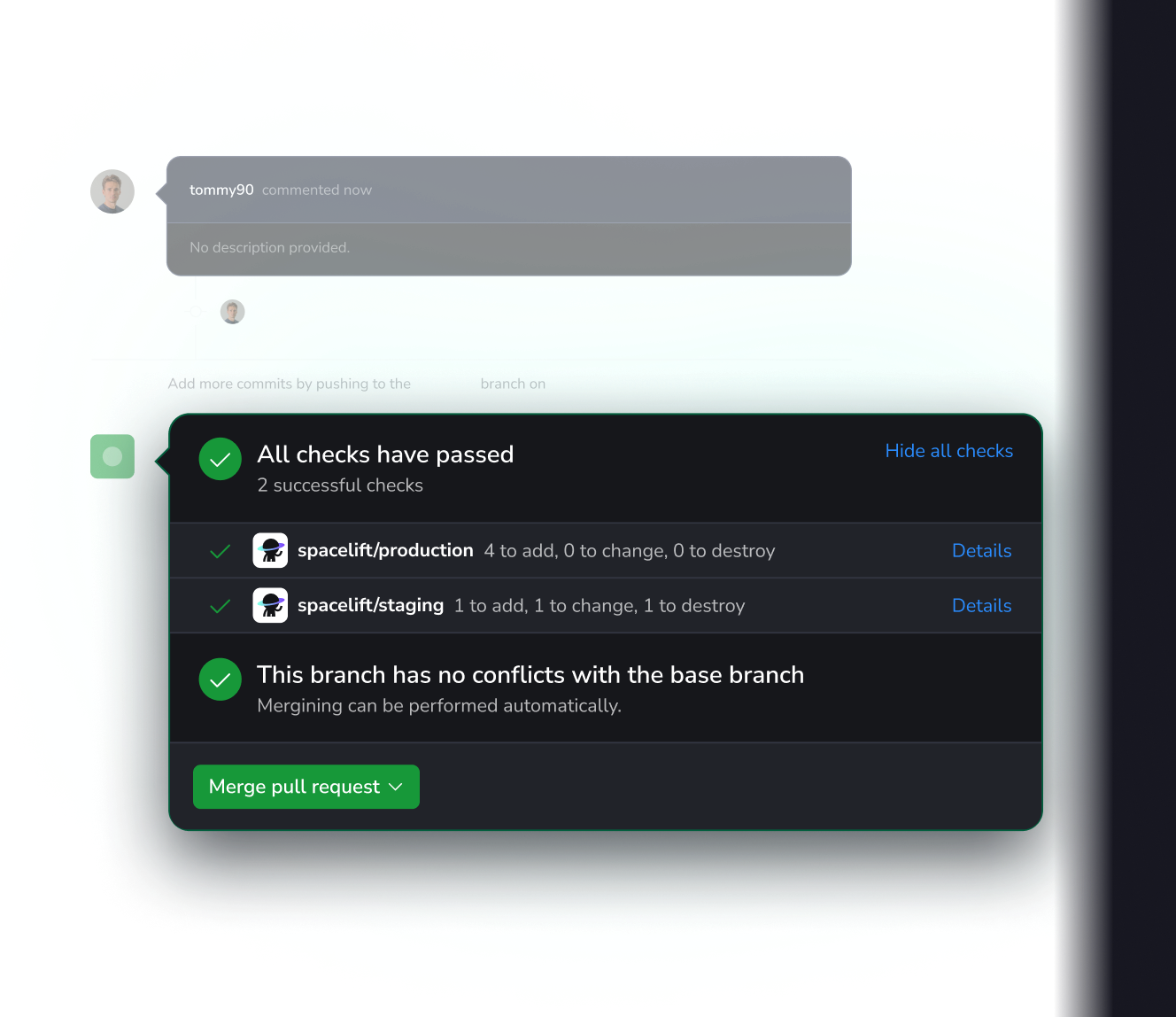
IaC is now multiplayer!
Stay in (git) flow
Our native Pull Request integrations support fully custom delivery workflows – Spacelift fits every team
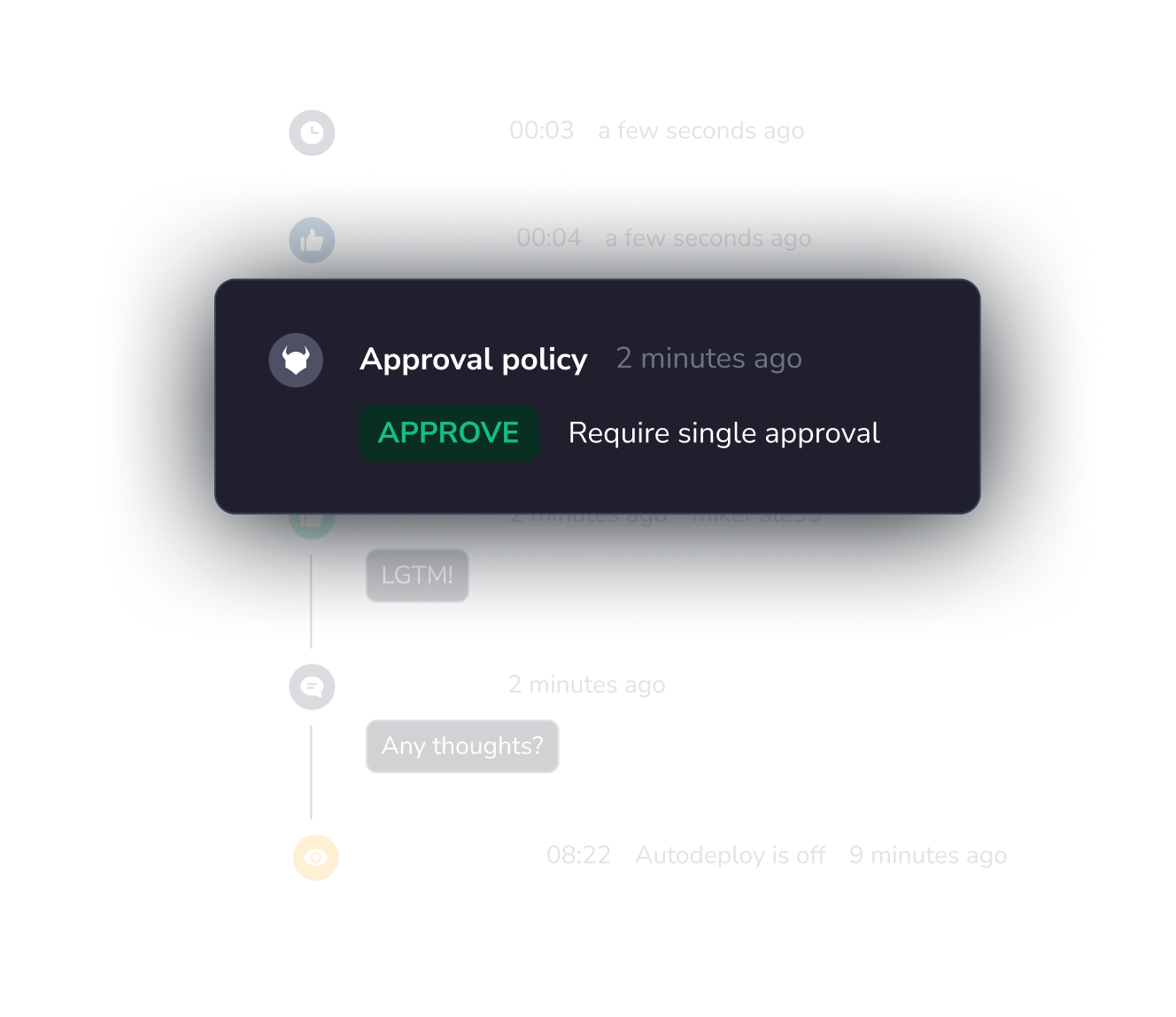
Every team working in the same space
Invite security and compliance teams to collaborate on and approve workflows and policies
Self-service infrastructure, unlocked
Automated workflows help everyone understand the impact of proposed changes, providing continuous delivery to the infrastructure your teams need

What’s going on with your most valuable infrastructure resources?
Visualize and navigate your infrastructure
Stay on top of everything you’re responsible for — visualize your resources, your provisioned, and deployed infrastructure
Insights for everyone
Get insight into application state, resource usage, cost, ownership, changes, access, associated runs, and more
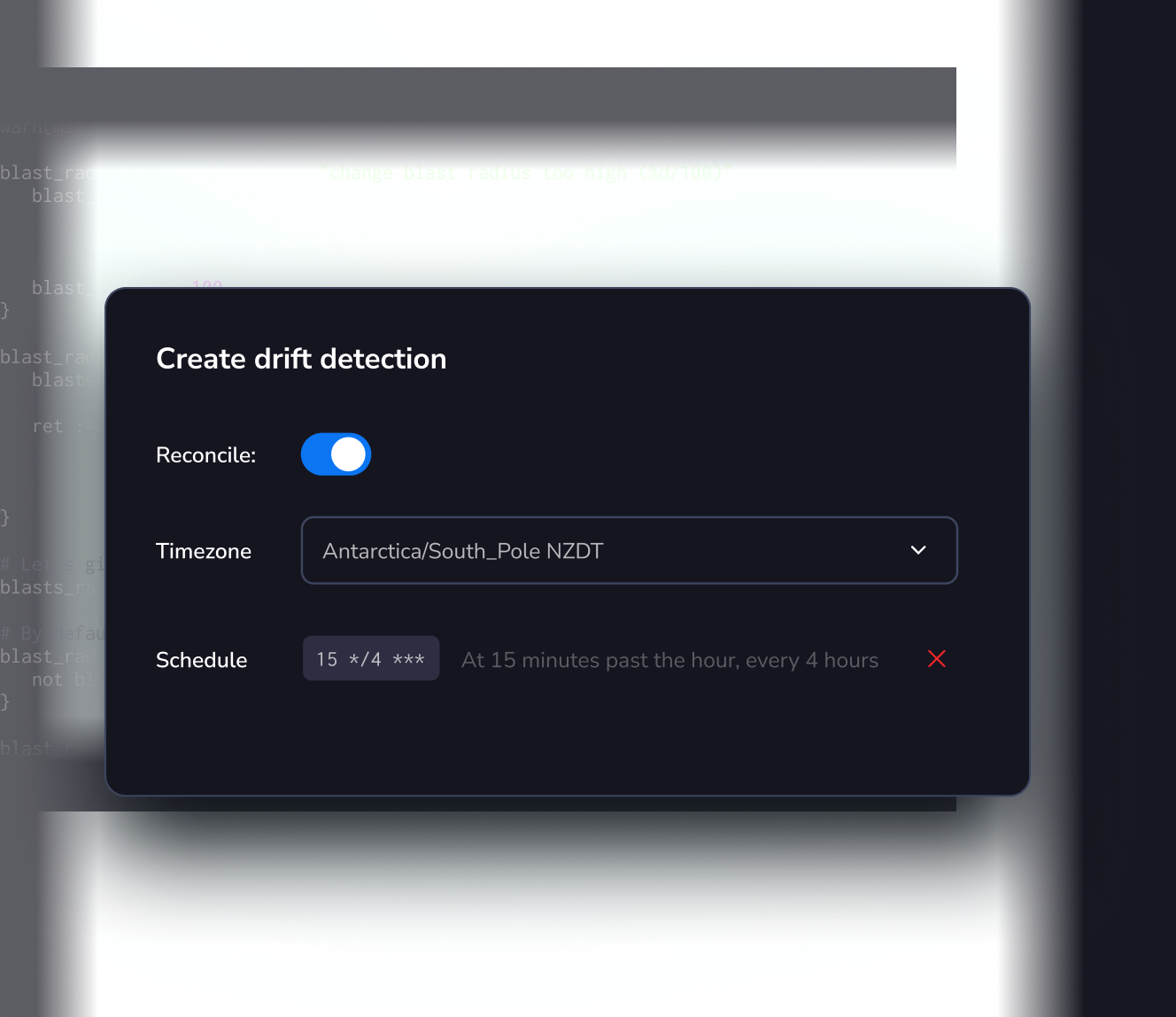
Driftless infrastructure – the way it should be
Automatic discovery and remediation of infrastructure drift. Just define your desired state, and get alerts with fixes anytime something goes askew


Keep everyone shipping fast
with precise guardrails that you control
Full control at full speed
Powered by the Open Policy Agent (OPA) you have full control to design the guardrails and gateways that empower development teams to safely, confidently, and easily deploy their applications to any IaC backend or cloud.


Ditch rigid tooling and start building exactly what you want
With Role-Based security policies, custom approval flows, and arbitrary git flow support, you can work exactly the way you want to, from straightforward pipelines to highly specialized complex event-driven workflows.
SaaS not an option?
Install Spacelift Self-Hosted on AWS
Concerned about governance, compliance, security, or regulation? Perhaps you operate in a restricted sector? With the Spacelift self-hosted solution, you bring all elements into your infrastructure, into an environment you control.
Built for your public cloud and cloud native infrastructure
All Cloud Platforms & Data Centers
Amazon Web Service
Google Cloud Platform
Microsoft Azure
Modern Infrastructure-as-Code Tools
OpenTofu
Terraform
Pulumi
AWS CloudFormation
Kubernetes
Ansible
Terragrunt
ARM
Coming Soon
Spacelift is powering platform teams
everywhere


"The ease of working with your team alone is a contrast I would highlight.”


“Our team includes developers distributed around the world across American, Australian, and European time zones. Spacelift has given us a lot of additional trust in each other. Because we have guardrails and defined workflows set up it allows us to have shared visibility into what we’re all doing.”


“With Spacelift, we can have an overarching collection of policies that govern when and how everything runs. This stuff is radically further ahead than the way 99% of companies use Terraform.”


"Spacelift has helped us set up a flexible and productive Infrastructure as Code environment. It makes the basics like setting up and iterating on plans simpler and quicker, which has allowed us to focus on larger engineering concerns. And when things in our infrastructure go wrong, that’s when Spacelift really shines!"
"The ease of working with your team alone is a contrast I would highlight.”
“Our team includes developers distributed around the world across American, Australian, and European time zones. Spacelift has given us a lot of additional trust in each other. Because we have guardrails and defined workflows set up it allows us to have shared visibility into what we’re all doing.”
Loved by Developers
We always try to listen to the needs of our users and we know it works!

Your policy workbench, different policies, and metadata available to them to make decisions is probably the most important feature you have to us. The selling point that I’m hammering is now we can make access/push/approval decisions more intelligently. We can add other teams as approvers to PRs based on what types of resources are being touched or what stack they are in. I’ve implemented a feature where the access policy on a stack allows you stack_write access to it based on a label affixed to the stack. This is all very cool and will move us forward.
- +

You guys move crazy fast… Things keep changing as I migrate 😃
That feature is awesome btw. Makes my life with the migration a lot easier.
- ❤️ 1
- +

I have to say, I love the tasks functionality.. makes debugging so much easier…
- +

Hello there 👋 Glad that Spacelift got picked to make our infrastructure-as-code runs better 🎉
- +

Indeed, we also have evaluated the Terraform Cloud Enterprise solution, however since our needs in terms of Infrastructure-as-Code and Continuous Deployment span beyond Terraform (e.g. SAM, potentially Ansible), we are leaning towards Spacelift as our global solution.
- 🙇🏼♂ 1
- +

Thank you for building Spacelift we’re really excited to be using it. Before spacelift all terraform applies had to be done locally from peoples mac books, this is such an improvement both for their productivity as well as the safety, security, and observability of those applies.
- ❤️ 14
- +

I love the platform y’all have built – it has made managing our infrastructure 10000000x easier
- ❤️ 10
- 😎 2
- 🙇🏼♂ 1
- +

Today, my devs did their first fully-unassisted app deployment to production. Over the past 2.5 years, we’ve trained towards GitOps and, step-by-step, turned over the automation to the devs. First, we got them comfortable with creating PRs with their version bumps, then we introduced them to Spacelift, teaching them how to navigate plans and use the Spacelift Github integration checks to validate the deploys as well as introducing them to TF plans, now available to them in SL. And today, one of our leads handled the whole process w/out DevOps intervention. Spacelift completed the circuit, by giving u a consistent and independent run environment, and a UI that makes the whole TF layer accessible to all users, putting the icing on the cake.
- 🙇🏼 6
- 🚀 6
- +

woot!
i’m stoked
SL is by far the best platform I have ever seen for this type of work.
and I’ve looked and tried a lot of solutions.
- 💪 10
- 🚀 7
- 😎 7
- +

Thank you for helping so quickly and diligently to debug our issue. This isn’t even the first time you all have hopped on quickly either but I really did want to call it out today that as a customer, I had a great experience, and I hope you can pass this on internally.
- 🙇🏼♂ 6
- 🚀 6
- 👨🏻🎨2
- +

Having a great time working on getting our setup refactored to work nicely with Spacelift. It’s my focus currently and I’m enjoying it.
- 🙏 8
- ❤️ 4
- +
Your policy workbench, different policies, and metadata available to them to make decisions is probably the most important feature you have to us. The selling point that I’m hammering is now we can make access/push/approval decisions more intelligently. We can add other teams as approvers to PRs based on what types of resources are being touched or what stack they are in. I’ve implemented a feature where the access policy on a stack allows you stack_write access to it based on a label affixed to the stack. This is all very cool and will move us forward.
- +
You guys move crazy fast… Things keep changing as I migrate 😃
That feature is awesome btw. Makes my life with the migration a lot easier.
- ❤️ 1
- +
I have to say, I love the tasks functionality.. makes debugging so much easier…
- +
Hello there 👋 Glad that Spacelift got picked to make our infrastructure-as-code runs better 🎉
- +
Indeed, we also have evaluated the Terraform Cloud Enterprise solution, however since our needs in terms of Infrastructure-as-Code and Continuous Deployment span beyond Terraform (e.g. SAM, potentially Ansible), we are leaning towards Spacelift as our global solution.
- 🙇🏼♂ 1
- +
Thank you for building Spacelift we’re really excited to be using it. Before spacelift all terraform applies had to be done locally from peoples mac books, this is such an improvement both for their productivity as well as the safety, security, and observability of those applies.
- ❤️ 14
- +
I love the platform y’all have built – it has made managing our infrastructure 10000000x easier
- ❤️ 10
- 😎 2
- 🙇🏼♂ 1
- +
Today, my devs did their first fully-unassisted app deployment to production. Over the past 2.5 years, we’ve trained towards GitOps and, step-by-step, turned over the automation to the devs. First, we got them comfortable with creating PRs with their version bumps, then we introduced them to Spacelift, teaching them how to navigate plans and use the Spacelift Github integration checks to validate the deploys as well as introducing them to TF plans, now available to them in SL. And today, one of our leads handled the whole process w/out DevOps intervention. Spacelift completed the circuit, by giving u a consistent and independent run environment, and a UI that makes the whole TF layer accessible to all users, putting the icing on the cake.
- 🙇🏼 6
- 🚀 6
- +
woot!
i’m stoked
SL is by far the best platform I have ever seen for this type of work.
and I’ve looked and tried a lot of solutions.
- 💪 10
- 🚀 7
- 😎 7
- +
Thank you for helping so quickly and diligently to debug our issue. This isn’t even the first time you all have hopped on quickly either but I really did want to call it out today that as a customer, I had a great experience, and I hope you can pass this on internally.
- 🙇🏼♂ 6
- 🚀 6
- 👨🏻🎨2
- +
Having a great time working on getting our setup refactored to work nicely with Spacelift. It’s my focus currently and I’m enjoying it.
- 🙏 8
- ❤️ 4
- +
IaC Was Just The Beginning
You need a collaborative environment for building the platform your teams need, with deep insight, full control, and unlimited flexibility. Build better with Spacelift.
Liftoff with Spacelift!